







常用的内部排序算法主要分为五类:插入、交换、选择、归并、基数排序。
插入:直接插入、折半插入、希尔排序。
交换:冒泡、快速排序。
选择:简单选择、堆排序。
归并:2路归并排序。
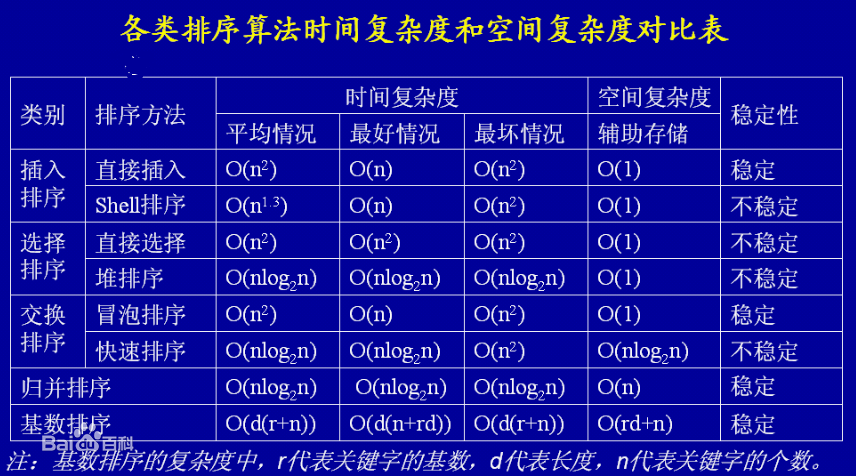
内部排序比较:
(1)时间复杂度达到O(nlgn) 的排序算法有:快速排序、堆排序、归并排序。
(2)排序算法稳定性
不稳定的排序有:希尔排序、快速排序、堆排序、简单的选择排序。
稳定的排序有:插入排序(除希尔外)、冒泡排序、归并排序。
(3)从平均时间性能而言,快速排序最佳,其所需要的时间最少,但快速排序在最坏的情况下,时间性能还不如堆排序和归并排序。
整体如图:
1、插入排序
插入排序特性:
1)时间复杂度,除希尔排序是O(n的3/2次方)外,其它的都是O(n平方)。
2)除希尔排序外,其它的排序都是稳定的。(稳定是指相同的两个数在排序之后它们的相对位置不变。)
(1)直接插入排序
这是最简单的排序方法,它的基本基本操作是将一个记录插入到已排好序的有序表中,从而得到一个新的、记录数增加1的有序表。
#include<iostream>
using namespace std;
int main()
{
int src[] = {49,38,65,97,76,13,27,49};
int i,j,cnt = sizeof(src)/4;
int guard = src[0]; //设置一个哨兵,用来记录当前值
for(i = 1; i < cnt; i ++)
{
if(src[i] < src[i-1])
{
guard = src[i];
src[i] = src[i-1];
for(j = i - 2; src[j]>guard; j --) src[j+1] = src[j];
src[j+1] = guard;
}
}
for(i = 0; i < cnt; i ++) cout<<src[i]<<endl;
//getchar();
return 0;
}
(2)折半插入排序
这种插入排序是上一种排序的改进,就是在查找的时候不用一个一个对比,因为前面已经有序,所以可以用折半法。
#include<iostream>
using namespace std;
int main()
{
int src[] = {49,38,65,97,76,13,27,49};
int i,j,low,high,mid,cnt = sizeof(src)/4;
int guard = src[0];
for(i = 1; i < cnt; i ++)
{
if(src[i] < src[i-1])
{
guard = src[i];
low = 0, high = i - 1;
while(low <= high)
{
mid = (low+high)/2;
if(guard < src[mid]) high = mid - 1;
else low = mid+1;
}
for(j = i - 1; j >= high +1; j --) src[j+1] = src[j]; //后移
src[j+1] = guard;
}
}
for(i = 0; i < cnt; i ++) cout<<src[i]<<endl;
//getchar();
return 0;
} (3)希尔排序
希尔排序也称为递减增量排序。
设计是:跨度递减的直接插入排序,最后跨度是1(也就是简单直接插入排序)。
以 int src[] = {49,38,65,97,76,13,27,49_,55,4} 为例,共有10个数,
我们先以10/2=5为跨度,进行第一趟排序。
第一趟:
49和13比较,38和27比较,65和49_比较,97和55比较,76和4比较,得:
13,27,49_,55,4,49,38,65,97,76 (从这里可以看出,希尔排序是不稳定的,当然下结论前还要看最后的结果。)
第二趟,我们以5-2=3为跨度,进行排序,可得:
13,4,49_,38,27,49,55,65,97,76 (到这时一看,有序多了)
第三趟,心3-2=1为跨度,进行排序,得:
4,13,27,38,49_,49,55,65,76,97
当跨度减小到1时,就算是排序结束了。由结果可以断定,希尔排序是不稳定的排序。
#include<iostream>
using namespace std;
int main()
{
int src[] = {49,38,65,97,76,13,27,49,55,4}; //大家可试一试奇数个的情况
int i,j,tmp,cnt = sizeof(src)/4,dk = (cnt+1)/2,c=1;
while(dk > 0)
{
cout<<c++<<endl;
for(i = 0; i < cnt; i ++) cout<<src[i]<<" ";
cout<<endl;
for(i = dk; i < cnt; i +=dk)
{
if(src[i] < src[i-dk])
{
tmp = src[i];
src[i] = src[i-dk];
src[i-dk] = tmp;
}
}
dk = dk - 2 == 0 ? 1:dk-2;
}
cout<<c<<endl;
for(i = 0; i < cnt; i ++) cout<<src[i]<<" ";
