






转载自:点击打开链接
本文为笔者学习“VERY DEEP CONVOLUTIONAL NETWORKS
FOR LARGE-SCALE IMAGE RECOGNITION”的笔记记录。
VGG论文下载链接:VERY DEEP CONVOLUTIONAL NETWORKS
FOR LARGE-SCALE IMAGE RECOGNITION
为什么选择3 * 3卷积核?
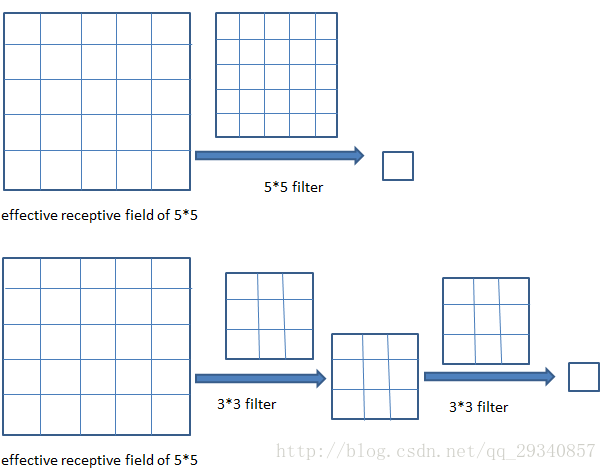
两层3 * 3卷积操作的有效区域是5 * 5(所有filter的stride=1,pad=0),示意图如下:
论文原文:It is easy to see that a stack of two 3×3 conv. layers (without spatial pooling in between) has an effective receptive field of 5×5;
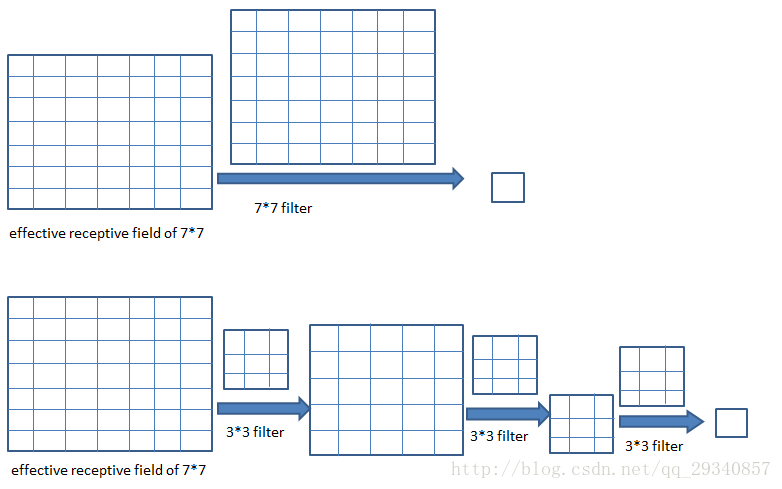
三层3 * 3卷积核操作的有效区域是7 * 7(所有filter的stride=1,pad=0),示意图如下:
论文原文:
three such layers have a 7 × 7 effective receptive field.
选用3*3卷积核的优点:
- 使网络结构更深,学习到的特征更多,结果更具有判别性(discriminative)
- 三层3*3的卷积核比一层7*7的卷积核所需要的参数更少(假设卷积前后的通道数均为C):
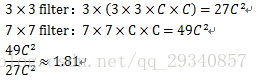
