







一、说明
很多情况下 LLM 知识库可以让 Agent 从中定位到准确的信息,从而准确地回答问题。在一些特定领域,比如客服、检索工具等有应用。
传统的客服机器人往往是基于关键词检索的,当用户输入了关键词以外的问题,机器人就无法解决。知识库正是为了解决这样一个问题,能够做到语义级别上的检索,降低人工的负担。
请记住知识库的核心是检索而非 LLM,是 LLM 增强了输出的过程,但真正的需求仍然是生成答案
什么是 embedding?
” Embedding “是一种将离散型变量(如单词、句子或者整个文档)转化为连续的向量表示的技术。
直白地说,在我们将自然语言处理为数据时会将文本转为向量,这个过程被称作 embedding。语义相似的文本的向量会位置相近,语义相反的文本的向量位置相反。LLM 使用这样的数据做训练,预测出后续的向量,从而生成文本。
知识点
- Chatflow 的基础使用
- 知识库、外部知识库的使用
- embedding 的概念
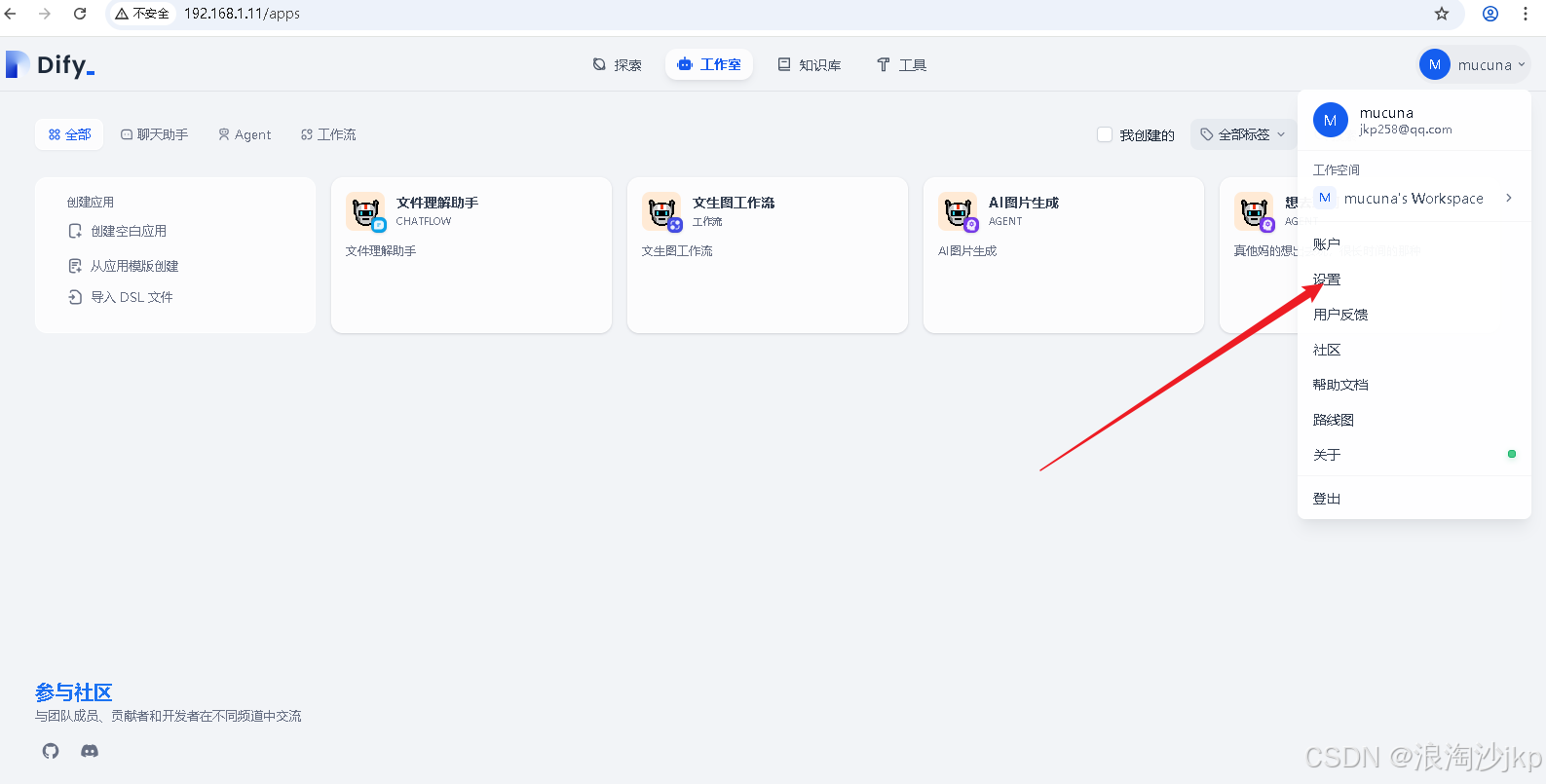
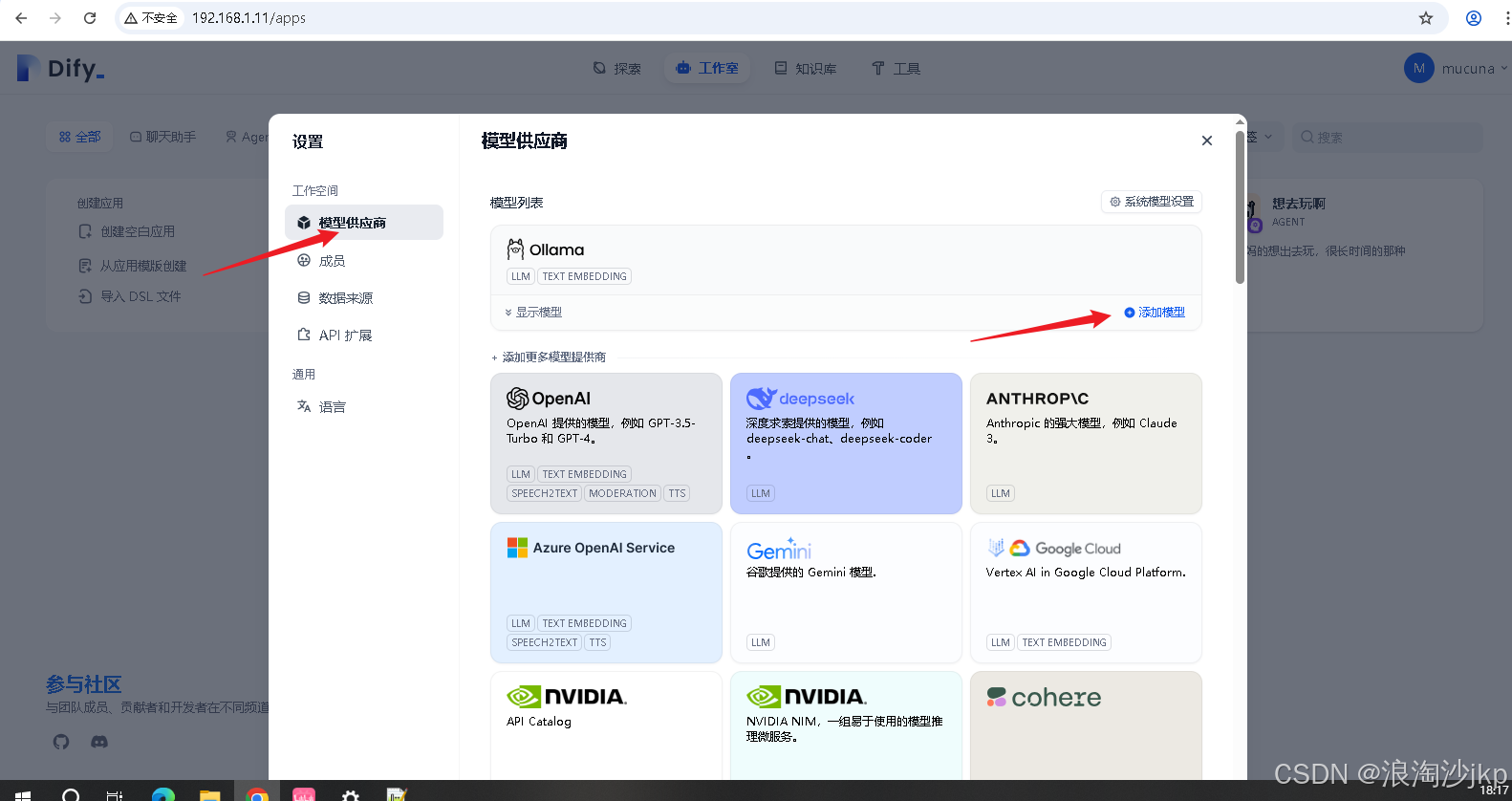
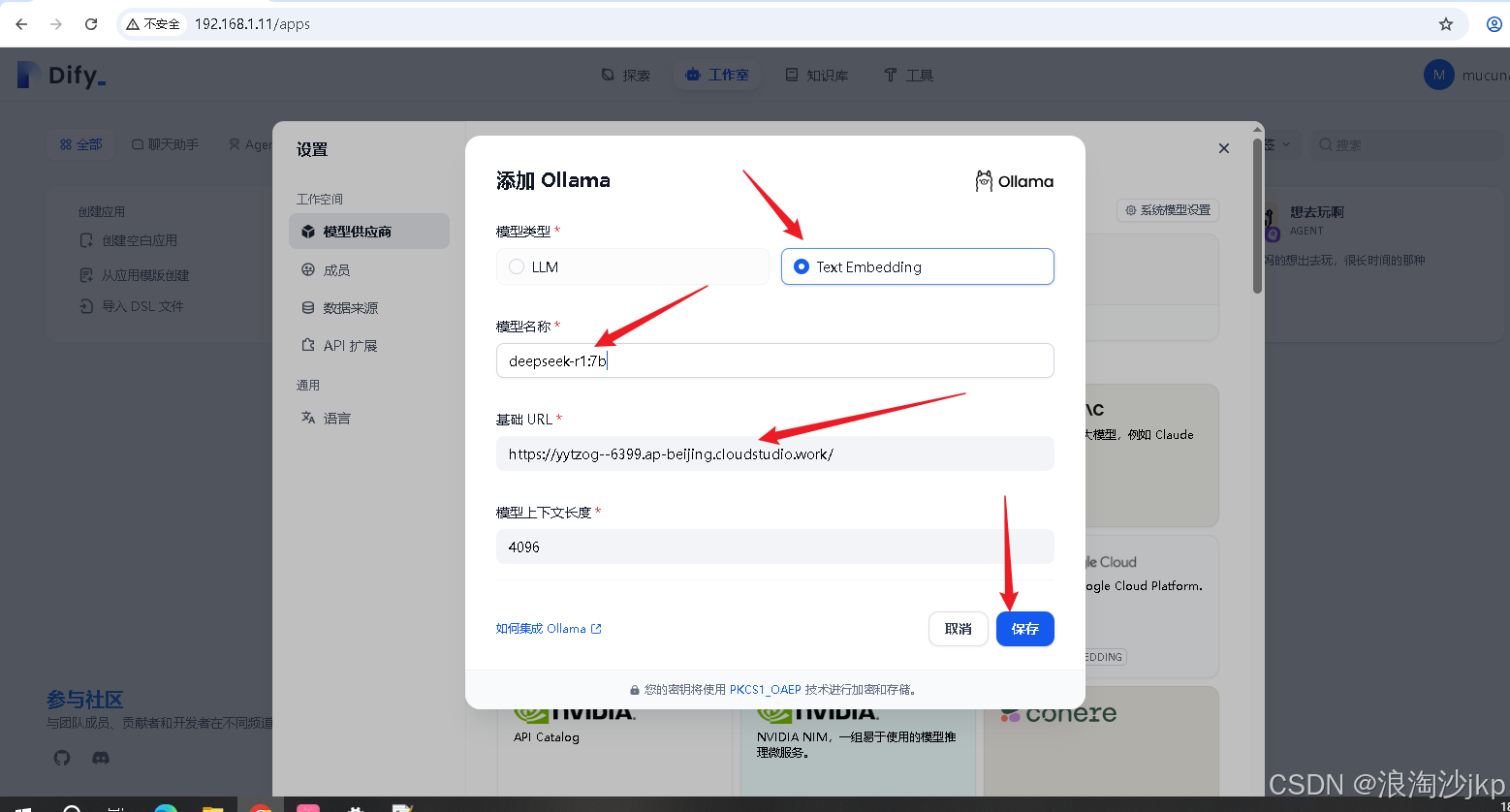
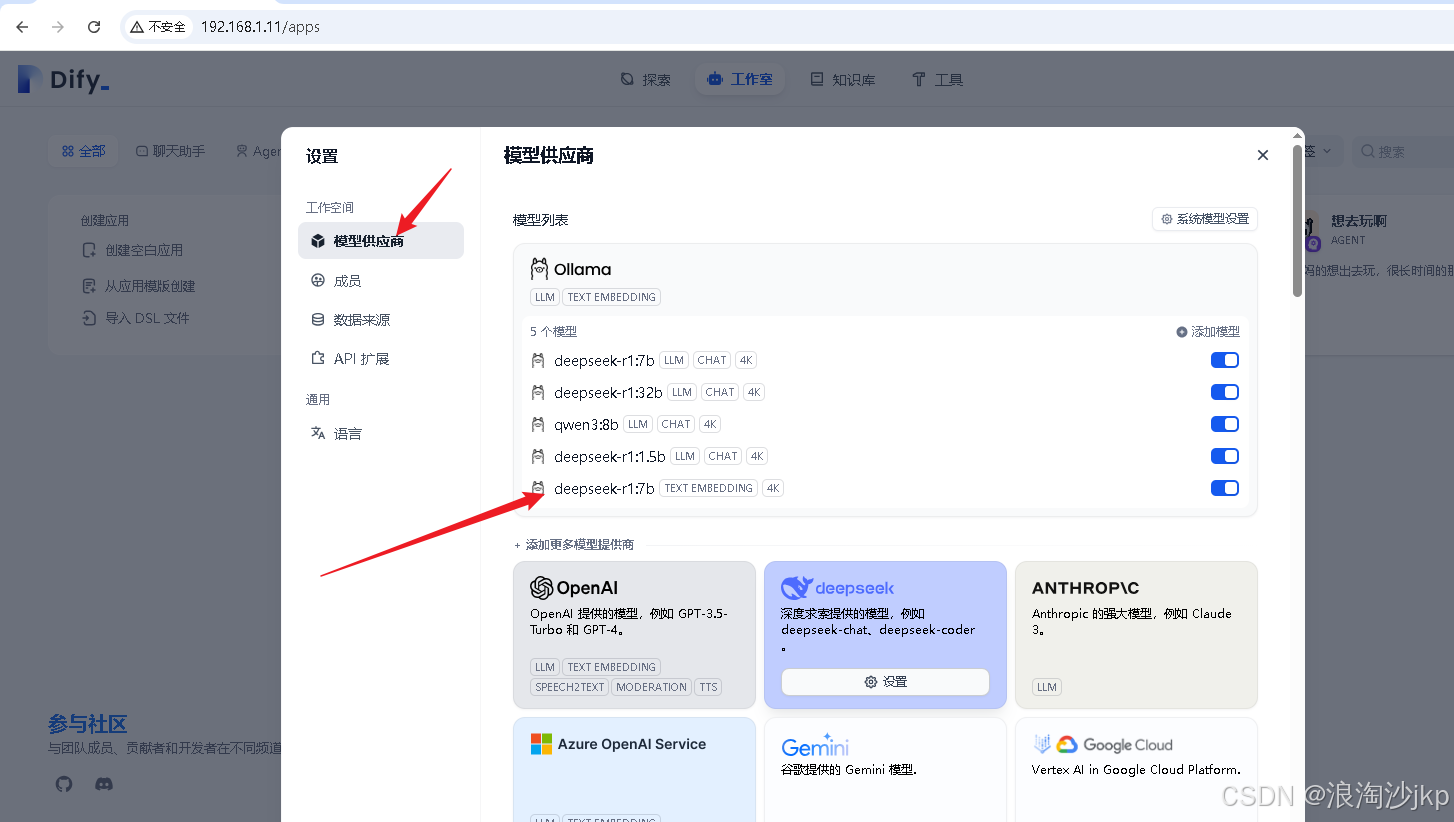
二、添加Embedding模型
三、创建知识库
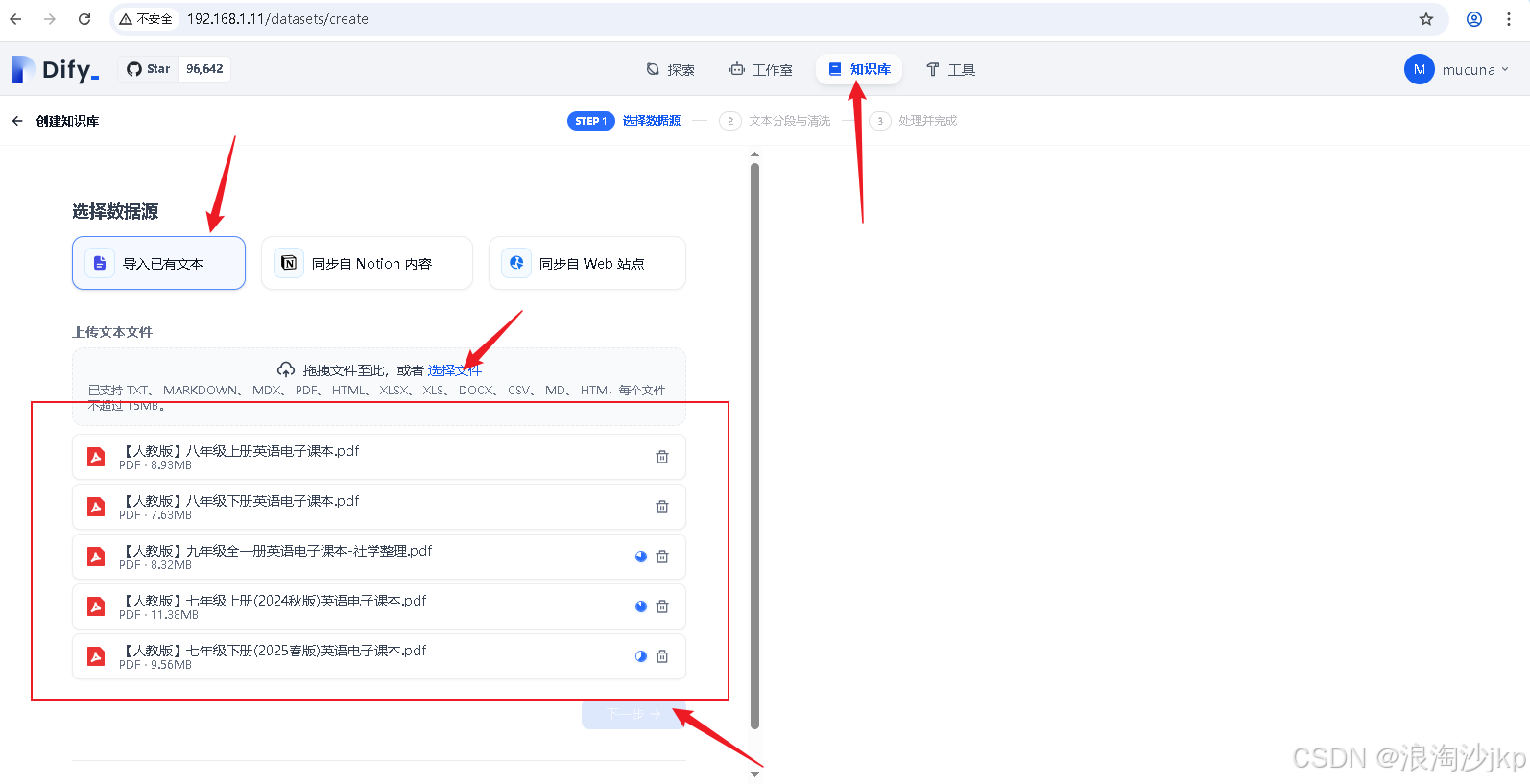
可以看到右侧有分段预览。Dify 会根据文本内容的不同自动将文章切分为许多个段落。你也可以在自定义中设置其他的切分规则。
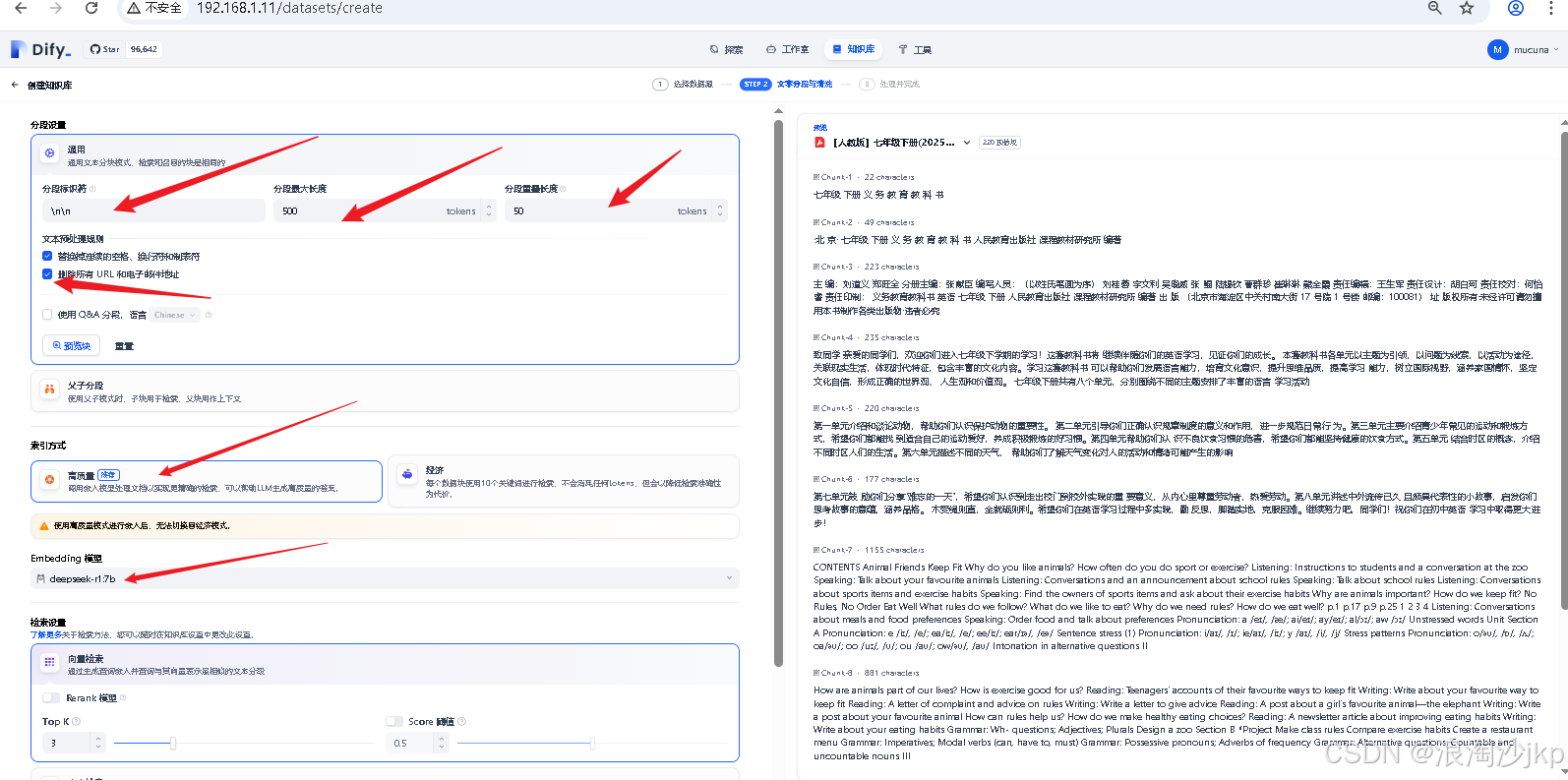
索引方式
通常情况下选择 高质量,但是需要额外消耗 token。选择 经济 无需消耗 token。
在社区版 Dify 里有采用 Q&A 分段模式,选择对应的语言可以将文本内容整理为问答格式,需要额外消耗 token。
