







LSTM-Long Short-Term Memory
0 摘要
周期性的反向传播学习,在扩展的时间间隔内存储信息需要很长的时间,这主要是由于不确定的、衰减的错误导致的。我们简要回顾了Hochreiter在1991年对这个问题的分析,然后介绍了一种新颖的、独特的、基于梯度的方法,称为LSTM (LSTM)。在不造成伤害的情况下截断梯度,LSTM可以学习在超过1000个离散时间步长的最小时间滞后上桥接,方法是通过在特殊unit内的“恒定误差轮盘”强制执行恒定误差。乘性门unit学习打开和关闭访问的恒定误差低。LSTM在空间和时间上都是局部的;其每时间步长的计算复杂度和权值为O(1)。我们对人工数据的实验包括局部的、分布式的、实值的和有噪声的模式表示。在与RTRL、BPTT、周期性级联相关、Elman网和神经序列分块的比较中,LSTM带来了更多的成功运行,并且学习速度更快。LSTM还解决了以前的递归网络算法所不能解决的复杂、人工的长时间滞后问题。
1 介绍
递归网络原则上可以使用它们的反馈连接以激活的形式存储最近输入事件的表示(“短期记忆”,而不是“长期记忆”,后者由缓慢变化的权重表示)。这对许多应用程序都有潜在的重要性,包括语音处理、非马尔可夫控制和音乐作曲(例如,Mozer 1992)。然而,最广泛使用的学习短期记忆的算法要么花费了太多时间,要么根本就不能很好地工作,尤其是在输入和相应教师信号之间的最小时滞很长时。虽然理论上很吸引人,但现有的方法并没有提供明显的实际优势,例如,在有限时间窗口的前馈网络中,backprop。本文将对这一问题进行分析,并提出解决办法。
这个问题。与传统\反向传播通过时间”(BPTT,例如,1992年威廉姆斯和拉链,Werbos 1988)或\实时复发性学习”(RTRL,例如,罗宾逊和Fallside 1987),误差信号在时间上向后\由于”倾向于(1)炸毁或(2):消失的时间演化backpropagated误差指数的大小取决于重量(Hochreiter 1991)。情形(1)可能会导致权值的振荡,而情形(2)学习如何桥接长时间滞后的情况会花费大量的时间,或者根本不起作用(参见第3节)。
补救措施。本文提出了一种新的递归网络结构——长短时记忆(LSTM),并结合适当的梯度学习算法。LSTM的设计就是为了克服这些错误的反向问题。它可以学习桥接超过1000步的时间间隔,即使在有噪声、不可压缩的输入序列的情况下,也不会损失短时间延迟能力。这是通过一种特殊的、基于梯度的算法来实现的,它针对的是一种通过特殊unit的内部状态来执行常量(因此既不会爆炸也不会消失)的错误(假设梯度计算在某些特定的体系结构点|被截断,但这并不影响长期的错误)。
第二部分将简要回顾以前的工作。第3节以详细分析Hochreiter(1991)所造成的消失误差的大纲开始。然后,它将介绍一种用于教学目的的幼稚的不断错误支持方法,并突出其在信息存储和检索方面的问题。这些问题将导致第4节中描述的LSTM体系结构。第5节将提供大量的实验和与竞争方法的比较。LSTM比它们做得更好,而且还学会了解决复杂的人工任务,这是其他递归网络算法所不能解决的。第6节将讨论LSTM的局限性和优点。附录中有算法的详细描述(a .1),以及公式的显式误差(a .2)。
