







 本文介绍了MMEngine中的注册器和配置管理,讲解了opencompass代码流程,包括配置文件读取、模型推理、评估和可视化。通过注册器管理模块,配置文件读取和build_from_cfg函数,实现动态创建类实例。opencompass利用配置文件执行推理任务,通过partitioner和runner模块处理数据集和模型,进行评估并可视化结果。
本文介绍了MMEngine中的注册器和配置管理,讲解了opencompass代码流程,包括配置文件读取、模型推理、评估和可视化。通过注册器管理模块,配置文件读取和build_from_cfg函数,实现动态创建类实例。opencompass利用配置文件执行推理任务,通过partitioner和runner模块处理数据集和模型,进行评估并可视化结果。
1 注册器(Registry)
为了管理功能相似的模块,MMEngine实现了注册器。注册器可以被视作这些类或函数的抽象。例如注册器 MODELS 可以被视作所有模型的抽象。
1.1 什么是注册器
MMEngine 实现的注册器可以看作一个映射表和模块构建方法(build function)的组合。
映射表:维护了一个字符串到类或者函数的映射,使得用户可以借助字符串查找到相应的类或函数,例如维护字符串 “ResNet” 到 ResNet 类或函数的映射,使得用户可以通过 “ResNet” 找到 ResNet 类;
模块构建方法:定义了如何根据字符串查找到对应的类或函数以及如何实例化这个类或者调用这个函数。
MMEngine 中的注册器默认使用 build_from_cfg 函数来查找并实例化字符串对应的类或者函数。
def build_from_cfg(
cfg: Union[dict, ConfigDict, Config],
registry: Registry,
default_args: Optional[Union[dict, ConfigDict, Config]] = None) -> Any:
"""Build a module from config dict when it is a class configuration, or
call a function from config dict when it is a function configuration.
If the global variable default scope (:obj:`DefaultScope`) exists,
:meth:`build` will firstly get the responding registry and then call
its own :meth:`build`.
At least one of the ``cfg`` and ``default_args`` contains the key "type",
which should be either str or class. If they all contain it, the key
in ``cfg`` will be used because ``cfg`` has a high priority than
``default_args`` that means if a key exists in both of them, the value of
the key will be ``cfg[key]``. They will be merged first and the key "type"
will be popped up and the remaining keys will be used as initialization
arguments.
函数 build_from_cfg 是设计用来从配置字典(配置实例)创建一个类实例或调用一个函数。它通过解耦配置和对象的实例化增加了系统的灵活性和可扩展性。具体来说,它从一个注册表中获取类或函数的类型,并使用提供的参数初始化它。
参数解释
cfg: 这是一个包含配置信息的字典(或 ConfigDict/Config 类型),至少需要包含一个 type 键,该键指定了要构建或调用的类或函数的名称。
registry: 这是一个 Registry 对象,build_from_cfg 函数会在这个注册表中查找 type 指定的名称,以获取对应的类或函数。