Embedding 模型请在使用前查阅模型供应商的使用文档、模型定价等信息。
不同的 embedding 模型适用场景不同。例如 Cohere 的
检索设置embed-english适用于英语文档,embed-multilingual适用于多语言文档。Dify 提供了向量检索、全文检索、混合检索三种检索功能,其中常用的检索是混合检索。
混合检索中可以设置权重或者使用重新排序(Rerank)模型。使用权重设置时,可以设置检索更侧重语义还是关键词,例如下图中语义占 70% 的权重,关键词占30%的权重。
点击最下面的保存并处理
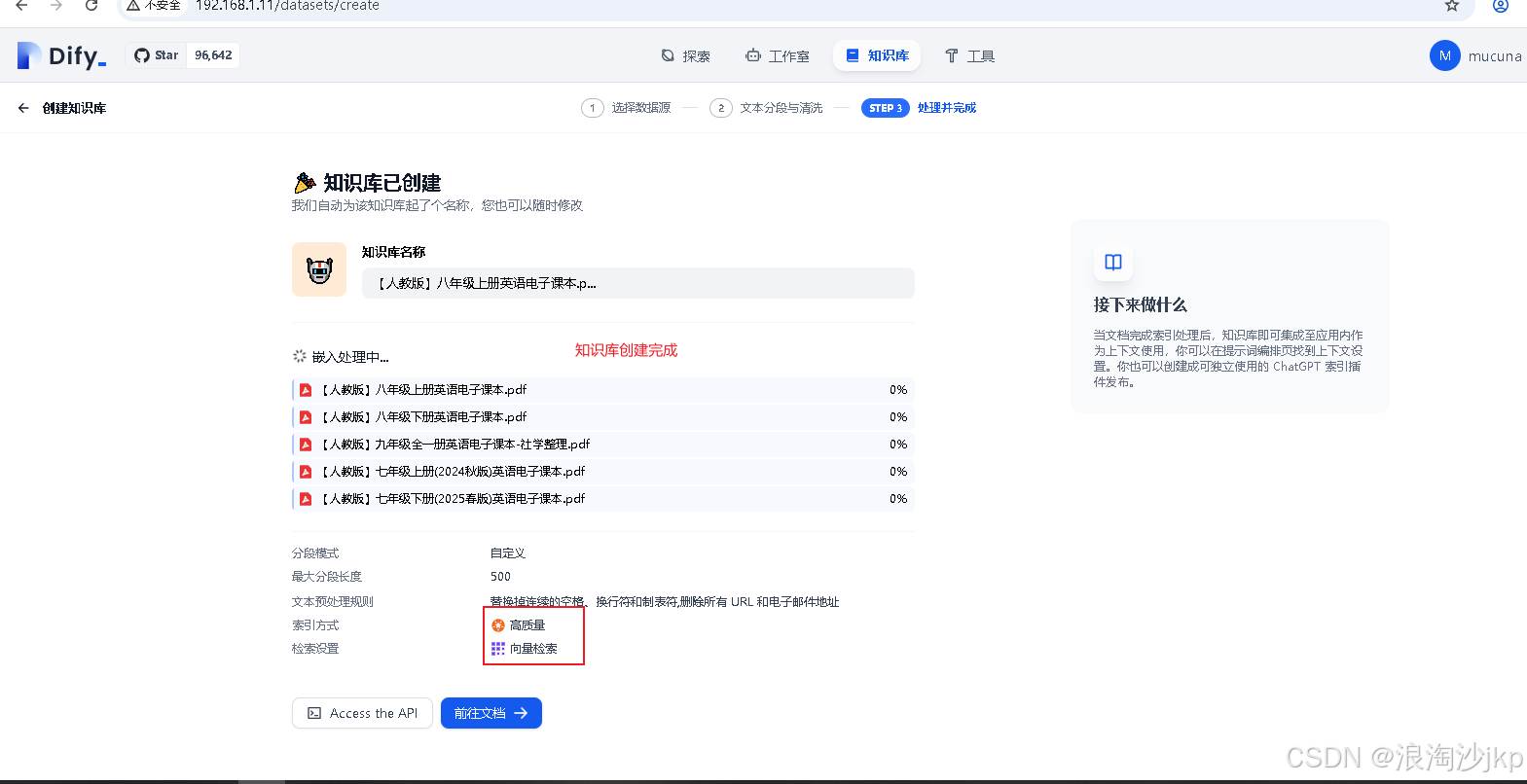
查看知识库文档状态
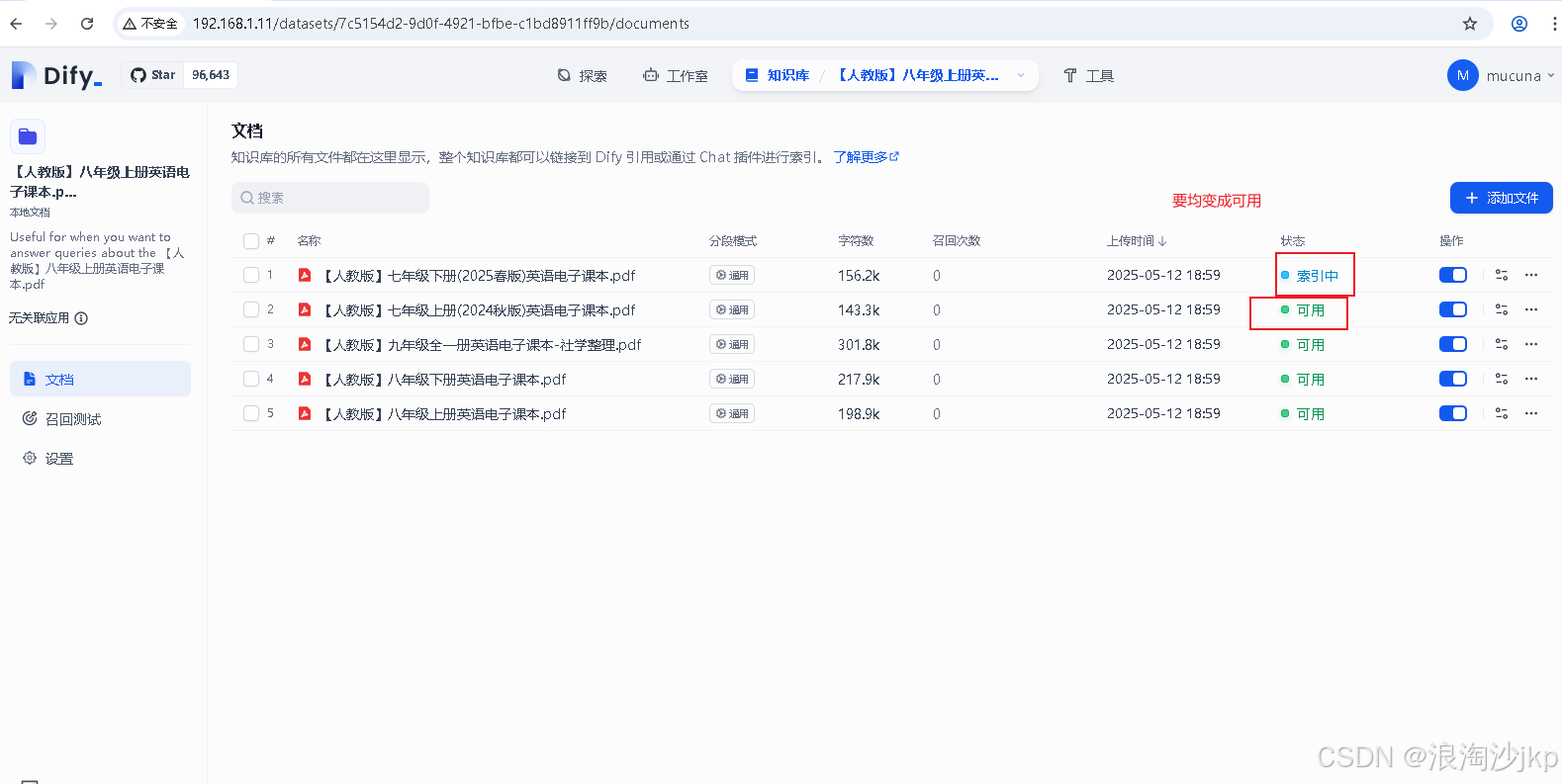
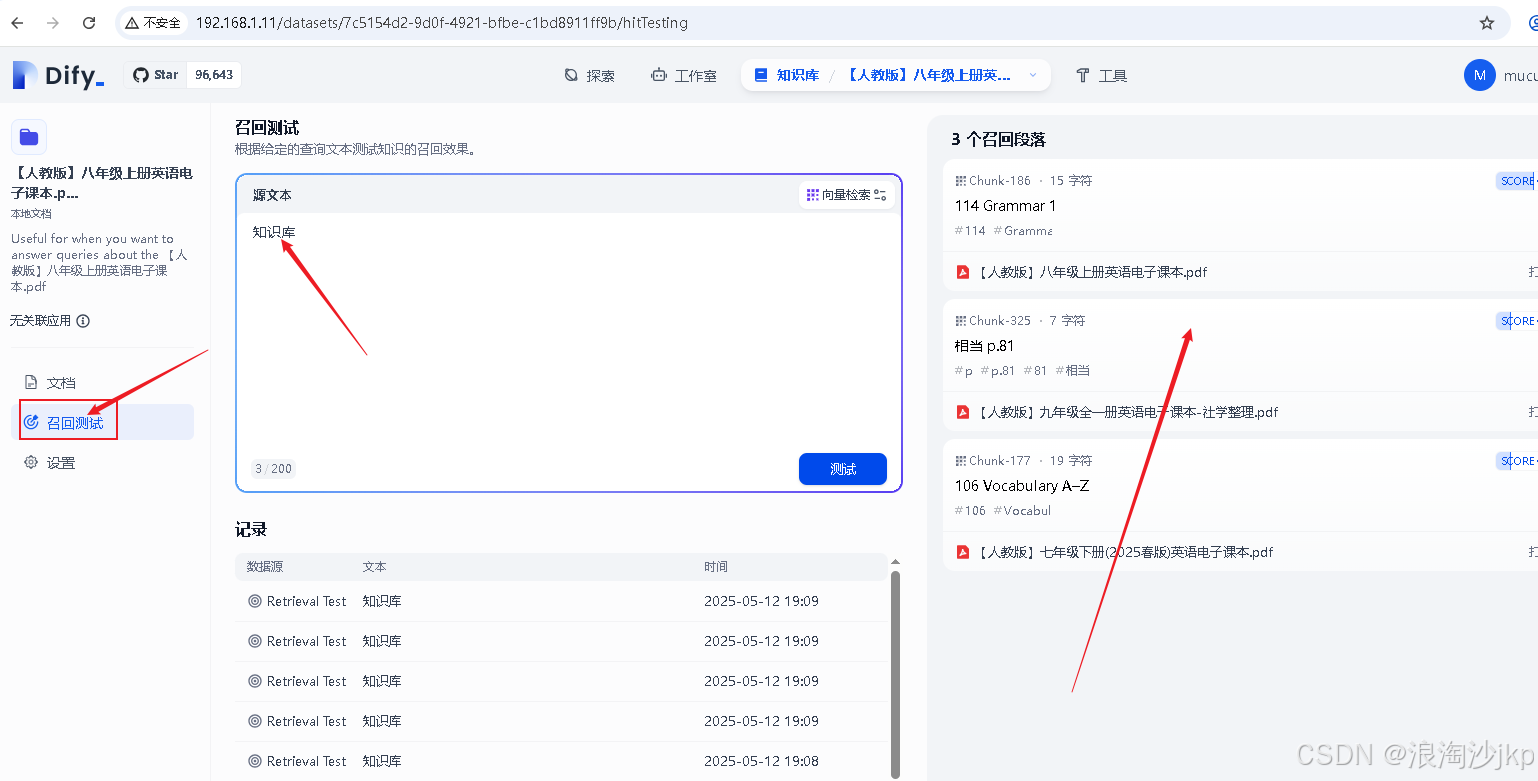
召回测试
四、 创建应用