2 先前工作
本节将集中讨论具有时变输入的递归网络(而不是具有固定输入和基于x点的梯度计算的网络,例如Almeida 1987和Pineda 1987)。
Gradient-descent variants梯度下降法变体。Elman(1988)、Fahlman(1991)、Williams(1989)、Schmidhuber (1992a)、Pearlmutter(1989)的方法,以及Pearlmutter的综合综述(1995)中的许多相关算法,都是从与BPTT和RTRL相同的问题中提出的(见第1节和第3节)
Time-delays时间延迟。其他似乎只适用于短时间滞后的方法有时滞神经网络(Lang et al. 1990)和Plate法(Plate 1993),后者基于旧激活的加权和更新单位激活(参见de Vries和Principe 1991)。Lin等人(1995)提出了时延网络的变体NARX网络。
Time constants时间常量。为了处理长时间滞后,Mozer(1992)使用时间常数来表示单位激活的变化(deVries and Principe’s上述方法(1991)实际上可以看作是TDNN和时间常数的混合物)。然而,对于长时间滞后,时间常数需要外部ne调谐(Mozer 1992)。Sun等人的替代方法(1993)通过添加旧的激活和(缩放的)当前净输入来更新一个经常性unit的激活。然而,净输入往往会干扰所存储的信息,这使得长期存储变得不切实际。
Ring's approach环的方法。Ring(1993)也提出了一种桥接长时间滞后的方法。当他的网络中的一个unit接收到通信错误信号时,他就增加一个更高阶的unit来建立适当的连接。虽然他的方法有时非常快,但要跨越100步的时间延迟可能需要增加100个unit。同样,环网也不能推广到看不见的滞后时间。
Bengio等人的方法。Bengio等人(1994)研究了模拟退火、多网格随机搜索、时间加权伪牛顿优化和离散误差传播等方法。他们的“闩锁”和“2-序列”问题与3a问题非常相似,只有最小的滞后时间100(见实验3)。Bengio和Frasconi(1994)也提出了一种EM方法来传播目标。对于n个所谓的“状态网络”,在给定的时间内,它们的系统只能处于n种不同状态中的一种。参见第5节的开头。但是,为了解决诸如“\添加问题”(第5.4节)之类的连续问题,它们的系统将需要不可接受的状态数(即状态的网络)。
Kalman filters. Puskorius and Feldkamp (1994)使用Kalman lter技术来提高经常性净绩效。由于他们使用一个衍生品折扣因子来指数衰减过去动态衍生品的影响,“我们没有理由相信他们的卡尔曼滤波训练的递归网络在很长一段时间内都是有用的。”二阶网络。我们将看到LSTM使用乘法单位(MUs)来保护错误不受不必要的干扰。但它不是第一个使用MUs的递归网络方法。例如:
(1)Watrous和Kuhn(1992)在二阶网中使用MUs。LSTM的一些不同之处是:(1)Watrous和Kuhn的架构不强制恒定的错误,也不是为了解决长时间滞后的问题而设计的。
(2)它具有完全连通的二阶sigma-piunit,而LSTM体系结构的MUs仅用于对恒定误差低的门访问。