cout<<endl;
getchar();
return 0;
} 步长选择:
步长的选择是希尔排序的重要部分。只要最终步长为1任何步长序列都可以工作。算法最开始以一定的步长进行排序。然后会继续以一定步长进行排序,最终算法以步长为1进行排序。当步长为1时,算法变为插入排序,这就保证了数据一定会被排序。
Donald Shell 最初建议步长选择为n/2并且对步长取半直到步长达到 1。虽然这样取可以比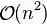
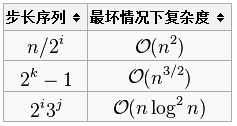
已知的最好步长序列是由Sedgewick提出的 (1, 5, 19, 41, 109,...),该序列的项来自 9 * 4^i - 9 * 2^i + 1 和 4^i - 3 * 2^i + 1 这两个算式.这项研究也表明“比较在希尔排序中是最主要的操作,而不是交换。”用这样步长序列的希尔排序比插入排序和堆排序都要快,甚至在小数组中比快速排序还快,但是在涉及大量数据时希尔排序还是比快速排序慢。
2、交换排序
(1)冒泡排序
设计是:相邻的两个数,两两相互比较,其特点是:每比较一次就可以得出最小/大的一个数 放到队首或队尾。平均时间复杂度:
#include<iostream>
using namespace std;
int main()
{
int src[] = {49,38,65,97,76,13,27,49};
int i,j,cnt = sizeof(src)/4;
for(i = 0; i < cnt; i ++)
for(j = cnt-1; j > i; j --)
if(src[j] < src[j-1]) swap(src[j],src[j-1]);
//输出
for(i = 0; i < cnt; i ++) cout<<src[i]<<" ";
cout<<endl;
getchar();
return 0;
} 冒泡排序对 个成员需要
个成员需要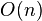
(2)快速排序
快速排序的时间复杂度达到O(nlgn),被公认为最快的排序方法之一。在所有同数量级(O(nlgn))的排序当中,其平均性能最好。它其实是冒泡排序的改进,当一列数据基本有序的时候,快速排序将为蜕化为冒泡排序,时间复杂度为O(n平方)。基本思想是 取一个数作为中间数,比它小的都排左边,比它大的都排右边(如果是从大到小排序的话,就反过来),再对每一边用同样的思路进行递归求解。快速排序是不稳定的排序方式。
#include<iostream>
using namespace std;
void quickSort(int *src, int low,int high)
{
if(src == NULL) return ;
int i,j,pivot;
if(low < high)
{
pivot = src[low];
i = low,j = high;
while(i < j)
{
while(i<j && src[j] >= pivot) j--;
src[i] = src[j];
while(i<j && src[i] <= pivot) i++;
src[j] = src[i];
}
src[i] = pivot;
quickSort(src,low,i-1);
quickSort(src,i+1,high);
}
}
int main()
{
int src[] = {49,38,65,97,76,13,27,49};
int i,low,high,cnt = sizeof(src)/4;
quickSort(src,0,cnt-1);
//输出
for(i = 0; i < cnt; i ++) cout<<src[i]<<" ";
cout<<endl;
getchar();
return 0;
}
3、选择排序
(1)简单选择排序
思路很简单,就是每次选出最小/大的数,和前面的第i个数交换。时间复杂度也是 O(n平方),是不稳定的排序方式,因为在交换的过程中,相同的两个数,前者有可能被交换到后面去,举个例子,序列5 8 5 2 9, 我们知道第一遍选择第1个元素5会和2交换,那么原序列中2个5的相对前后顺序就被破坏了,所以选择排序不是一个稳定的排序算法。
#include<iostream>
using namespace std;
int main()
{
int src[] = {49,38,65,97,76,13,27,49};
int i,j,cnt = sizeof(src)/4,min ,index;
for(i = 0; i < cnt; i ++)
{
min = INT_MAX,index = -1;
for(j = i; j < cnt; j ++)
{
if(min > src[j])
{
min = src[j];
index = j;
}
}
if(index != i)
{
src[index] = src[i];
src[i] = min;
}
}
//输出
for(i = 0; i < cnt; i ++) cout<<src[i]<<" ";
cout<<endl;
getchar();
return 0;
}
(2)堆排序
步骤:
