







本文来自:曹胜欢博客专栏:http://blog.csdn.net/csh624366188
在软件开发中,数据流和数据库操作占据了一个很重要的位置,所以,熟悉操作数据流和数据库,对于每一个开发者来说都是很重要的,今天就来总结一下I/O,数据库操作
一:从数据流开始
首先先有一个结构图看一下整个数据流中的API结构和对象继承关系信息:
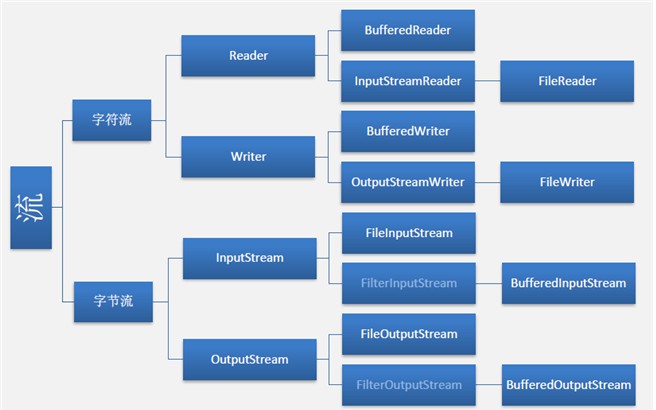
其他常用与流有关的对象:
首先从字符流开始
1、字符流的由来:
因为文件编码的不同,而有了对字符进行高效操作的字符流对象。
原理:其实就是基于字节流读取字节时,去查了指定的码表。
字节流和字符流的区别:
1,字节流读取的时候,读到一个字节就返回一个字节。字符流使用了字节流读到一个或多个字节(中文对应的字节数是两个,UTF-8码表中是3个字节)时。先去查指定的编码表,将查到的字符返回。
2,字节流可以处理所有类型数据,如图片,mp3,avi。而字符流只能处理字符数据。
结论:只要是处理纯文本数据,就要优先考虑使用字符流。除此之外都用
节流。
基本的读写操作方式:
因为数据通常都以文件形式存在。
所以就要找到IO体系中可以用于操作文件的流对象。
通过名称可以更容易获取该对象。
因为IO体系中的子类名后缀绝大部分是父类名称。而前缀都是体现子类功能的名字。
Reader
|--InputStreamReader
|--FileReader:专门用于处理文件的字符读取流对象。
Writer
|--OutputStreamWriter
|--FileWriter:专门用于处理文件的字符写入流对象。
Reader中的常见的方法:
1,int read():读取一个字符。返回的是读到的那个字符。如果读到流的末尾,返回-1.
2,int read(char[]):将读到的字符存入指定的数组中,返回的是读到的字符个数,也就是往数组里装的元素的个数。如果读到流的末尾,返回-1.
3,close():读取字符其实用的是window系统的功能,就希望使用完毕后,进行资源的释放
Writer中的常见的方法:
1,write(ch): 将一个字符写入到流中。
2,write(char[]): 将一个字符数组写入到流中。
3,write(String): 将一个字符串写入到流中。
4,flush():刷新流,将流中的数据刷新到目的地中,流还存在。
5,close():关闭资源:在关闭前会先调用flush(),刷新流中的数据去目的地。然流关闭。
FileWriter:该类没有特有的方法只有自己的构造函数。该类特点在于
1,用于处理文本文件。
2,该类中有默认的编码表,
3,该类中有临时缓冲。
构造函数:在写入流对象初始化时,必须要有一个存储数据的目的地。
对于读取或者写入流对象的构造函数,以及读写方法,还有刷新关闭功能都会抛出IOException或其子类。所以都要进行处理。或者throws抛出,或者try catch处理
另一个小细节:
当指定绝对路径时,定义目录分隔符有两种方式:
1,反斜线但是一定要写两个。\\new FileWriter("c:\\demo.txt");
2,斜线/ 写一个即可。new FileWriter("c:/demo.txt");
一个读取文本文件的经典例子:
字符流的缓冲区:缓冲区的出现提高了对流的操作效率。
原理:其实就是将数组进行封装。
对应的对象:
BufferedWriter:特有方法:newLine():跨平台的换行符。
BufferedReader:特有方法:readLine():一次读一行,到行标记时,将行标记之前的字符数据作为字符串返回。当读到末尾时,返回null。
在使用缓冲区对象时,要明确,缓冲的存在是为了增强流的功能而存在,
所以在建立缓冲区对象时,要先有流对象存在。
其实缓冲内部就是在使用流对象的方法,只不过加入了数组对数据进行了临时存储。为了提高操作数据的效率。
代码上的体现:
写入缓冲区对象。
//建立缓冲区对象必须把流对象作为参数传递给缓冲区的构造函数。