(3) Watrous和Kuhn的算法每时间步需要O(W2)个操作,我们的算法只需要O(W)个操作,其中W是权值的个数。有关MUs的其他工作也见Miller和Giles(1993)。
简单的猜测。为了避免基于梯度的方法的长时间滞后问题,我们可以简单地随机初始化所有网络权值,直到最终得到的网络正确地对所有训练序列进行分类。事实上,最近我们发现(Schmidhuber and Hochreiter 1996, Hochreiter and Schmidhuber 1996, 1997)简单的重量猜测解决了(Bengio 1994, Bengio and Frasconi 1994, Miller and Giles 1993, Lin et al. 1995)中的许多问题,比其中提出的算法更快。这并不意味着猜测权重是一个好的算法。这意味着问题很简单。更实际的任务需要许多自由参数(例如,输入权值)或较高的权值精度(例如,连续值参数),这样猜测就变得完全不可行的。
自适应序列chunkers。Schmidhuber的分层chunker系统(1992b, 1993)确实具有桥接任意时间滞后的能力,但前提是子序列具有局部可预测性,从而导致时间滞后(参见Mozer 1992)。例如,在他的博士后论文(1993)中,Schmidhuber使用层次递归网络来快速解决某些语法学习任务,这些任务涉及的时间延迟最小,超过了1000步。然而,随着噪声水平的提高和输入序列的可压缩性的降低,chunker系统的性能会下降。LSTM不能解决这个问题。
3 CONSTANT ERROR BACKPROP 固定误差支持
3.1 EXPONENTIALLY DECAYING ERROR 指数衰减误差
传统的BPTT(如Williams和Zipser 1992)。输出unitk在t时刻的目标用dk(t)表示,利用均方误差,k的误差信号为:

对wjl的总权重更新的相应贡献是![]() ,其中,α是学习率,l代表连接到unitj的任意unit。
,其中,α是学习率,l代表连接到unitj的任意unit。
Hochreiter分析的纲要(1991年,第19-21页)。 假设我们有一个完全连接的网络,其非输入单位索引的范围是1到n。让我们关注从unitu到unitv的局部错误流(稍后我们将看到分析立即扩展到全局错误流)。在时间步长t处以任意单位u出现的误差将“返回时间”传播q个时间步长到任意单位v。这将通过以下因素来缩放误差:
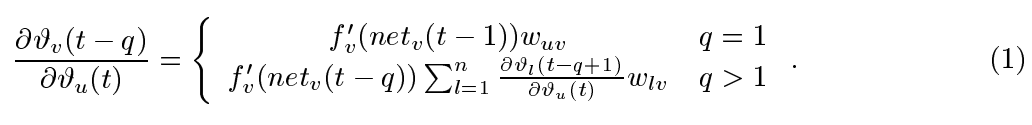

(归纳证明)。nq-1项![]() 之和确定总误差回流(注意,由于求和项可能具有互符号,因此增加unitn的数目不一定增加误差流)。
之和确定总误差回流(注意,由于求和项可能具有互符号,因此增加unitn的数目不一定增加误差流)。
Intuitive explanation of equation(方程的直观解释)
如果:![]()
对于所有m(可能会发生,例如使用线性flm),则最大乘积随q呈指数增长。 就是说,错误爆发,并且错误信号到达unitv会导致权重振荡和学习不稳定(关于错误爆发或分叉,另请参见Pineda 1988,Baldi和Pineda 1991,Doya 1992)。 另一方面,如果