1)构造大根堆(特殊的完全二叉树),从下标为cnt/2(cnt指给定的数的个数)成员开始(下次下标是cnt/2-1,一直往前,直到0),和它的子结点比较,较大的子节点比本节点大的就往上挪。
2)交换堆顶成员和最后一个数放入堆顶。
3) 调整一次大根堆
我们可以用一个数组来顺序地表示这棵树,左孩子可以通过2*n来找到,右孩子可以通过2*n+1来找到。
例子如下:
int src[] = {49,38,65,97,76,13,27,49};

堆排序的时间复杂度是O(nlgn),也是最快的排序方法之一,在最坏的情况下,其时间复杂度还是O(nlgn),相对于快速排序来说,这是堆排序的最大优点。此外,堆排序仅需要一个记录大小供交换用的辅助存储空间。堆排序也是不稳定的排序。
#include<iostream>
using namespace std;
void heapAdjust(int *src, int s,int m)
{ //从s开始进行一次调整,其中m指向需要进行排序的数据中最大的下标
if(src == NULL) return;
int i,rc = src[s];
for(i = 2*s+1; i <= m; i = 2*i+1) //一层一层往下走
{
if(i<m && src[i] < src[i+1]) i++; //让i指向最大的那个孩子
if(rc >= src[i]) break;
src[s] = src[i];
s = i;
}
src[s] = rc;
}
int main()
{
int src[] = {49,38,65,97,76,13,27,49,1};
int i,j,cnt = sizeof(src)/4;
//先构建一个大顶堆(从cnt/2开始往前,子节点大的节点会移到父节点)
for(i = cnt/2-1; i >-1; i --)
heapAdjust(src,i,cnt-1);
//每次取出顶部最大的那个数放后面,再进行一次顶点调整
for(i = cnt-1; i > 0; i --)
{
swap(src[0],src[i]);
heapAdjust(src,0,i-1);
}
//输出
for(i = 0; i < cnt; i ++) cout<<src[i]<<" ";
cout<<endl;
getchar();
return 0;
}
4、归并排序
归并的意思就是两个或两个以上的有序表组合成一个新的有序表。整个归并排序需要进行【lgn取上限】次,总的时间复杂度为O(nlgn)。与快速排序相比,归并排序的最大特点是:它是一种稳定的排序方法。

如上图,这是一种2-路归并排序,通常用递归方法来实现,递归的形式的算法在形式上较简洁,但实用性很差。
#include<iostream>
using namespace std;
//临时的空间的指针
int *des = NULL;
void merge(int* src,int i,int m,int n)
{
int k = i,mm = m++,low = i;
//把数组的两部分,一个一个地放入临时数组中,小的先放
while(i <= mm && m <= n)
if(src[i] <= src[m]) des[k++] = src[i++];
else des[k++] = src[m++];
//把剩余的放入数组
while(i <= mm) des[k++] = src[i++];
while(m <= n) des[k++] = src[m++];
//把结果拷贝回原数组
for(k = low; k <= n; k++) src[k] = des[k];
}
void mergeSort(int* src, int s, int t)
{
if(src == NULL) return ;
int m;
if(s < t)
{
m = (s+t)/2; //取中间值
mergeSort(src,s,m); //递归地将src[s..m]归并为有序的des[s..m]
mergeSort(src,m+1,t); //递归地将src[m+1..t]归并为有序的des[m+1..t]
merge(src,s,m,t);
}
}
int main()
{
int src[] = {49,38,65,97,76,13,27,49};
//临时的空间来存放归并后的结果
des = (int*)malloc(sizeof(src));
int i,j,cnt = sizeof(src)/4;
mergeSort(src,0,cnt-1);
//输出
for(i = 0; i < cnt; i ++) cout<<src[i]<<" ";
cout<<endl;
getchar();
free(des);
return 0;
} 5、基数排序
基数排序是一种非比较型整数排序算法,其原理是将整数按位数切割成不同的数字,然后按每个位数分别比较。由于整数也可以表达字符串(比如名字或日期)和特定格式的浮点数,所以基数排序也不是只能使用于整数。基数排序的方式可以采用LSD(Least significant digital)或MSD(Most significant digital),LSD的排序方式由键值的最右边开始,而MSD则相反,由键值的最左边开始。经典例子就是数字的编排,先按最高位排序,再按次高位,以此类推.