1、创建好APP
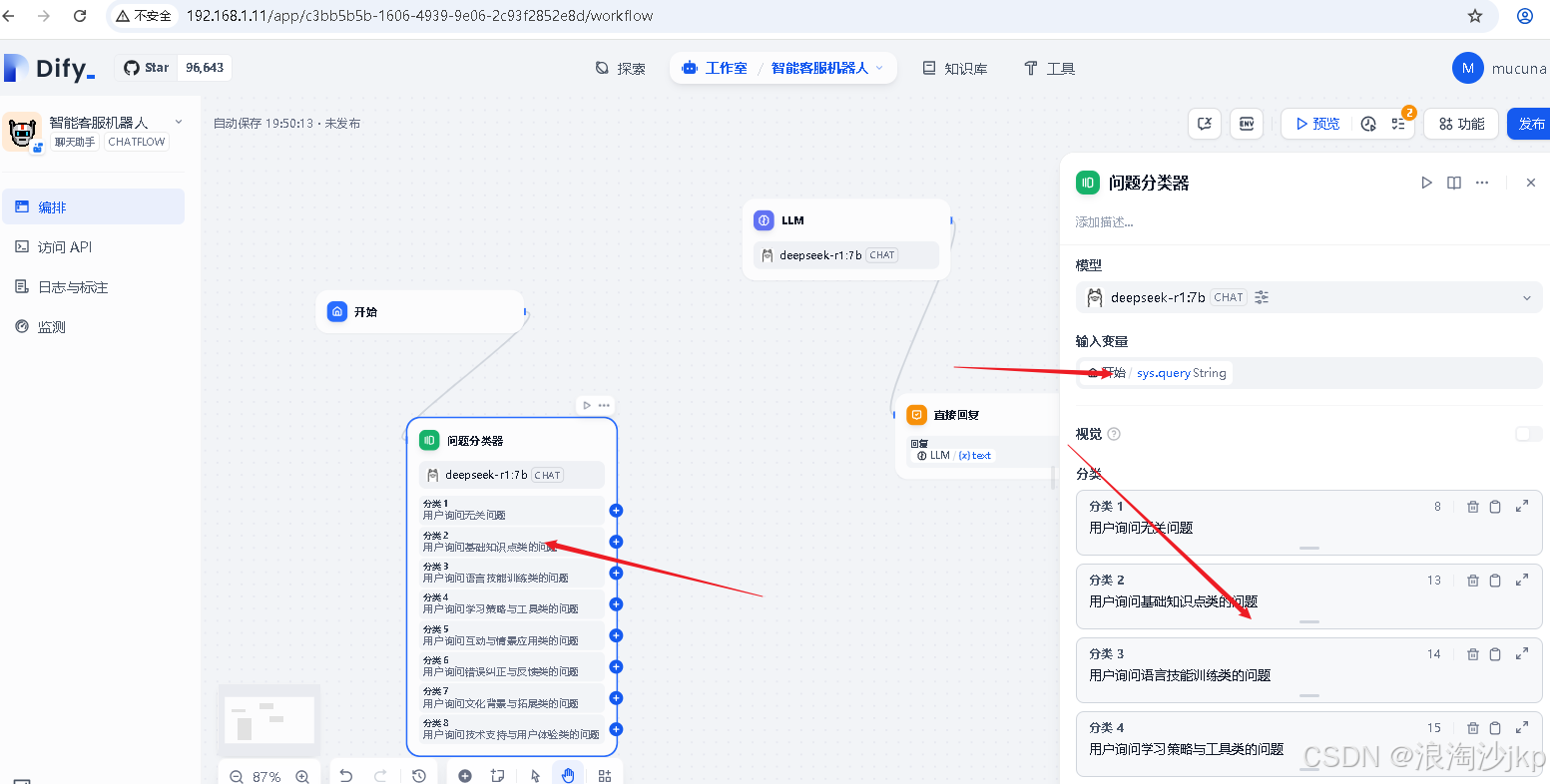
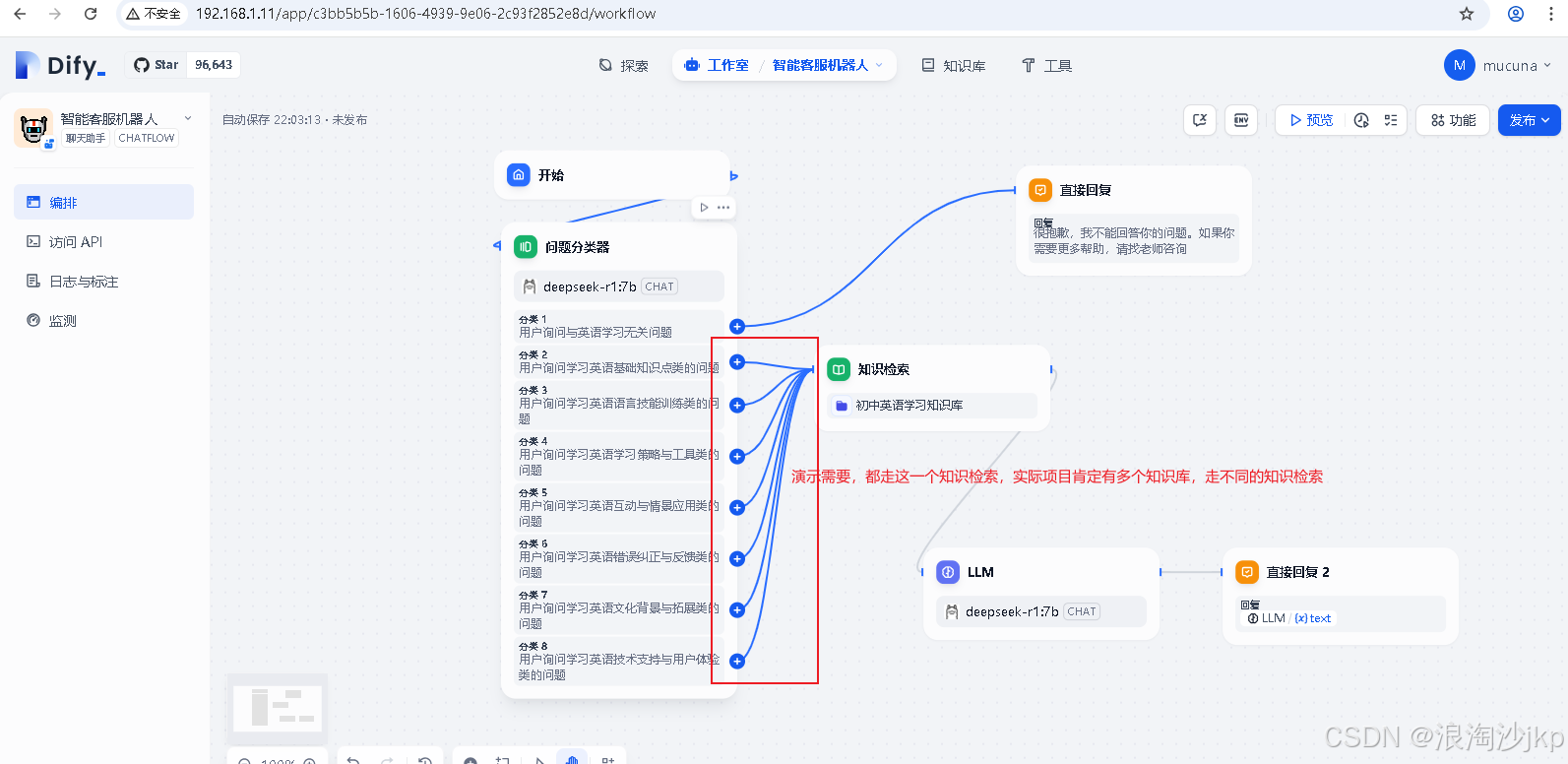
2、创建问题分类节点
你需要使用问题分类节点将用户的不同需求分离开。有的情况下用户甚至会聊无关的话题,对此也需要设置一个分类。
为了让分类更准确,你需要选择更优秀的 LLM,分类需要写的足够具体、区分度足够大
以下是一个学习英语的参考分类:
由于我们知识库自由一个,所以其实演示自由两种1 就是无关问题,其它都是使用我们前面创建的初中英语学习知识库,在实际项目中可以建立多种知识库
1、用户询问与学习英语学习无关问题
2、用户询问学习英语基础知识点类的问题
3、用户询问学习英语语言技能训练类的问题
4、用户询问学习英语学习策略与工具类的问题
5、用户询问学习英语互动与情景应用类的问题
6、用户询问学习英语错误纠正与反馈类的问题
7、用户询问学习英语文化背景与拓展类的问题