default_args: 这是可选参数,提供一些默认的初始化参数,如果在 cfg 中没有提供相应的值,则会使用这里的默认值。
功能详解
类型和有效性检查:函数开始会检查 cfg 是否为字典或 ConfigDict/Config 类型。同时也会检查 registry 是否为 Registry 类型,以及 default_args 是否为字典、ConfigDict、Config 或者 None。
合并参数:default_args 中的参数将与 cfg 合并。如果同一个键在两者中都存在,cfg 中的值将会覆盖 default_args 中的值。
处理注册表和作用域:如果 cfg 中提供了特定的 scope,则函数将尝试在该作用域下从注册表中获取相应的类或函数。
获取并实例化类/调用函数:
如果 type 是字符串,会在注册表中查找相应的类或函数。
如果找到,将使用 cfg 中除 type 外的其它参数来初始化这个类或调用这个函数。
如果 type 直接是一个可调用对象(如类、函数等),直接使用这个对象。
实例化的特殊处理:如果获取的对象是 ManagerMixin 的子类,使用特殊的 get_instance 方法来实例化,以确保全局可访问性。否则,使用普通的实例化方法。
日志记录:创建实例后,会记录一条日志,说明从哪个模块构建了哪个类的实例,增加可追踪性。
用例示例
作为装饰器使用:注册类时,可以直接使用 @MODELS.register_module() 装饰器,使类自动注册到 MODELS 注册表中。
作为普通函数使用:可以将类直接作为参数传递给 register_module 方法,手动进行注册。
动态创建实例:通过传递一个包含 type 和其他参数的字典到 build_from_cfg,可以根据配置动态创建类的实例或调用函数。
1.2 使用流程
使用注册器管理代码库中的模块,需要以下三个步骤:
1 创建注册器
2 创建一个用于实例化类的构建方法(可选,在大多数情况下可以只使用默认方法)
3 将模块加入注册器中
4 模块成功注册后,我们可以通过配置文件使用这个激活模块。
示例1
from mmengine import Registry
ACTIVATION = Registry('activation', scope='mmengine')
@ACTIVATION.register_module()
class Sigmoid(nn.Module):
def __init__(self):
super().__init__()
def forward(self, x):
print('call Sigmoid.forward')
return x
act_cfg = dict(type='Sigmoid')
activation = ACTIVATION.build(act_cfg)
output = activation(input)# call Sigmoid.forward
示例2
from mmengine import Registry, build_from_cfg
MODELS = Registry('models')
@MODELS.register_module()
class ResNet:
def __init__(self, depth, stages=4):
self.depth = depth
self.stages = stages
cfg = dict(type='ResNet', depth=50)
model = build_from_cfg(cfg, MODELS)
# Returns an instantiated object
@MODELS.register_module()
def resnet50():
pass
resnet = build_from_cfg(dict(type='resnet50'), MODELS)
# Return a result of the calling function
2 配置(Config)
MMEngine 实现了抽象的配置类(Config),为用户提供统一的配置访问接口。配置类能够支持不同格式的配置文件,包括 python,json,yaml,用户可以根据需求选择自己偏好的格式。配置类提供了类似字典或者 Python 对象属性的访问接口,用户可以十分自然地进行配置字段的读取和修改。
