







编码格式的查看与修改
(1)文件编码格式的查看。在Unix/Linux下,文件编码格式的查看通过file (-i)命令完成。可以观察到,使用vi、gedit、touch创建的文件在文件内容仅包含ASCII码时最初都是ASCII编码格式,反之则为UTF格式。在Windows下查看文件编码则比较麻烦,需要借助文本编辑器的功能,以记事本为例,可以通过“另存为”看到编码格式,当然不排除其他的文本编辑器能提供更为高效的编码格式显示功能。可以观察到Windows下文件默认编码格式为ANSI格式。
[vincent@localhost 桌面]$ file -i ansi.cpp
ansi.cpp: text/x-c; charset=utf-8 如果需要修改文件编码格式,Unix/Linux下可以通过iconv (-f -t -o --verbose)命令。Windows下可以通过文本编辑器进行修改。
[vincent@localhost 桌面]$ iconv ansi.cpp -f UTF-8 -t UTF-16 -o ansi16.cpp --verbose
ansi.cpp:(2)系统编码格式的查看。在Unix/linux下,通过locale查看系统编码格式。Windows下通过chcp命令查看系统编码格式,其中936代表GBK简体中文,1252代表ANSI,932代表日文。目前Windows内核已经支持Unicode字符集,但是由于现有大量程序和文档都采用了特殊语言的编码,例如GBK,Windows就使用代码页(Code Page)来适应各国家和地区。
[vincent@localhost 桌面]$ locale
LANG=zh_CN.UTF-8
LC_CTYPE="zh_CN.UTF-8"
LC_NUMERIC="zh_CN.UTF-8"
LC_TIME="zh_CN.UTF-8"
LC_COLLATE="zh_CN.UTF-8"
LC_MONETARY="zh_CN.UTF-8"
LC_MESSAGES="zh_CN.UTF-8"
LC_PAPER="zh_CN.UTF-8"
LC_NAME="zh_CN.UTF-8"
LC_ADDRESS="zh_CN.UTF-8"
LC_TELEPHONE="zh_CN.UTF-8"
LC_MEASUREMENT="zh_CN.UTF-8"
LC_IDENTIFICATION="zh_CN.UTF-8"
LC_ALL=C:\Users\Administrator>chcp
Active code page: 936编码格式的说明
在此主要就几种常见的编码格式进行介绍,网上都有相关资料,读者可以自行搜索。(1)ASCII与ISO-8859。相信大多数码过代码的朋友对这种编码形式都不陌生,因为早在学习C语言的阶段就都接触过“阿斯克码”。我特意去百度了一下,它的全称是“美国信息交换标准代码”,于1967年定案(比C语言出现还早了3年)。ASCII码占用一个字节,所以一共可以表示256种字符。但是实际上最初的ASCII码仅包含128个字符,最高位并未使用,所以对于欧洲国家来说,一些符号就无法使用,例如英镑符号。所以出现了ISO-8859(现在已经更新了好几版了),ISO-8859是对ASCII码的补充,且后128个字符可以被称为扩展ASCII码。但是,这256个字符远远不足以表达各种特殊字符。