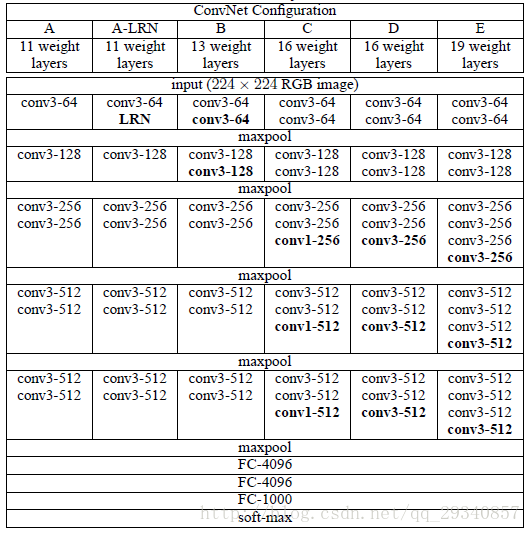
CONVNET CONFIGURATIONS
1.网络结构
其中D结构Classification和Location的效果综合最优,故主要分析D网络结构。
参数和内存占用分析(来源[斯坦福大学CS231课程]课件截图):
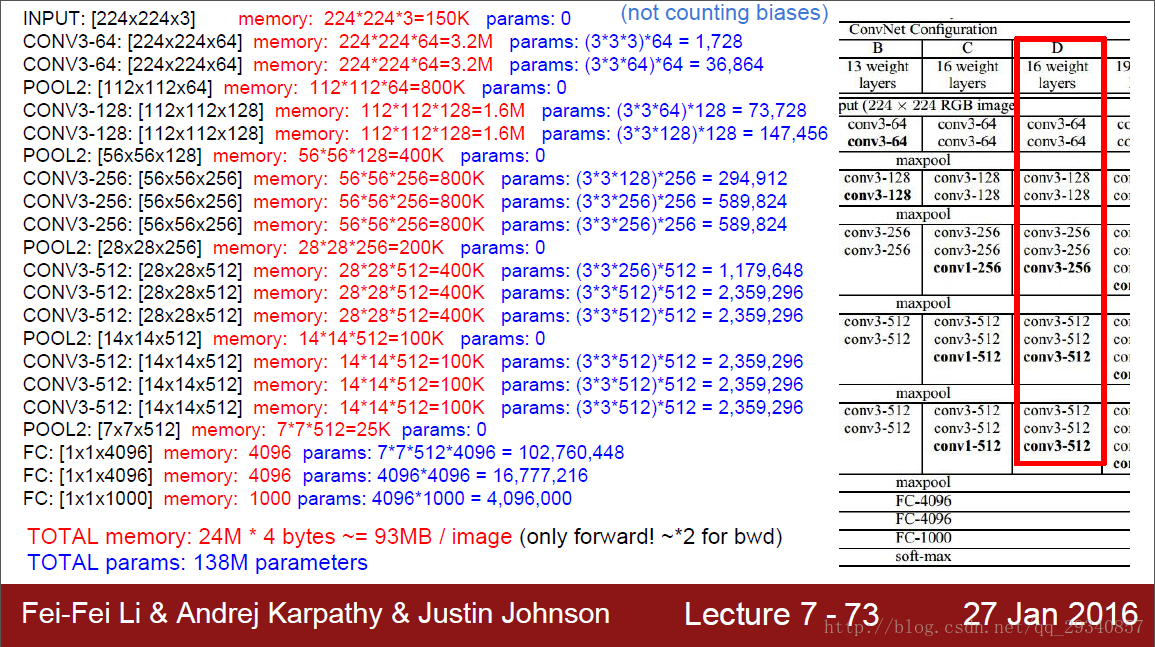
由分析可以看出:
- 前面部分的卷积层占用大量内存
- 后面的三层全连接层占用了大量的参数
2.超参数设置
- batch_size:256
- momentum rate:0.9
- L2 regularization rate:0.0005
- dropout(只对第一第二全连接层使用):0.5
- 初始化 learning rate:0.01
learning rate的补充:论文作者使用的是A结构的网络训练的参数初始化前四层卷积层和后三层全连接层,但是截至发稿时,论文作者采用了Xaiver Initialization方法,因此本笔记的learning rate针对XaiverInitialization,无需对A结构pre-training。
momentum update:可以参见博客 Lecture 6:Training Neural Networks,Part 2 ,介绍和比较各种常见的优化算法














 2821
2821











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









