







package com.test.brouse;
import java.io.IOException;
import java.io.InputStream;
import java.net.MalformedURLException;
import java.net.URL;
public class Html {
/**
* @param args
* @throws IOException
* @throws MalformedURLException
*/
public static void main(String[] args) throws MalformedURLException, IOException {
// TODO Auto-generated method stub
InputStream in=(new URL("http://www.baidu.com")).openStream();
int c=-1;
while((c=in.read())!=-1)
{
System.out.write(c);
}
}
}输出结果为
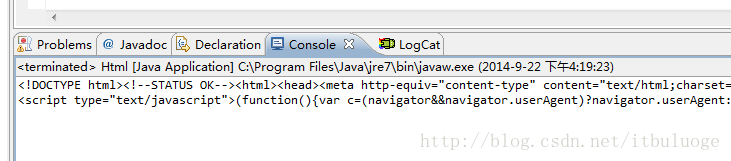














 162
162











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