BufferedWriter bufw = new BufferedWriter(new FileWriter("buf.txt"));
bufw.write("abce");//将数据写入到了缓冲区。
bufw.flush();//对缓冲区的数据进行刷新。将数据刷到目的地中。
bufw.close();//关闭缓冲区,其实关闭的是被包装在内部的流对象。
读取缓冲区对象。
BufferedReader bufr = new BufferedReader(new FileReader("buf.txt"));
String line = null;
//按照行的形式取出数据。取出的每一个行数据不包含回车符。
while((line=bufr.readLine())!=null)
{
System.out.println(line);
}
bufr.close();
readLine():方法的原理:
其实缓冲区中的该方法,用的还是与缓冲区关联的流对象的read方法。只不过,每一次读到一个字符,先不进行具体操作,先进行临时存储。当读取到回车标记时,将临时容器中存储的数据一次性返回。
既然明确了原理,我们也可以实现一个类似功能的方法。
然后说一下字节流:
抽象基类:InputStream,OutputStream。
字节流可以操作任何数据。
注意:字符流使用的数组是字符数组。char [] chs字节流使用的数组是字节数组。byte [] bt
FileOutputStream fos = new FileOutputStream("a.txt");
fos.write("abcde");//直接将数据写入到了目的地。
fos.close();//只关闭资源。
FileInputStream fis = new FileInputStream("a.txt");
//fis.available();//获取关联的文件的字节数。
//如果文件体积不是很大。
//可以这样操作。
byte[] buf = new byte[fis.available()];//创建一个刚刚好的缓冲区。
//但是这有一个弊端,就是文件过大,大小超出jvm的内容空间时,会内存溢出。
fis.read(buf);
一个小问题:
字节流的read()方法读取一个字节。为什么返回的不是byte类型,而是int类型呢?
因为read方法读到末尾时返回的是-1,而在所操作的数据中的很容易出现连续多个1的情况,而连续读到8个1,就是-1,导致读取会提前停止。所以将读到的一个字节给提升为一个int类型的数值,但是只保留原字节,并在剩余二进制位补0.
对于write方法,可以一次写入一个字节,但接收的是一个int类型数值。只写入该int类型的数值的最低一个字节(8位)。
简单说:read方法对读到的数据进行提升。write对操作的数据进行转换。这是神马意思???
转换流:
特点:
1,是字节流和字符流之间的桥梁。
2,该流对象中可以对读取到的字节数据进行指定编码表的编码转换。
什么时候使用呢?
1,当字节和字符之间有转换动作时。
2,流操作的数据需要进行编码表的指定时。
具体的对象体现:
1,InputStreamReader:字节到字符的桥梁。
2,OutputStreamWriter:字符到字节的桥梁。
这两个流对象是字符流体系中的成员。
那么它们有转换作用,而本身又是字符流。所以在构造的时候,需要传入字节流对象进来。
构造函数:
InputStreamReader(InputStream):通过该构造函数初始化,使用的是本系统默认的编码表GBK。
InputStreamReader(InputStream,String charSet):通过该构造函数初始化,可以指定编码表。
OutputStreamWriter(OutputStream):通过该构造函数初始化,使用的是本系统默认的编码表GBK。
OutputStreamWriter(OutputStream,String charSet):通过该构造函数初始化,可以指定编码表。
可以和流相关联的集合对象Properties.