时间效率:设待排序列为n个记录,d个关键码,关键码的取值范围为radix,则进行链式基数排序的 时间复杂度 为O(d(n+radix)),其中,一趟分配时间复杂度为O(n),一趟收集时间复杂度为O(radix),共进行d趟分配和收集。 空间效率:需要2*radix个指向队列的辅助空间,以及用于 静态链表 的n个 指针 。是稳定排序。
如果考虑和比较排序进行对照,基数排序的形式复杂度虽然不一定更小,但由于不进行比较,因此其基本操作的代价较小,而且在适当选择的d和radix之下,所以基数排序一般要快过基于比较的排序,比如快速排序。
#include<iostream>
#include<malloc.h>
using namespace std;
int *reorderArr =NULL;
inline int getBucket(int x,int d)//获取桶号
{
static int a[] = {1, 10,100,1000};
return ((x / a[d-1]) % 10); //确定桶号
}
void PrintArr(int ar[],int n)
{
for(int i = 0; i < n; ++i)
cout<<ar[i]<<" ";
cout<<endl;
}
//基数排序(参数:数组地址,开始下标,结束下标,数的最大位数)
void msdradix_sort(int arr[],int begin,int end,int d)
{
const static int radix = 10;
int bucketObjCount[radix+1],i, j;
//置空桶数据
bzero(bucketObjCount,sizeof(bucketObjCount));
//统计各桶需要装的元素的个数
for(i = begin;i <= end; ++i)
{
int bu = getBucket(arr[i], d);//桶的号码,从高位到低位的计算
bucketObjCount[bu]++; //遍历所有的数,计算桶内的数的个数
}
//求出桶的边界索引,count[i]值为第i个桶的左界索引,count[i+1]-1是i桶的右边界索引
for(i = 1; i < radix; ++i)
{
bucketObjCount[i] += bucketObjCount[i-1];
}
//这里要从右向左扫描,保证排序稳定性
bucketObjCount[radix] = bucketObjCount[radix-1];//数被减去后会往后移动一位,所以需要保存最后一位
for(i = end;i >= begin; --i)
{
j = getBucket(arr[i], d); //求出关键码的第d位的数字的桶号(例如:576的第3位是5)
reorderArr[bucketObjCount[j]-1] = arr[i]; //放入对应的桶中,count[j]-1是第j个桶的右边界索引
--bucketObjCount[j]; //第j个桶放下一个元素的位置(右边界索引+1),下一次该桶中的数就往前放了
}
//注意:此时count[i]为第i个桶左边界
//从各个桶中收集数据
for(i = begin, j = 0;i <= end; ++i, ++j)
{
arr[i] = reorderArr[j];//把收集来的数重新付给原来的数组
}
//对各桶中数据进行再排序
int p1,p2;
for(i = 0;i < radix; ++i)/* 0 -9 桶*/
{
p1 = begin + bucketObjCount[i]; //第i个桶的左边界
p2 = begin + bucketObjCount[i+1]-1; //第i个桶的右边界
if(p1 < p2 && d > 1)
{
msdradix_sort(arr, p1, p2, d-1); //对第i个桶递归调用,进行基数排序,数位降 1
}
}
}
int main()
{
int ar[] = {12, 14, 54, 5, 6, 3, 9, 8, 47, 89,91,90,89,77,23};
int len = sizeof(ar)/sizeof(ar[0]);
//分配桶存储空间
reorderArr = (int *) malloc(sizeof(ar));
cout<<"排序前数据如下:"<<endl;
PrintArr(ar, len);
msdradix_sort(ar, 0, len-1, 2);
cout<<"排序后结果如下:"<<endl;
PrintArr(ar, len);
//释放存储空间
free(reorderArr);
return 0;
}
输出结果:
排序前数据如下:
12 14 54 5 6 3 9 8 47 89 91 90 89 77 23
排序后结果如下:
3 5 6 8 9 12 14 23 47 54 77 89 89 90 91















 607
607

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









