







转载自 https://blog.csdn.net/xuluohongshang/article/details/78838695
1. single shot 和muti shot
前者是指gallery中每个人的图像为一张(N=1),而后者是指gallery中每个人的图像为N>1张图像,同样的Rank-1下,一般N越大,得到的识别率越高。
2.gallery、probe和CMC
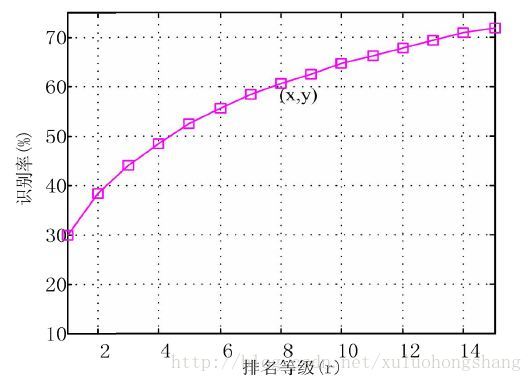
gallery是候选行人库,probe是待查询输入,也叫查询图像(query),CMC是一种reid的性能评价方法,即Cumulative Match Characteristic。CMC将再识别问题看成是一种排序问题,CMC 曲线的具体含义是指在候选行人库(gallery)中检索待查询(probe)的行人,前 r 个检索结果中包含正确匹配结果的比率。其中,第 1 匹配率 r=1 指标Rank-1反映了最匹配候选目标刚好为待查询图片目标的概率,即该指标为真正的识别能力,因此很重要。但是当 r 值很小但大于1时,由于可以通过人眼进行辅助识别查找目标,因此也很有现实意义,如第 5 匹配率 r=5 指标反映前 5 个匹配候选目标中存在待查询图片目标的概率,如下图:横坐标表示排名等级,纵坐标表示再识别的准确率。
3.可考虑的特征优化方法及优缺点:
颜色信息:
- 颜色直方图 ,RGB 、HSV和LAB颜色空间。在 HSV 颜色空间中建立的颜色直方图受到光照变化的影响最小,而 LAB 颜色空间中,由于其亮度和色度通道是相互分开的,因此该颜色空间对不同帧中的光照变化也有一定的鲁棒性。颜色直方图存在对光照变化不够鲁棒和不包含空间信息等缺点。颜色空间中那些对光照变化比较敏感的成分应都被去除或者经过归一化处理,如直方图均衡化可以提高图像中暗区的亮度,增加这些区域的细节信息,从而提高整幅图像的对比度。在 HSV 颜色模型,一般对V通道直方图均衡
- 包含像素点几何信息的颜色直方图
纹理信息:
- 重复出现的结构块(RHSP)特征,特征对位姿和旋转变化具有不变性,但计算该特征的一个前提是行人图像的分辨率至少达到中等分辨率,否则无法计算得到该特征
显著性信息:
一般是基于块显著特征匹配。涉及水平方向的块匹配来对齐,查询图像与候选行人图像库中每一幅图像之间都实现了特征块的对齐,可减少了由于视角、位姿变化而引起的空间错位。匹配块的显著性外观特征空间分布不一致。
空间信息:
- SDALF基于对称和非对称轴的区域划分方法将人体分为头部、躯干和下肢三个部分,同时根据人体外观的非对称性利用两个非对称的轴将人体在垂直方向划分成三个部分,该方法使得离对称轴近的像素点具有相对较高的权值,从而增强了算法关于位姿变化的鲁棒性,取得了较好的行人再识别结果
- 共生矩阵也常常被用来提取纹理特征
信息融合方法:
- 加权的颜色直方图+最大稳定颜色区域(MSCR)+重复出现的结构块(Recurrent High-structured Patches,RHSP)特征
深度信息:
- CNN
4.行人再识别算法的分类
基于特征设计的方法:
主要包括颜色、纹理、边缘、形状、全局特征、区域特征和基于块的特征等基本特征
基于机器学习的方法:
- 基于判别分析的机器学习:
尝试训练一种分类器,训练时,输入一般为一对样本,即对应的是否为同一人的标记。是利用分类信息来学习更具区分力的特征模型 - 基于度量矩阵的机器学习:
基于度量矩阵的机器学习则是在特征空间中寻找并优化描述两个摄像机视场之间的变换矩阵。
相对距离比较(Relative Distance Comparison,RDC)模型
LMNN和LMNN-R
信息论度量学习(ITML:Information Theoretic Metric Learning)方法
KISSME 度量学习算法
总结:很难学习一个通用的度量矩阵来区分不同的行人,同时也很难用一个通用的矩阵来抑制各种相机之间的不同变化类型,多个度量矩阵+迁移学习是趋势。
5.reID训练的loss类别:

6.其他网友总结:
作者:小赖sqLai
链接:https://www.zhihu.com/question/46943328/answer/175243925
见今年AAAI的那篇multi-task的思路。用softmax做classification,contrastive loss或者image pair融合做identification,triplet loss做ranking,这个几乎已经是标准架构了,无非在里面再做细致调整。其他的就是各种trick了,图像增强,数据扩充,增加标签语意监督,以及各种各样的reranking技巧。
总结一下常见loss:contrastive loss,triplet loss,center loss,coupled clusters loss,structured loss,quadruplet loss,以及对应的改进版,基本已经差不多了,而且都是行人,车辆,人脸,实例等检索识别任务通用的损失函数。
另外:
image pairs融合这一部分有相当多的工作可以考虑,卷积层融合,还是全连接相减,依然还有不少东西可以挖。
多标签学习,是单纯的大量softmax呢,还是多重交叉熵,也有一些东西可以做。
part model,包括单纯切割,或者是用pose定位切块,也是能显著提升性能的。
其他的其实单从性能上的话,transfer learning,cross domain,gan模型数据扩增,以及reranking。
基本上以上这些工作都是对实际性能提升会有一些帮助的,基本上我复现之后,都能在我原模型基础上好2到5个点之间。















 8754
8754

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