Map
|--Hashtable
|--Properties
Properties:该集合不需要泛型,因为该集合中的键值对都是String类型。
1,存入键值对:setProperty(key,value);
2,获取指定键对应的值:value getProperty(key);
3,获取集合中所有键元素:
Enumeration propertyNames();
在jdk1.6版本给该类提供一个新的方法。
Set<String> stringPropertyNames();
4,列出该集合中的所有键值对,可以通过参数打印流指定列出到的目的地。
list(PrintStream);
list(PrintWriter);
例:list(System.out):将集合中的键值对打印到控制台。
list(new PrintStream("prop.txt")):将集合中的键值对存储到prop.txt文件中。
5,可以将流中的规则数据加载进行集合,并称为键值对。
load(InputStream):
jdk1.6版本。提供了新的方法。
load(Reader):
注意:流中的数据要是"键=值" 的规则数据。
6,可以将集合中的数据进行指定目的的存储。
store(OutputStram,String comment)方法。
jdk1.6版本。提供了新的方法。
store(Writer ,String comment):
使用该方法存储时,会带着当时存储的时间。
File类:
该类的出现是对文件系统的中的文件以及文件夹进行对象的封装。
可以通过对象的思想来操作文件以及文件夹。
1,构造函数:
File(String filename):将一个字符串路径(相对或者绝对)封装成File对象,该路径是可存在的,也可以是不存在。
File(String parent,String child);
File(File parent,String child);
2,特别的字段:separator:跨平台的目录分隔符。
如:File file = new File("c:"+File.separator+"abc"+File.separator+"a.txt");
3,常见方法:
1,创建:
boolean createNewFile()throws IOException:创建文件,如果被创建的文件已经存在,则不创建。
boolean mkdir(): 创建文件夹。
boolean mkdirs(): 创建多级文件夹。
2,删除:
boolean delete():可用于删除文件或者文件夹。
注意:对于文件夹只能删除不带内容的空文件夹,
对于带有内容的文件夹,不可以直接删除,必须要从里往外删除。
void deleteOnExit(): 删除动作交给系统完成。无论是否反生异常,系统在退出时执行删除动作。
3,判断:
boolean canExecute():
boolean canWrite():
boolean canRead();
boolean exists():判断文件或者文件夹是否存在。
boolean isFile(): 判断File对象中封装的是否是文件。
boolean isDirectory():判断File对象中封装的是否是文件夹。
boolean isHidden():判断文件或者文件夹是否隐藏。在获取硬盘文件或者文件夹时,
对于系统目录中的文件,Java是无法访问的,所以在遍历,可以避免遍历隐藏文件。
4,获取:
getName():获取文件或者文件夹的名称。
getPath():File对象中封装的路径是什么,获取的就是什么。
getAbsolutePath():无论File对象中封装的路径是什么,获取的都是绝对路径。
getParent(): 获取File对象封装文件或者文件夹的父目录。
注意:如果封装的是相对路径,那么返回的是null.
long length():获取文件大小。
longlastModified():获取文件或者文件最后一次修改的时间。
static File[] listRoots():获取的是被系统中有效的盘符。
String[] list():获取指定目录下当前的文件以及文件夹名称。
String[] list(Filenamefilter): 可以根据指定的过滤器,过滤后的文件及文件夹名称。
File[] listFiles():获取指定目录下的文件以及文件夹对象。
5,重命名:
renameTo(File):
File f1 = new File("c:\\a.txt");
File f2 = new File("c:\\b.txt");
f1.renameTo(f2);//将c盘下的a.txt文件改名为b.txt文件。
对象的序列化。
ObjectInputStream
ObjectOutputStream
可以通过这两个流对象直接操作已有对象并将对象进行本地持久化存储。
存储后的对象可以进行网络传输。
Serializable:该接口其实就是一个没有方法的标记接口。
用于给类指定一个UID。该UID是通过类中的可序列化成员的数字签名运算出来的一个long型的值。
只要是这些成员没有变化,那么该值每次运算都一样。
该值用于判断被序列化的对象和类文件是否兼容。
如果被序列化的对象需要被不同的类版本所兼容。可以在类中自定义UID。
定义方式:static final long serialVersionUID = 42L;
注意:对应静态的成员变量,不会被序列化。
对应非静态也不想被序列化的成员而言,可以通过transient关键字修饰。
通常,这两个对象成对使用。
————————————————————————————————————
其他的数据操作流
操作基本数据类型的流对象。
DataInputStream
DataInputStream(InputStream);
操作基本数据类型的方法:
int readInt():一次读取四个字节,并将其转成int值。
boolean readBoolean():一次读取一个字节。
short readShort();
long readLong();
剩下的数据类型一样。
String readUTF():按照utf-8修改版读取字符。注意,它只能读writeUTF()写入的字符数据。
DataOutputStream
DataOutputStream(OutputStream):
操作基本数据类型的方法:
writeInt(int):一次写入四个字节。
注意和write(int)不同。write(int)只将该整数的最低一个8位写入。剩余三个8位丢弃。
writeBoolean(boolean);
writeShort(short);
writeLong(long);
剩下是数据类型也也一样。
writeUTF(String):按照utf-8修改版将字符数据进行存储。只能通过readUTF读取。
通常只要操作基本数据类型的数据。就需要通过DataStram进行包装。
通常成对使用。
————————————————————————————————————
操作数组的流对象。
1,操作字节数组
ByteArrayInputStream
ByteArrayOutputStream
toByteArray();
toString();
writeTo(OutputStream);
2,操作字符数组。
CharArrayReader
CharArrayWriter
对于这些流,源是内存。目的也是内存。
而且这些流并未调用系统资源。使用的就是内存中的数组。
所以这些在使用的时候不需要close。
操作数组的读取流在构造时,必须要明确一个数据源。所以要传入相对应的数组。
对于操作数组的写入流,在构造函数可以使用空参数。因为它内置了一个可变长度数组作为缓冲区。















 217
217

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