2.1 配置文件读取
配置类提供了统一的接口 Config.fromfile(),来读取和解析配置文件。
合法的配置文件应该定义一系列键值对,这里举几个不同格式配置文件的例子。
Python 格式:
test_int = 1
test_list = [1, 2, 3]
test_dict = dict(key1='value1', key2=0.1)
Json 格式:
{
"test_int": 1,
"test_list": [1, 2, 3],
"test_dict": {"key1": "value1", "key2": 0.1}
}
调用 Config.fromfile(‘config.xxx’) 接口加载这三个文件都会得到相同的结果,构造了包含 3 个字段的配置对象。我们以 config.py 为例,我们先将示例配置文件下载到本地:
from mmengine.config import Config
cfg = Config.fromfile('learn_read_config.py')
print(cfg)
Config (path: learn_read_config.py): {'test_int': 1, 'test_list': [1, 2, 3], 'test_dict': {'key1': 'value1', 'key2': 0.1}}
2.2 配置文件的使用
通过读取配置文件来初始化配置对象后,就可以像使用普通字典或者 Python 类一样来使用这个变量了。 我们提供了两种访问接口,即类似字典的接口 cfg[‘key’] 或者类似 Python 对象属性的接口 cfg.key。这两种接口都支持读写。
3 opencompass代码流程
整个项目首先基于的是MMEngine框架,在此框架下,Partitioner模块会接收数据集与参数配置模块,并根据模型生成、结果评测等类型将整个评测任务拆分多个最小粒度的task元素。参数配置模块包括数据集的配置和模型的配置。数据集配置包括数据集的加载、预处理等配置,模型的配置包括模型的加载、预测生成等配置。最后有一个Runner模块负责管理和有序执行所有的task,完成最终的评测任务
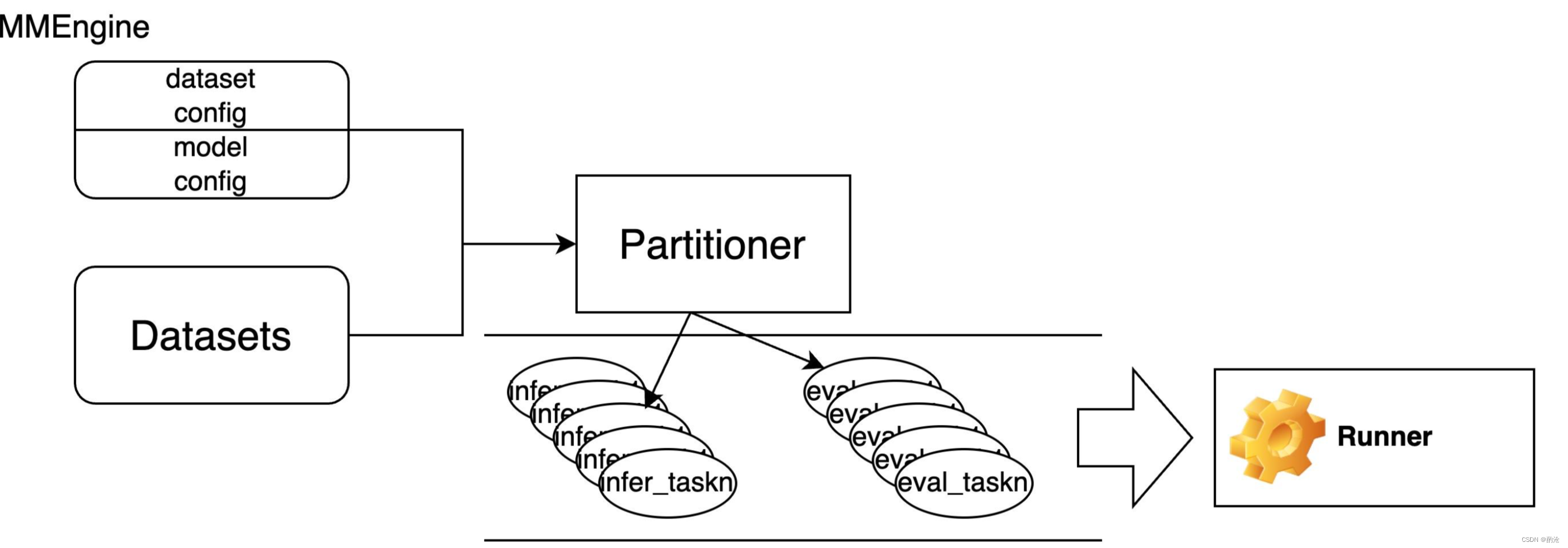
3.1 main.py核心流程
AIGC/opencompass/opencompass/cli/main.py核心流程如下
配置文件读取
args = parse_args()
cfg = get_config_from_arg(args)
infer过程
partitioner = PARTITIONERS.build(cfg.infer.partitioner)#例如NaivePartitioner
tasks = partitioner(cfg)#分割任务 可能会split数据
runner = RUNNERS.build(cfg.infer.runner)#LocalAPIRunner
runner(tasks)#LocalAPIRunner的launch方法
TASKS.build(dict(cfg=task, type=self.task_cfg['type']))#配置文件的OpenICLInferTask
OpenICLInferTask的run()包含如下内容
self.model = build_model_from_cfg(model_cfg)
self.dataset = build_dataset_from_cfg(self.dataset_cfg)
此处形成了dataset.test .train
_inference打印'Start inferencing
retriever = ICL_RETRIEVERS.build(retriever_cfg)使用dataset配置的FixKRetriever
inferencer = ICL_INFERENCERS.build(inferencer_cfg) 使用dataset配置的的GenInferencer
GenInferencer的inference方法包含如下内容
#打印'Starting inference process...'
