







BST树
即二叉搜索树:
1.所有非叶子结点至多拥有两个儿子(Left和Right);
2.所有结点存储一个关键字;
3.非叶子结点的左指针指向小于其关键字的子树,右指针指向大于其关键字的子树;
如:

BST树的搜索,从根结点开始,如果查询的关键字与结点的关键字相等,那么就命中;
否则,如果查询关键字比结点关键字小,就进入左儿子;如果比结点关键字大,就进入
右儿子;如果左儿子或右儿子的指针为空,则报告找不到相应的关键字;
如果BST树的所有非叶子结点的左右子树的结点数目均保持差不多(平衡),那么B树
的搜索性能逼近二分查找;但它比连续内存空间的二分查找的优点是,改变BST树结构
(插入与删除结点)不需要移动大段的内存数据,甚至通常是常数开销;
如:

但BST树在经过多次插入与删除后,有可能导致不同的结构:

右边也是一个BST树,但它的搜索性能已经是线性的了;同样的关键字集合有可能导致不同的
树结构索引;所以,使用BST树还要考虑尽可能让BST树保持左图的结构,和避免右图的结构,也就
是所谓的“平衡”问题;
RBT 红黑树
AVL是严格平衡树,因此在增加或者删除节点的时候,根据不同情况,旋转的次数比红黑树要多;
红黑是弱平衡的,用非严格的平衡来换取增删节点时候旋转次数的降低;
所以简单说,搜索的次数远远大于插入和删除,那么选择AVL树,如果搜索,插入删除次数几乎差不多,应该选择RB树。
红黑树上每个结点内含五个域,color,key,left,right,p。如果相应的指针域没有,则设为NIL。
一般的,红黑树,满足以下性质,即只有满足以下全部性质的树,我们才称之为红黑树:
1)每个结点要么是红的,要么是黑的。
2)根结点是黑的。
3)每个叶结点,即空结点(NIL)是黑的。
4)如果一个结点是红的,那么它的俩个儿子都是黑的。
5)对每个结点,从该结点到其子孙结点的所有路径上包含相同数目的黑结点。
下图所示,即是一颗红黑树:
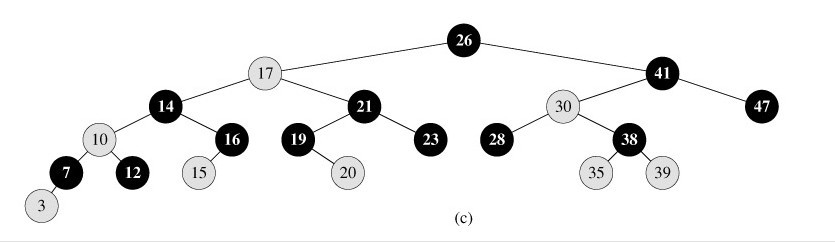
B树
B-tree(多路搜索树,并不是二叉的)是一种常见的数据结构。使用B-tree结构可以显著减少定位记录时所经历的中间过程,从而加快存取速度。按照翻译,B 通常认为是Balance的简称。这个数据结构一般用于数据库的索引,综合效率较高。
B树的特征:
1. 根节点至少有两个孩子
2. 每个非根节点有[ ,M]个孩;
3. 每个非根节点有[ -1,M-1]个关键字,并且以升序排列
4. key[i]和key[i+1]之间的孩子节点的值介于key[i]、key[i+1]之间
5. 所有的叶子节点都在同一层
例如下图就是一棵B树:
B树的优势在于多路查找,这便是优于红黑树的具体原因,我没有具体的公式在这列出来,但是,想一想,我每个结点有多个key,而红黑树每个结点有一个key,那么随着数据的不断增多,红黑树的高度不断增加,效率不断降低,而B树的高度一般都很低,为甚?我一个结点放上1024个key,满了才分裂一次!
说到这里就不得不提B树的分裂;B树为甚会分裂? 因为随着数据的增多,一个结点的key满了,为了保持B树的特性,就会产生分裂,就向红黑树和AVL树为了保持树的性质需要进行旋转一样!
正如前言所说的,这里不会对树的那些具体性质进行详细的说明,因为那样有些累,所以,为什么叫探索B树/B+树与MySQL数据库索引的关系,前提是你已经直到什么是B/B+树才有资格去更深的探索!
B+树
B-Tree有许多变种,其中最常见的是B+Tree,例如MySQL就普遍使用B+Tree实现其索引结构。
与B-Tree相比,B+Tree有以下不同点:
每个节点的指针上限为2d而不是2d+1。
内节点不存储data,只存储key;叶子节点不存储指针。
例如下图就是一棵B+树:

所有的key都会在叶子结点命中,我觉得这是B+树的最大的特点,当然,请记住这一特点,因为在后面的时候会用到;
细心的你发现,在叶子结点之间有一个指针相互连接,在现在的数据库中几乎都是这样设计的B+树,因为这样可以方便遍历;
而B+树相对于B树的话更容易确定一个区间的值,如果你了解B+树的性质的话会很快明白这一特性的;
下面是参考图:

MyISAM和InnoDB
MyISAM 和 InnoDB 是MySQL的两代搜索引擎;
区别在于,对于辅助索引的实现原理不一样,并且MyISAM是索引和文件分离的,而InnoDB不是;
一般以主键为索引的叫做主索引,而以其他键为索引的叫做辅助索引;
直接上MyISAM的实现原理,利用B+树实现,
由上图可以看出,col1是主键,而叶子结点存储的数据是一个地址,通过地址找到数据;
下面是辅助索引(和主索引不同的是辅助索引的key是可以重复的)

仔细对照MyISAM的这两张图,看看有什么主索引和辅助索引有什么区别?
下面看看InnoDB B+树实现

这是主索引,即利用主键构造的B+树;
注意,和MyISAM不同的是叶子结点的数据域保存的是全部数据;
下面在看辅助索引:

仔细看辅助索引和主索引的区别,辅助索引的叶子结点保存的是主键;这就是MyISAM和InnoDB最大的不同;
既然MyISAM和InnoDB是MySQL的两代引擎,肯定会有一个提升,而InnoDB是最新一代,那么它到底优在哪里?
试想,MyISAM和InnoDB都是以B+树为基础实现的,相对于B树的不同其实前面已经讲过,即数据域和结点分离;
而MyISAM更是索引和文件分离,B+树的叶子结点的数据域存放的是文件内容的地址,主索引和辅助索引的B+树都是如此,那么如果我改变了一个地址,是不是所有的索引树都得改变,正如前面我们讲的在磁盘上频繁的读写操作是效率很低的,而这块又不适用局部原理,因为逻辑上相邻的结点,物理上不一定相邻,那么这样就会造成效率上的降低;
于是乎,InnoDB就产生了,它让除了主索引以外的辅助索引的叶子结点的数据域都保存主键,先通过辅助索引找到主键,然后通过主键找到叶子结点的所有数据,听起来貌似很麻烦,遍历了两棵树,但是,这样如果有了修改的话,改变的只是主索引,其它辅助缩印都不用动,而且,数据库中的树的每一个结点的key可不是咱们给的那么少,试想如果一个结点有1024个key,那么高度为2的B+树都有1024*1024个key,所以一般树的高度都很低,所以,遍历树的消耗几乎忽略不计!
文章转自:https://blog.csdn.net/bitboss/article/details/53219945















 6168
6168

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