(2)GB-2312与GBK。GB-2312即为简体中文,但是不能表达古汉字等符号,所以出现了GBK。在该编码形式中,英文字符固定占用一个字节,汉字固定占用两个字节。需要注意的是GB系列与ASCII码是兼容的。
(3)Unicode。Unicode有个很霸气的名字,叫“万国码”,旨在表示囊括全世界所有的符号系统。UCS-2表示16位的Unicode码,即所有字符用固定长度2字节来表示,能表示65535个字符,中文字符大约有2万多个;UCS-4表示32位的Unicode码,即所有字符用固定长度4字节来表示。UTF是UCS的转换形式,其区别如下表示:
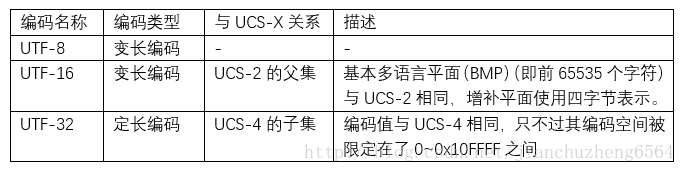
关于BMP?
Unicode 目前规划的总空间是17个平面(平面0至16),0x0000 至0x10FFFF。每个平面有 65536 个码点。平面0(BMP)包含 65536 个码点(即0x0000 至 0xFFFF)。BMP 的字符是 Unicode 中最基础和最常用的一部分,以UTF-16 编码时使用2字节,以 UTF-8 编码时使用1至3字节。超出BMP 的字符以 UTF-16 或 UTF-8 编码都需要4字节。
(4)UTF-8。本来UTF-8应该是归在(3)中进行介绍的,但是UTF-8作为网络传输界的大佬,在此特别划出一栏进行介绍。由上所述,当编码大小为定值时或者为了考虑一些不常用的字符,会造成存储不必要的浪费。所以UTF-8作为变长编码而存在,与ASCII码兼容,使用1~4字节的存储空间(英文都为1字节,汉字都为3个字节)。
关于BOM?
UTF-8以字节为编码单元,没有字节序的问题。UTF-16以两个字节为编码单元,在解释一个UTF-16文本前,首先要弄清楚每个编码单元的字节序。例如“奎”的Unicode编码是594E,“乙”的Unicode编码是4E59。如果我们收到UTF-16字节流“594E”,那么这是“奎”还是“乙”?
Unicode规范中推荐的标记字节顺序的方法是BOM。BOM不是“Bill Of Material”的BOM表,而是Byte Order Mark。BOM是一个有点小聪明的想法:
在UCS编码中有一个叫做"ZERO WIDTH NO-BREAK SPACE"的字符,它的编码是FEFF。而FFFE在UCS中是不存在的字符,所以不应该出现在实际传输中。UCS规范建议我们在传输字节流前,先传输字符"ZERO WIDTH NO-BREAK SPACE"。这样如果接收者收到FEFF,就表明这个字节流是Big-Endian的;如果收到FFFE,就表明这个字节流是Little-Endian的。因此字符"ZERO WIDTH NO-BREAK SPACE"又被称作BOM。
UTF-8不需要BOM来表明字节顺序,但可以用BOM来表明编码方式。字符"ZERO WIDTH NO-BREAK SPACE"的UTF-8编码是EF BB BF。所以如果接收者收到以EF BB BF开头的字节流,就知道这是UTF-8编码了。Windows就是使用BOM来标记文本文件的编码方式的。
编程与编码
接下来我们看下在编程中的编码问题。我在网上看到一种说法,将程序整个生产过程所处的编码环境分为了三个部分:源字符集(源码文件的字符集)、执行字符集(编译时使用的字符集)、运行字符集(程序运行环境使用的字符集)。我在网上搜了一圈也没找到类似说法,所以猜测可能是一家之言,但是这种说法感觉也有些道理。源字符集取决于你的文件保存形式,运行字符集取决于你的系统环境,因此以下就执行字符集进行分析:
首先是Java,因为我Java接触不多。所以以下资料也是百度搜索到的,Java的char与C/C++不同,占用两个字节,并且Java编译器使用Unicode编码(应该是UCS-2),所以说Java的一个char变量可以存储一个中文字。然后是Windows下的C++,通过程序可以发现一个字符实际占用了2个字节,额外需要一个字节存储/0,查看编码发现使用的是GB-2312编码,所以编译器应该是ANSI编码方式。
输入:中国
编码:d6 d0 b9 fa 0
字节:5在Linux的C++中,通过程序发现一个字符实际占用3个字节,同样额外需要一个字节存储/0,gcc/g++使用的是UTF-8编码形式。
输入:中国
编码:e4 b8 ad e5 9b bd 0
字节:7
参考资料:
[1] 点击打开链接
[2] 点击打开链接
[3] 点击打开链接














 149
149











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