for datum in tqdm(dataloader, disable=not self.is_main_process):#打印进度条
调用大模型进行推理过程如下
results = self.model.generate_from_template(entry, max_out_len=self.max_out_len, **extra_gen_kwargs)#推理
opencompass/opencompass/models/base.py", line 165, in generate_from_template
return self.generate(inputs, max_out_len=max_out_len, **kwargs)
opencompass/opencompass/models/Baichuan3_2B.py", line 51, in generate
output_text = self.call_external_api(input_text, max_out_len, temperature)
opencompass/opencompass/models/Baichuan3_2B.py", line 63, in call_external_api
response = langchainmain.get_gpt({'content': {'question': text, 'llm': 'Baichuan3_2B'}, 'type': '通用'}).get('res', '')
angchainmain.py", line 582, in get_gpt
globals().get(methoddict[info.get('type')])(info.get('content'))
langchainmain.py", line 218, in general_tool
data=globals().get(question['llm']).invoke(question['question'])
language_models/llms.py", line 248, in invoke
self.generate_prompt(
langchain_core/language_models/llms.py", line 569, in generate_prompt
return self.generate(prompt_strings, stop=stop, callbacks=callbacks, **kwargs)
langchain_core/language_models/llms.py", line 765, in generate
new_results = self._generate_helper(
angchain_core/language_models/llms.py", line 593, in _generate_helper
self._generate(
langchain_core/language_models/llms.py", line 1210, in _generate
self._call(prompt, stop=stop, run_manager=run_manager, **kwargs)
evaluate过程如下
partitioner = PARTITIONERS.build(cfg.eval.partitioner)
tasks = partitioner(cfg)#fill_eval_cfg(cfg, args)实现默认
runner = RUNNERS.build(cfg.eval.runner)
runner(tasks)
OpenICLEvalTask的run调用_score()
test_set = build_dataset_from_cfg(self.dataset_cfg).test加载数据集
proc = TEXT_POSTPROCESSORS.get(proc)加载处理器
test_set = test_set.map(postprocess)
preds = mmengine.load(filename)
proc = TEXT_POSTPROCESSORS.get(proc)
icl_evaluator = ICL_EVALUATORS.build(self.eval_cfg['evaluator'])
result = icl_evaluator.score(**preds)
mmengine.dump(result, out_path, ensure_ascii=False, indent=4)#保存评估结果到result文件
AccEvaluator的score方法
scores = metric.compute(**self._preprocess(predictions, references))
result = self._postprocess(scores)
可视化过程如下
summarizer_cfg['config'] = cfg
summarizer = build_from_cfg(summarizer_cfg)
summarizer.summarize(time_str=cfg_time_str)
summarize方法保护如下内容
_pick_up_results
_calculate_group_metrics
_format_table
_format_raw_txt
# output to screen
print(tabulate.tabulate(table, headers='firstrow', floatfmt='.2f'))
# output to .text / .csv files
self._output_to_file(output_path, time_str, table, raw_txts)
整个流程中有2个地方设置并发
- task并发 opencompass/opencompass/runners/local_api.py
# run in subprocess if starts with torchrun etc.
if cmd.startswith('python'):
task.run()
else:
task.run()
#subprocess.run(cmd, shell=True, text=True)
with Pool(processes=self.max_num_workers) as pool:
for task in tasks:
pool.apply_async(submit,
(task, self.task_cfg['type'], tokens),
callback=update)
pool.close()
- 数据集并发 opencompass/opencompass/openicl/icl_inferencer/icl_gen_inferencer.py
dataloader = self.get_dataloader(prompt_list[index:], self.batch_size)
results = self.model.generate_from_template(entry, max_out_len=self.max_out_len, **extra_gen_kwargs)
其中entry就是下面opencompass/opencompass/models/ZTB.py的inputs
with ThreadPoolExecutor() as executor:
results = list(
executor.map(self._generate, inputs,
[max_out_len] * len(inputs)))