8、用户询问学习英语技术支持与用户体验类的问题
如果是“用户询问与学习英语学习无关问题”,可以直接回复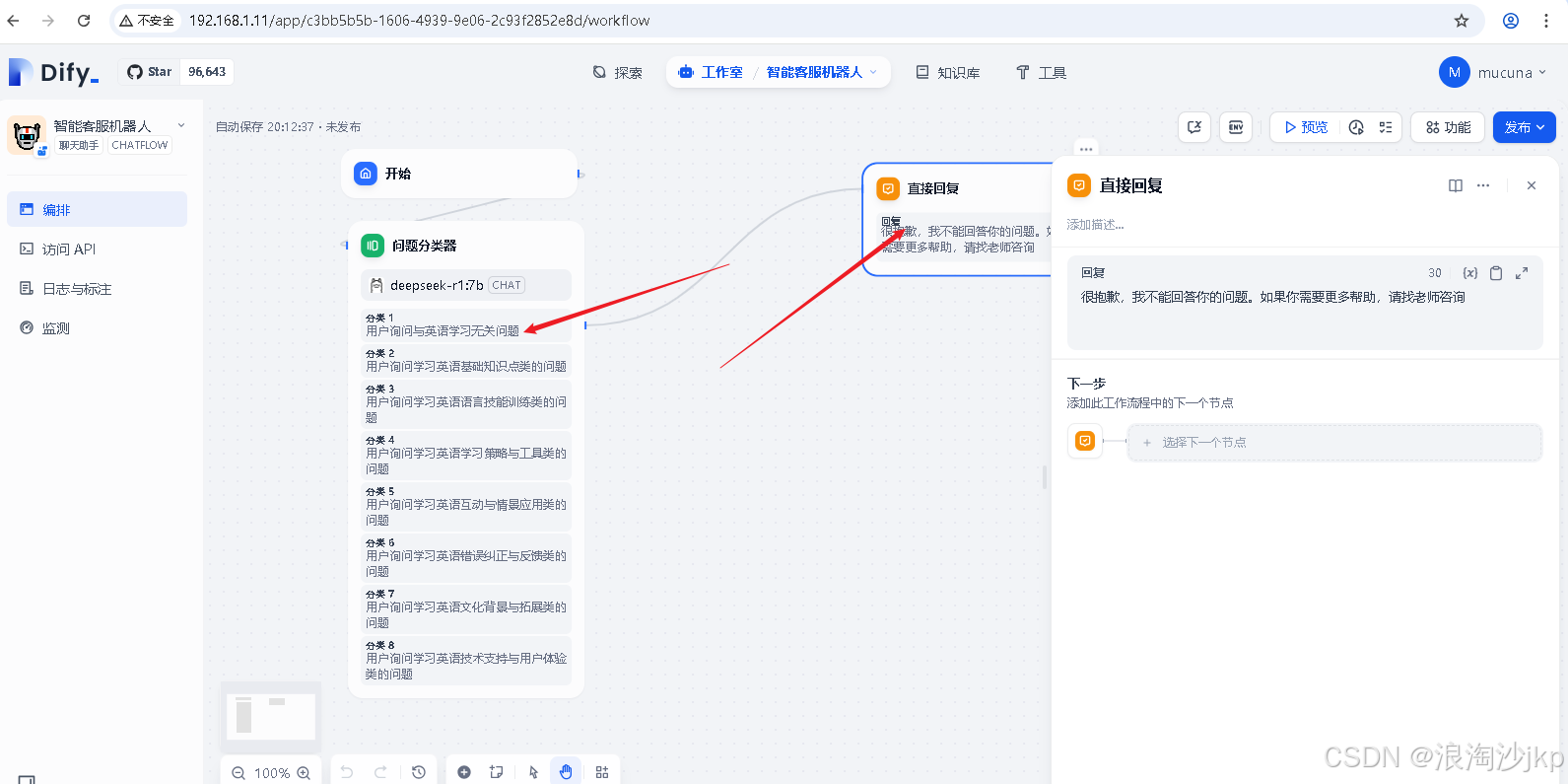
如果是其它类型问题,看下一节添加知识检索节点
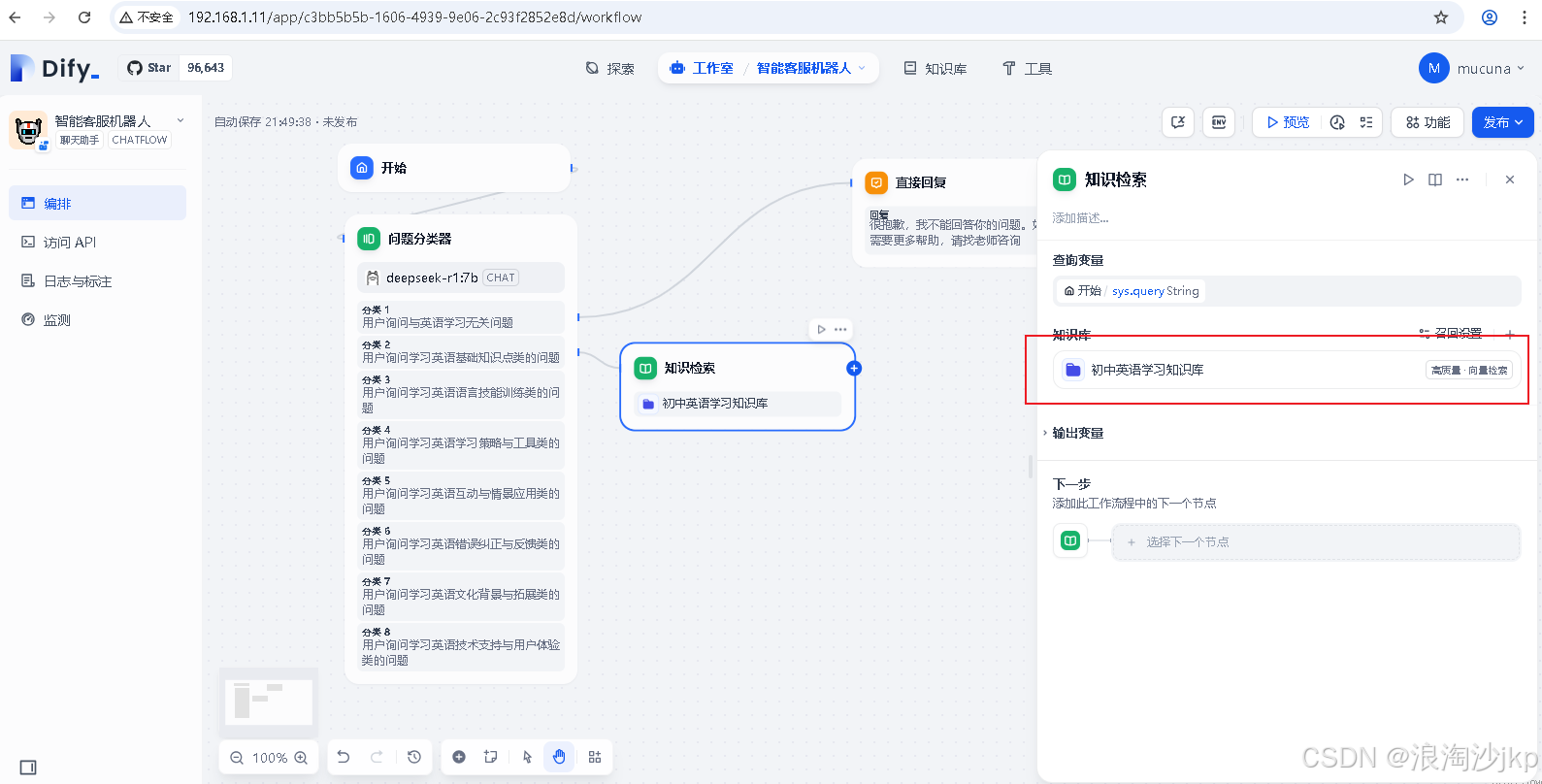
3、添加知识检索节点
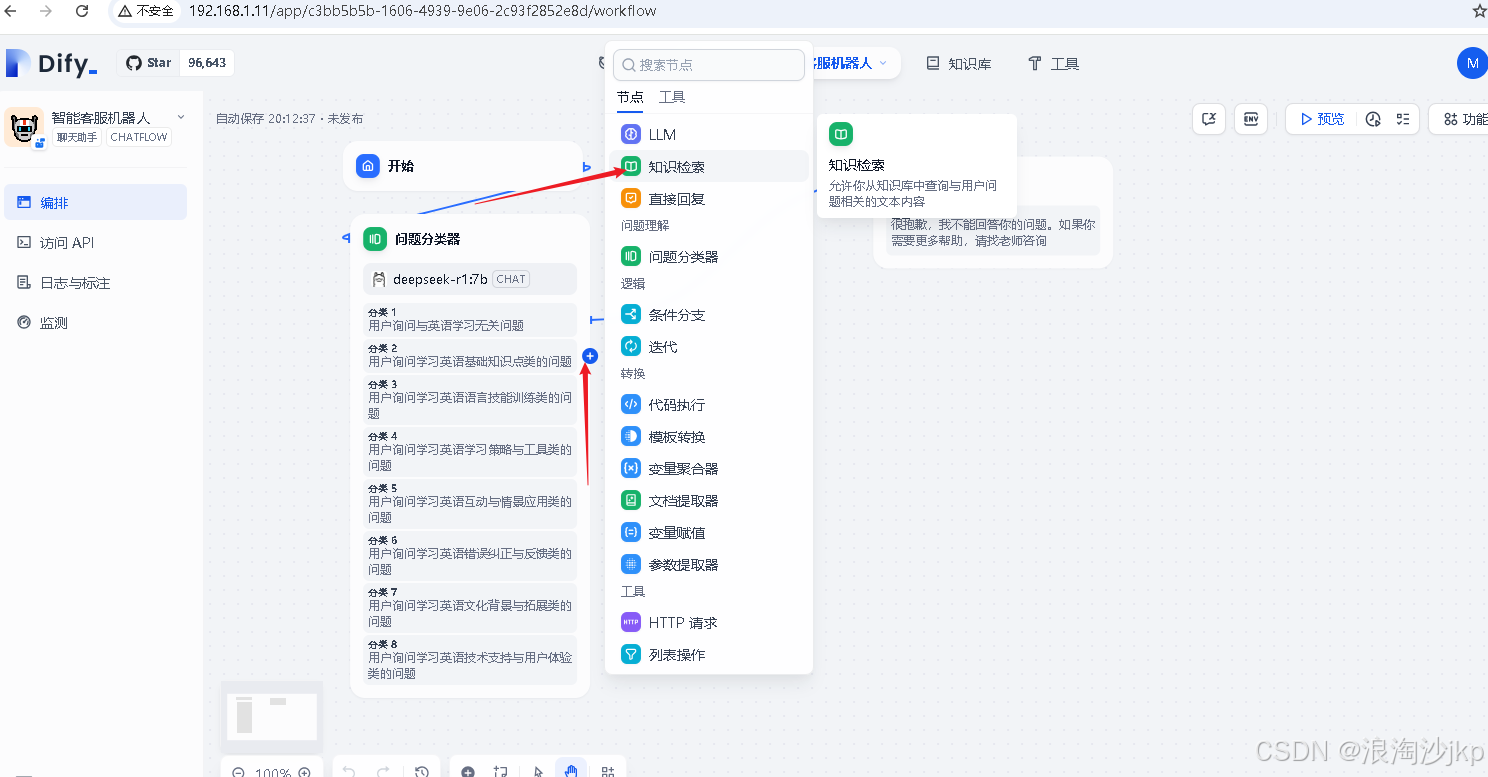
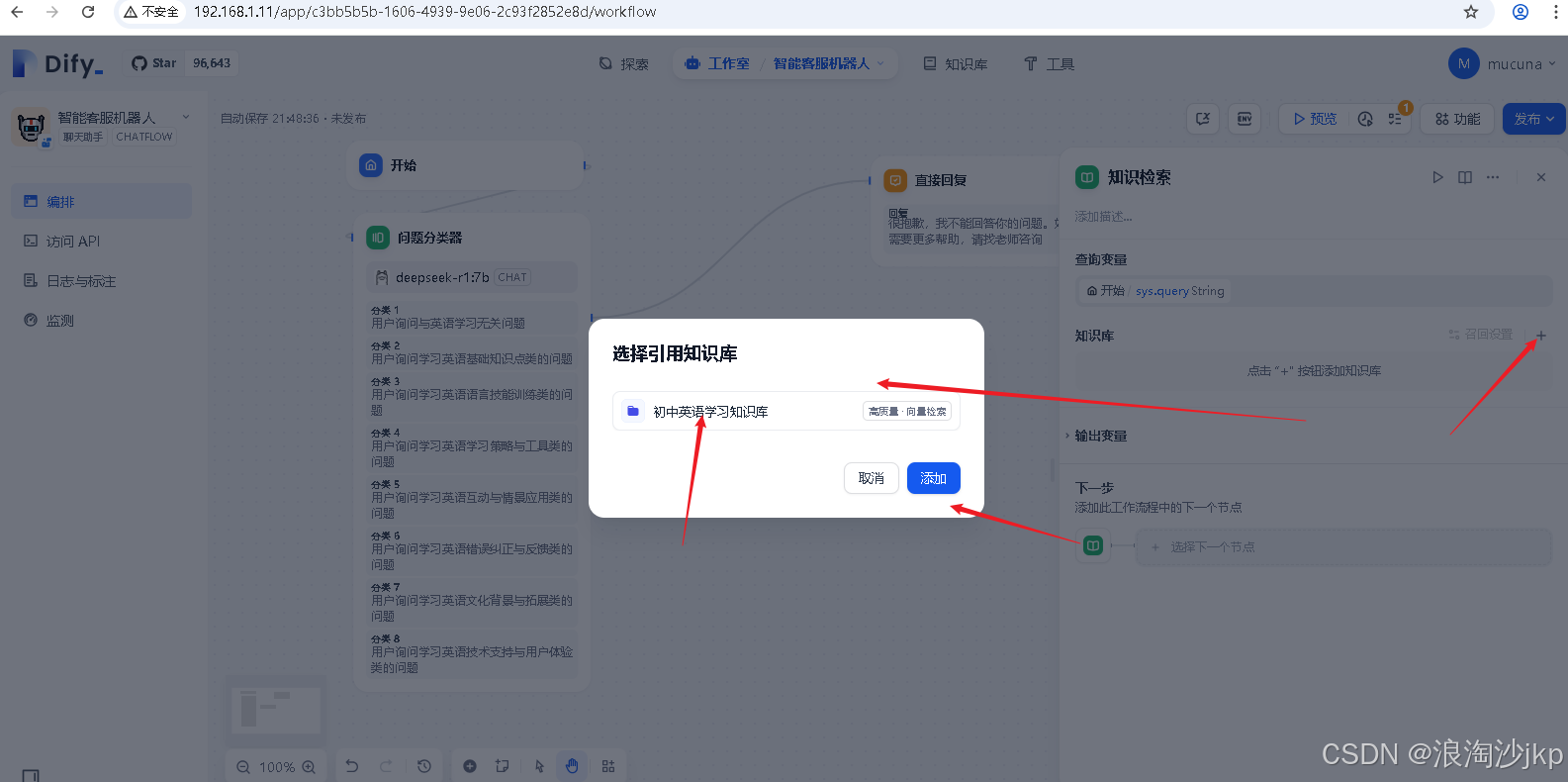
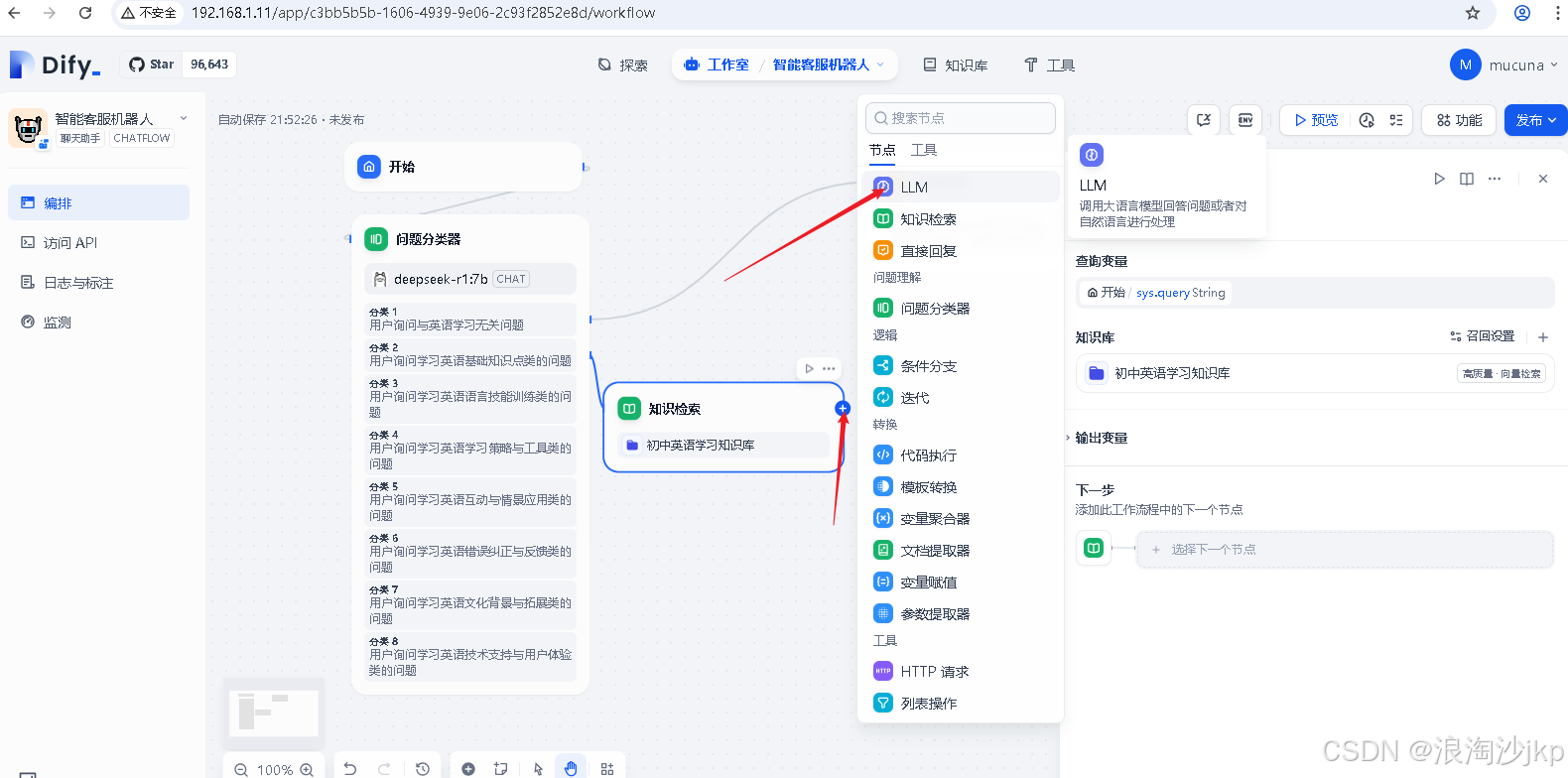
4、LLM 节点
在知识检索节点的下一个节点,你需要选择 LLM 节点来整理知识库召回的内容。
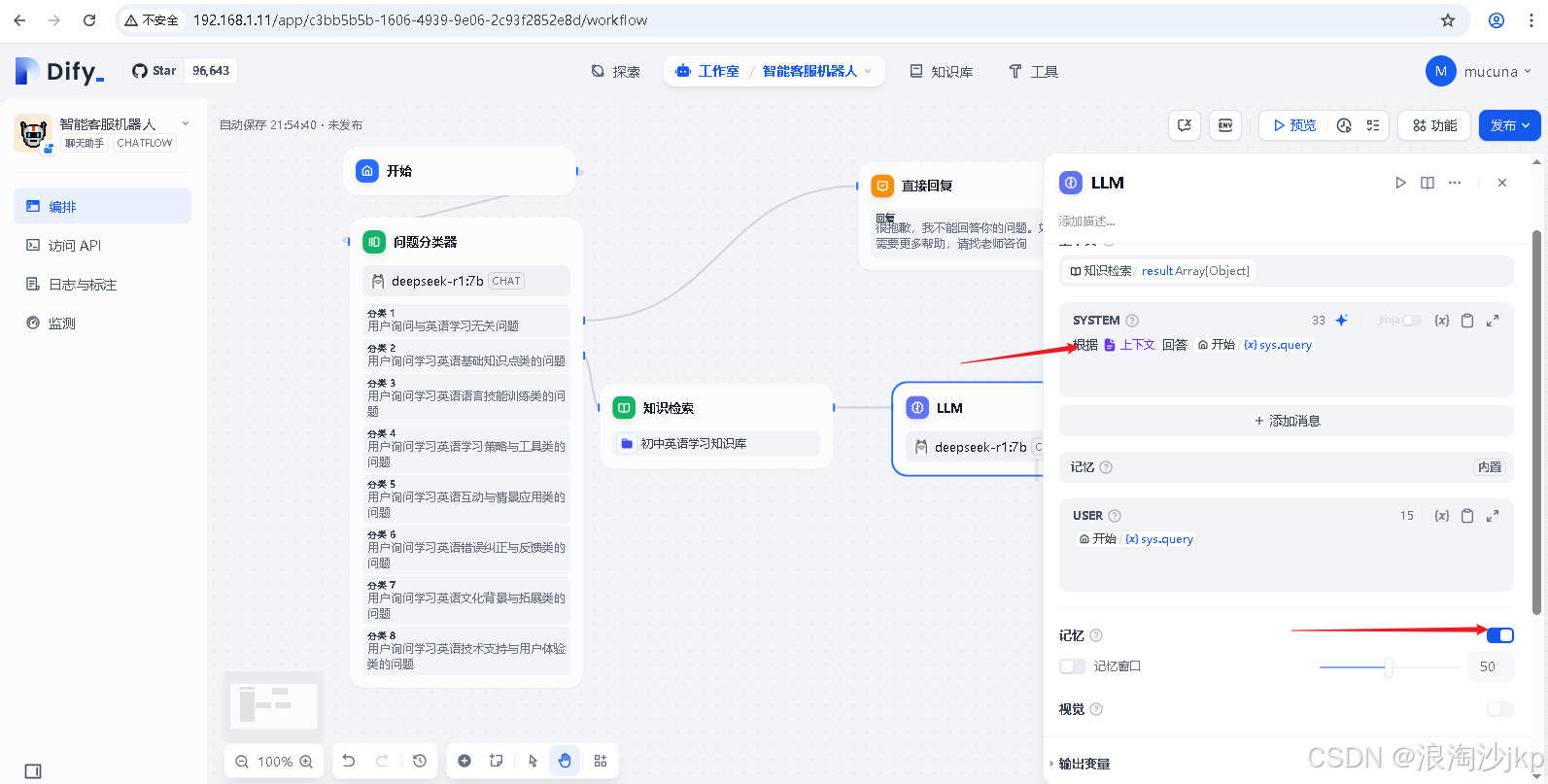
LLM 需要根据用户的提问,调整回复,使得回复内容更加得体。
上下文:需要将知识检索节点的输出作为 LLM 节点的上下文。
