







为什么需要降载
微服务集群中,调用链路错综复杂,作为服务提供者需要有一种保护自己的机制,防止调用方无脑调用压垮自己,保证自身服务的高可用。
最常见的保护机制莫过于限流机制,使用限流器的前提是必须知道自身的能够处理的最大并发数,一般在上线前通过压测来得到最大并发数,而且日常请求过程中每个接口的限流参数都不一样,同时系统一直在不断的迭代其处理能力往往也会随之变化,每次上线前都需要进行压测然后调整限流参数变得非常繁琐。
那么有没有一种更加简洁的限流机制能实现最大限度的自我保护呢?
什么是自适应降载
自适应降载能非常智能的保护服务自身,根据服务自身的系统负载动态判断是否需要降载。
设计目标:
-
保证系统不被拖垮。
-
在系统稳定的前提下,保持系统的吞吐量。
那么关键就在于如何衡量服务自身的负载呢?
判断高负载主要取决于两个指标:
-
cpu 是否过载。
-
最大并发数是否过载。
以上两点同时满足时则说明服务处于高负载状态,则进行自适应降载。
同时也应该注意高并发场景 cpu 负载、并发数往往波动比较大,从数据上我们称这种现象为毛刺,毛刺现象可能会导致系统一直在频繁的进行自动降载操作,所以我们一般获取一段时间内的指标均值来使指标更加平滑。实现上可以采用准确的记录一段时间内的指标然后直接计算平均值,但是需要占用一定的系统资源。
统计学上有一种算法:滑动平均(exponential moving average),可以用来估算变量的局部均值,使得变量的更新与历史一段时间的历史取值有关,无需记录所有的历史局部变量就可以实现平均值估算,非常节省宝贵的服务器资源。
滑动平均算法原理 参考这篇文章讲的非常清楚。
变量 V 在 t 时刻记为 Vt,θt 为变量 V 在 t 时刻的取值,即在不使用滑动平均模型时 Vt=θt,在使用滑动平均模型后,Vt 的更新公式如下:
Vt=β⋅Vt−1+(1−β)⋅θt
-
β = 0 时 Vt = θt
-
β = 0.9 时,大致相当于过去 10 个 θt 值的平均
-
β = 0.99 时,大致相当于过去 100 个 θt 值的平均
代码实现
接下来我们来看下 go-zero 自适应降载的代码实现。
core/load/adaptiveshedder.go
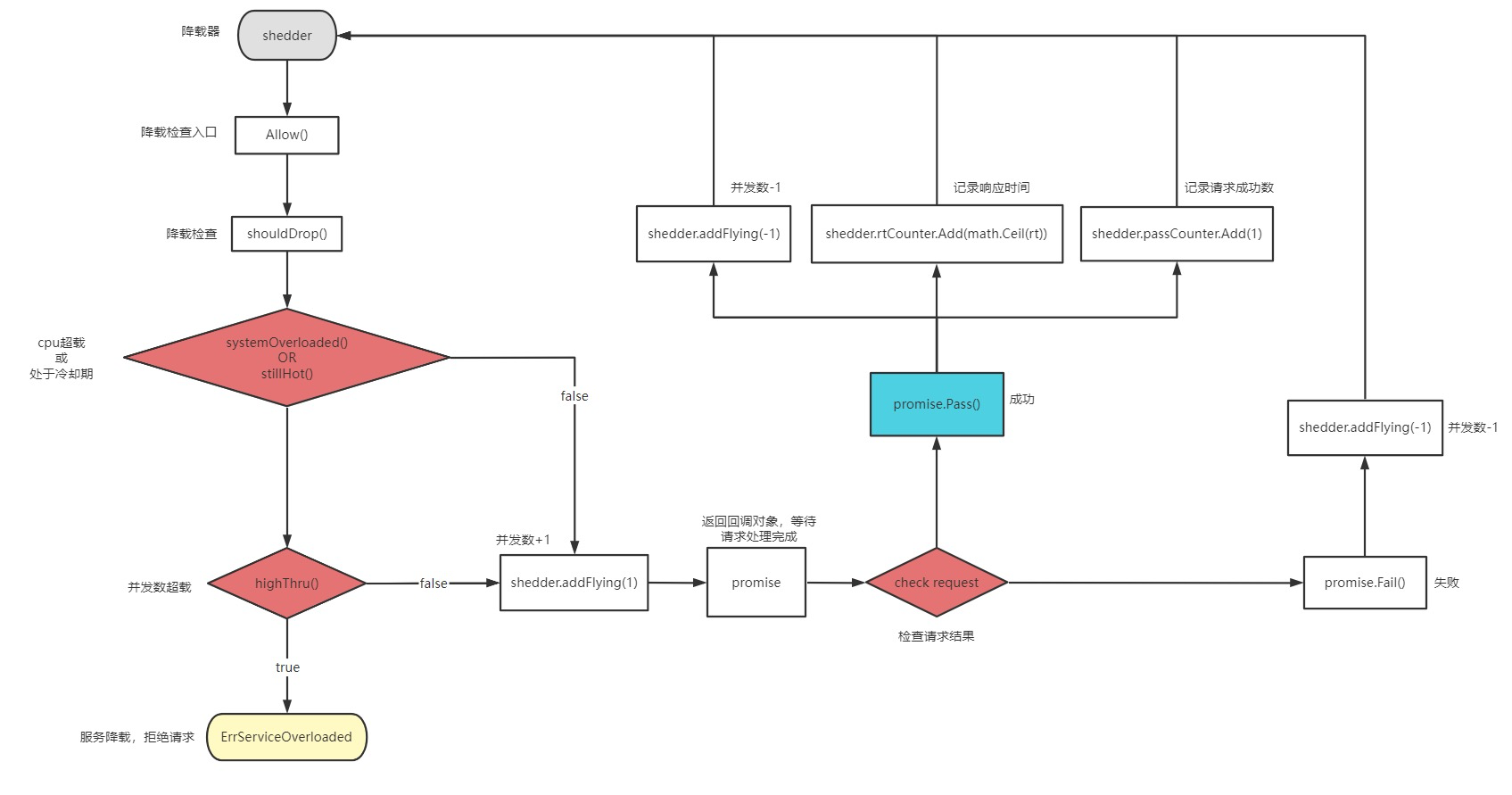
自适应降载接口定义:
// 回调函数
Promise interface {
// 请求成功时回调此函数
Pass()
// 请求失败时回调此函数
Fail()
}
// 降载接口定义
Shedder interface {
// 降载检查
// 1. 允许调用,需手动执行 Promise.accept()/reject()上报实际执行任务结构
// 2. 拒绝调用,将会直接返回err:服务过载错误 ErrServiceOverloaded
Allow() (Promise, error)
}
接口定义非常精简意味使用起来其实非常简单,对外暴露一个`Allow()(Promise,error)。
go-zero 使用示例:
业务中只需调该方法判断是否降载,如果被降载则直接结束流程,否则执行业务最后使用返回值 Promise 根据执行结果回调结果即可。
func UnarySheddingInterceptor(shedder load.Shedder, metrics *stat.Metrics) grpc.UnaryServerInterceptor {
ensureSheddingStat()
return func(ctx context.Context, req interface{}, info *grpc.UnaryServerInfo,
handler grpc.UnaryHandler) (val interface{}, err error) {
sheddingStat 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 220
220











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