3.2 加载配置文件
eval_api_360.py配置文件示例如下 这段配置定义了推理过程中使用的各个组件:
partitioner: 使用类型为 NaivePartitioner 的分区器,负责将数据分成多个部分以并行处理。
runner: 使用 LocalAPIRunner 作为运行器,它控制如何执行分配给它的任务。
max_num_workers: 指定并发工作的最大工作者数量。
concurrent_users: 设定同时处理的用户数量。
task: 指定任务类型,这里是 OpenICLInferTask,负责定义具体的推理任务逻辑。
datasets = [
*ceval_datasets,
]
models = [
dict(
abbr='360GPT_S2_V9',
type=AI360GPT
]
infer = dict(
partitioner=dict(type=NaivePartitioner),
runner=dict(
type=LocalAPIRunner,
max_num_workers=2,
concurrent_users=2,
task=dict(type=OpenICLInferTask)),
)
opencompass/registry.py用到的主要注册器
PARTITIONERS = Registry('partitioner', locations=['opencompass.partitioners'])
RUNNERS = Registry('runner', locations=['opencompass.runners'])
TASKS = Registry('task', locations=['opencompass.tasks'])
MODELS = Registry('model', locations=['opencompass.models'])
LOAD_DATASET = Registry('load_dataset', locations=['opencompass.datasets'])
opencompass/opencompass/cli/main.py
cfg = Config.fromfile(output_config_path)
这里加载了全部的配置 cfg的值很多 如下
其中summarizer来自AIGC/opencompass/configs/summarizers/medium.py 用于可视化的时候显示表格的第一列
Config (path: configs/api_examples/eval_Nebulacoder.py): {'summarizer': {'dataset_abbrs': ['--------- 考试 Exam ---------', 'ceval', 'agieval', 'mmlu', 'GaokaoBench', 'ARC-c', '--------- 语言 Language ---------', 'WiC', 'summedits', 'chid-dev', 'afqmc-dev', 'bustm-dev', 'cluewsc-dev', 'WSC', 'winogrande', 'flores_100', '--------- 知识 Knowledge ---------', 'BoolQ', 'commonsense_qa', 'nq', 'triviaqa', '--------- 推理 Reasoning ---------', 'cmnli', 'ocnli', 'ocnli_fc-dev', 'AX_b', 'AX_g', 'CB', 'RTE', 'story_cloze', 'COPA', 'ReCoRD', 'hellaswag', 'piqa', 'siqa', 'strategyqa', 'math', 'gsm8k', 'TheoremQA', 'openai_humaneval', 'mbpp', 'bbh', '--------- 理解 Understanding ---------', 'C3', 'CMRC_dev', 'DRCD_dev', 'MultiRC', 'race-middle', 'race-high', 'openbookqa_fact', 'csl_dev', 'lcsts', 'Xsum', 'eprstmt-dev', 'lambada', 'tnews-dev'], 'summary_groups': [{'name': 'agieval-chinese', 'subsets': ['agieval-gaokao-chinese', 'agieval-gaokao-english', 'agieval-gaokao-geography', 'agieval-gaokao-history', 'agieval-gaokao-biology', 'agieval-gaokao-chemistry', 'agieval-gaokao-physics', 'agieval-gaokao-mathqa', 'agieval-logiqa-zh', 'agieval-jec-qa-kd', 'agieval-jec-qa-ca', 'agieval-gaokao-mathcloze']}, {'name': 'agieval-english', 'subsets': ['agieval-lsat-ar', 'agieval-lsat-lr', 'agieval-lsat-rc', 'agieval-logiqa-en', 'agieval-sat-math', 'agieval-sat-en', 'agieval-sat-en-without-passage', 'agieval-aqua-rat', 'agieval-math']}, {'name': 'agieval-gaokao', 'subsets': ['agieval-gaokao-chinese', 'agieval-gaokao-english', 'agieval-gaokao-geography', 'agieval-gaokao-history', 'agieval-gaokao-biology', 'agieval-gaokao-chemistry', 'agieval-gaokao-physics', 'agieval-gaokao-
3.3 推理
任务被划分为较小的块 (chunks),每个块包含一部分数据集,这些块进一步组织成任务 (task) 对象,并被添加到任务列表中。
opencompass/opencompass/cli/main.py
partitioner = PARTITIONERS.build(cfg.infer.partitioner)
tasks = partitioner(cfg)
runner = RUNNERS.build(cfg.infer.runner)
runner(tasks)
其中partitioner(cfg)调用AIGC/opencompass/opencompass/partitioners/base.py的__call__方法里的
model_and_dataset_args = self.parse_model_dataset_args(cfg)
tasks = self.partition(**model_and_dataset_args,
work_dir=work_dir,
out_dir=self.out_dir,
add_cf 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 417
417

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