你可以在提示词书写区域输入
/或者{来引用变量。在变量中,sys.开头的变量是系统变量,请查询帮助文档相关说明。此外,你可以打开 LLM 记忆让用户的对话体验更加连贯。
5、添加直接回复节点
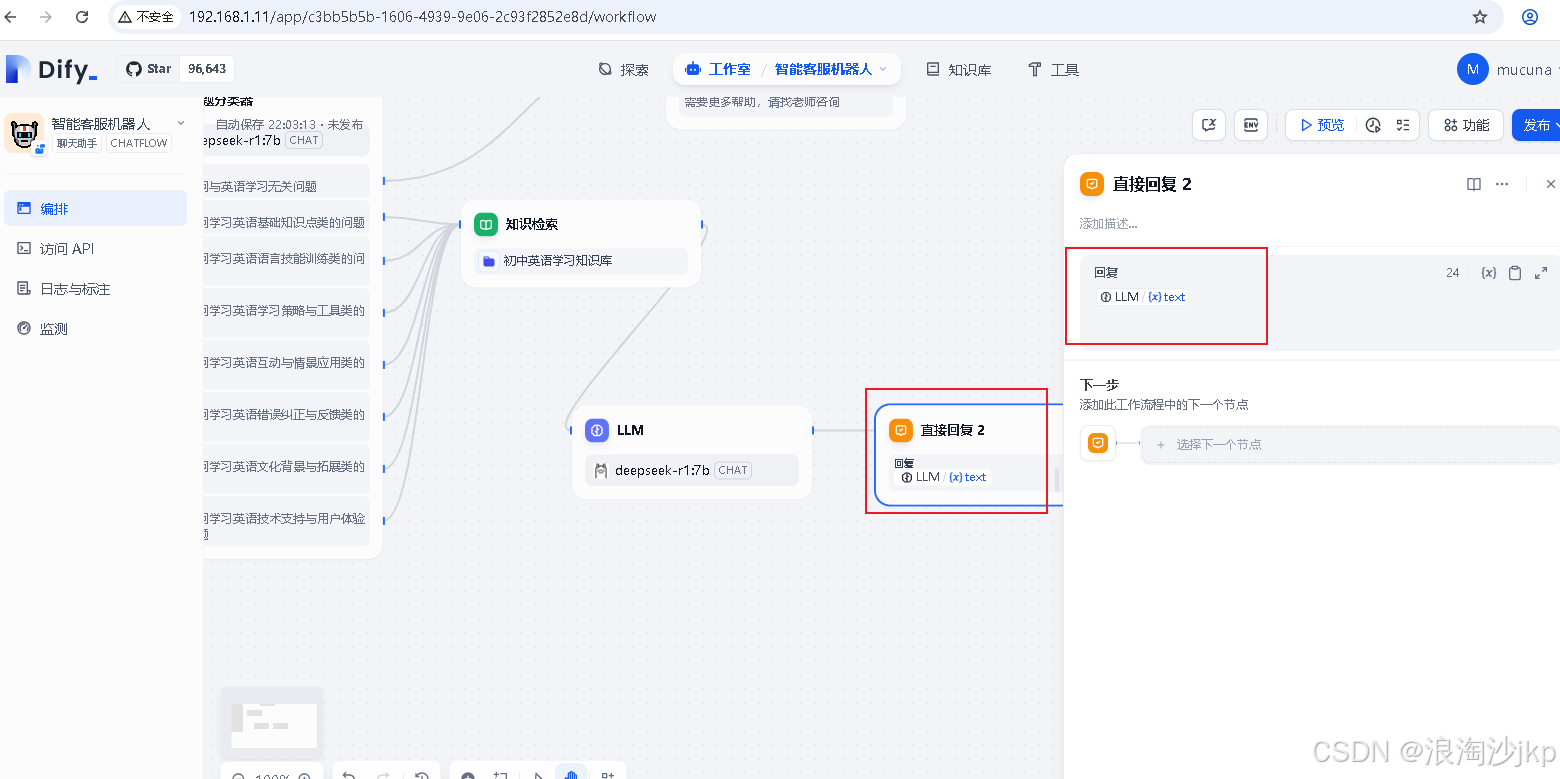
6、其它分类
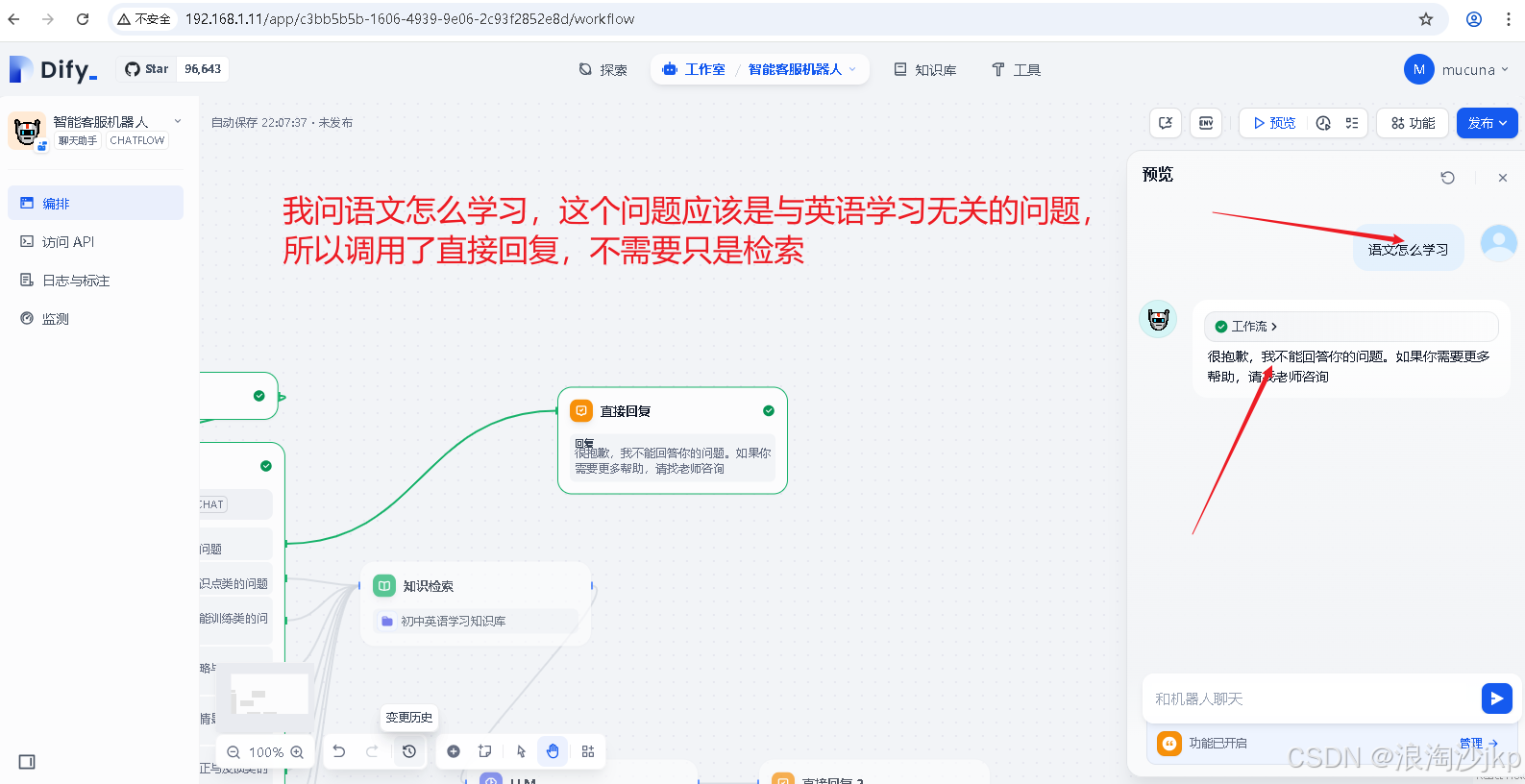
五、测试
1、预览
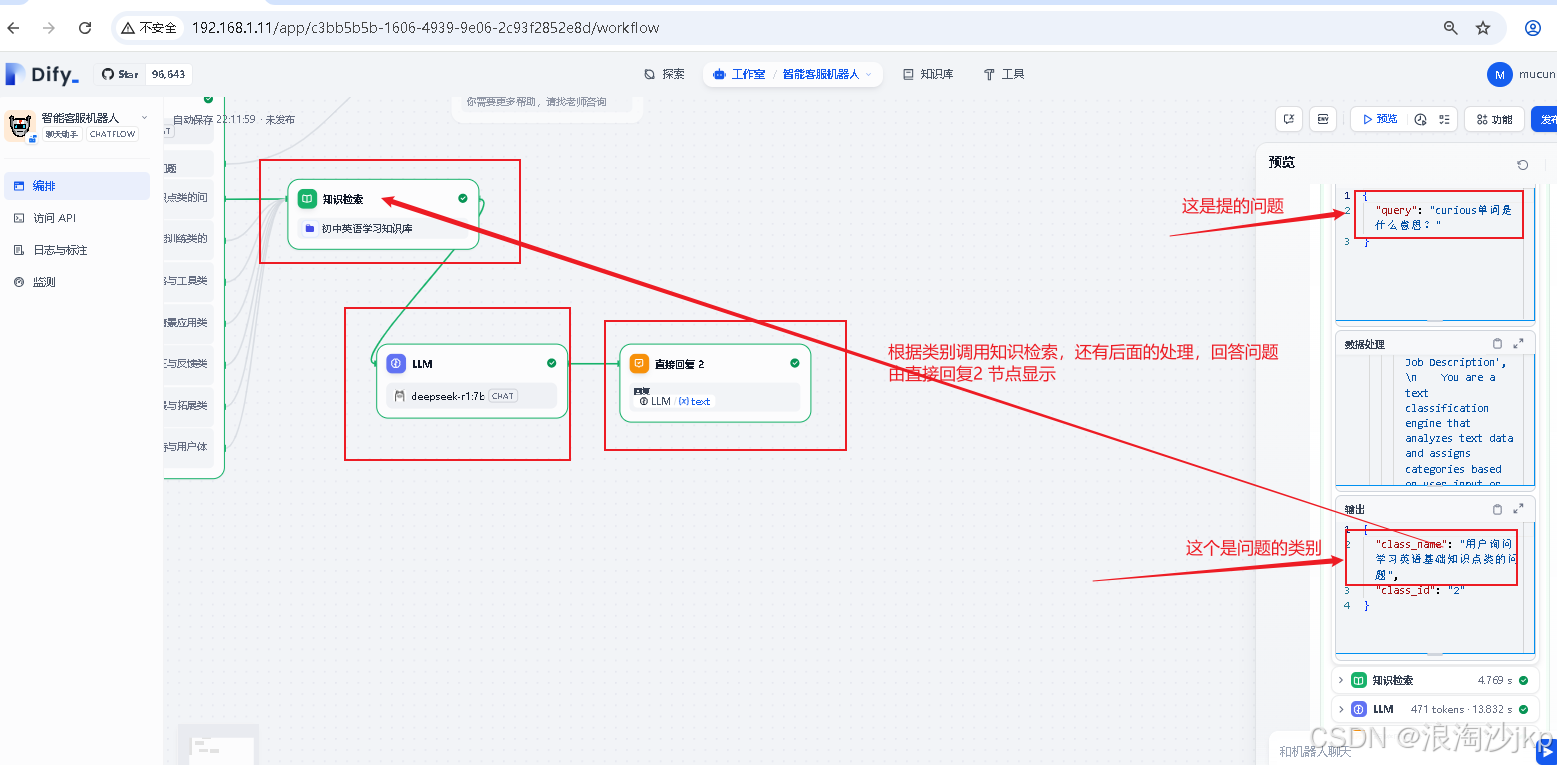
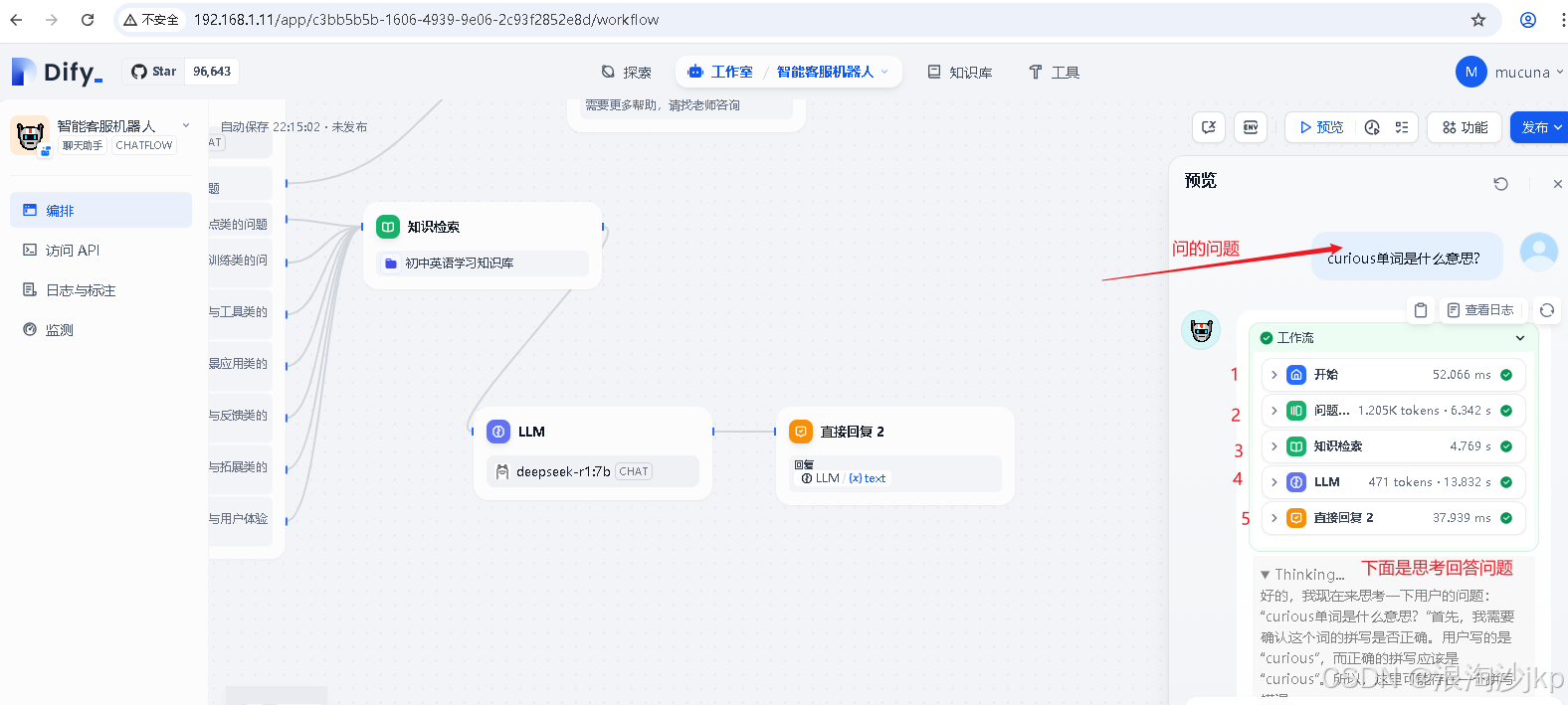
完整回答内容:
Thinking...好的,我现在来思考一下用户的问题:“curious单词是什么意思?”首先,我需要确认这个词的拼写是否正确。用户写的是“curious”,而正确的拼写应该是“curious”。所以,这里可能存在一个拼写错误。
接下来,我要确定这个词的意思。根据我的记忆,“curious”是一个形容词,意思是好奇、好问或者对某事物有疑问。例如,在句子中可能会用作“Mary is curious about the new technology.” 这里表示玛丽对新技术感到好奇。
然后,我需要考虑用户为什么会询问这个单词的含义。这可能是因为他们在学习英语,正在阅读或写作时遇到了这个词,并且不确定其含义。也有可能是他们在做某种练习题,或者在日常交流中遇到了这个词,但不太确定如何使用。
此外,考虑到用户提到了“语法”方面的知识,比如被动语态,这可能意味着他们对英语的其他语法点也有兴趣。因此,在解释“curious”的时候,或许可以稍微提及一些相关的内容,比如它在句子中的作用或与其他词性的差异,这样回答会更全面。
最后,我要确保用词准确,并且表达清晰,让用户能够理解这个单词的含义以及它的常见使用方式。可能还需要提供一个例句来辅助说明,例如:“I'm curious to see the exhibition.” 这样用户可以更直观地理解这个词在句子中的运用。
"Curious" is an adjective that means curious or interested. It describes someone who is asking questions, wondering about things, or wanting to learn more.
Example: "She was curious about how they survived." (她对它们如何生存感到好奇)
引用
【人教版】八年级上册英语电子课本.pdf
【人教版】八年级下册英语电子课本.pdf
【人教版】八年级上册英语电子课本.pdf
2、发布并测试
测试就不做了,和前面一样

















 227
227

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