![]()
对于所有m,则最大乘积随q呈指数下降。即,错误消失了,并且在可接受的时间内什么也没学到。
如果flm是logistic sigmoid函数,则film的最大值为0.25。如果ylm-1是常数且不等于零,则![]() 取最大值,其中
取最大值,其中
对于![]() 变为零,对于
变为零,对于![]() (例如,如果绝对最大重量值wmax小于4.0)。因此,对于传统的逻辑sigmoid activation函数,只要权重的绝对值低于4.0,误差流就趋于消失,尤其是在训练阶段的开始。通常,使用较大的初始权重将无济于事。如上所示,对于
(例如,如果绝对最大重量值wmax小于4.0)。因此,对于传统的逻辑sigmoid activation函数,只要权重的绝对值低于4.0,误差流就趋于消失,尤其是在训练阶段的开始。通常,使用较大的初始权重将无济于事。如上所示,对于![]() ,相关的导数“faster”到零,比绝对权重可以增长的速度快(同样,某些权重将不得不越过零来改变其符号)。同样,提高学习率也无济于事|它将 BPTT对最近的干扰过于敏感(Bengio等人,1994年提出了一个非常类似的,最近的分析)。
,相关的导数“faster”到零,比绝对权重可以增长的速度快(同样,某些权重将不得不越过零来改变其符号)。同样,提高学习率也无济于事|它将 BPTT对最近的干扰过于敏感(Bengio等人,1994年提出了一个非常类似的,最近的分析)。
Global error flow。上面的局部错误流分析立即显示,全局错误流也消失了。要看到这一点,计算:
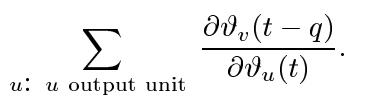
Weak upper bound for scaling factor。以下略微扩展的消失误差分析也将n个单位数考虑在内。对于q> 1,公式(2)可以重写为:

其中权重矩阵W由[W] ij:= wij定义,v的输出权重矢量Wv由[Wu] i:= [W]iv =wjv定义,u的输入权重矢量WuT由[WuT] i:= [W]ui=定义,并且![]() 是一阶导数的对角矩阵定义为:
是一阶导数的对角矩阵定义为:![]()
![]() ,否则。这里T是换位算子,[A]ij是矩阵A的第i列和第j行的元素,[x] i是向量x的第i分量。
,否则。这里T是换位算子,[A]ij是矩阵A的第i列和第j行的元素,[x] i是向量x的第i分量。
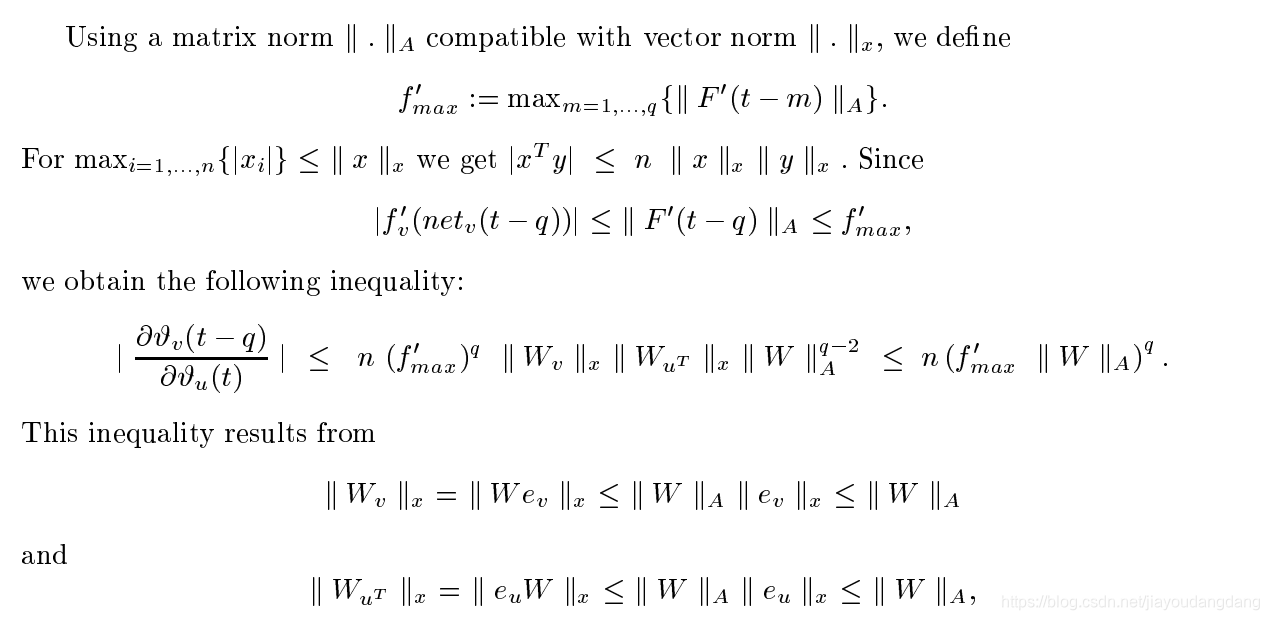
其中ek是单位向量,其第k个分量除外,其分量为0,为1。请注意,这是一个弱的极端情况上限仅当所有![]() 都取最大值,并且误差从单位u流回到单位v的所有路径的贡献具有相同的符号时,才可以达到此目标。然而,如实验所证实的,较大的
都取最大值,并且误差从单位u流回到单位v的所有路径的贡献具有相同的符号时,才可以达到此目标。然而,如实验所证实的,较大的![]() 通常导致较小的
通常导致较小的![]() 值(参见,例如,Hochreiter 1991)。
值(参见,例如,Hochreiter 1991)。
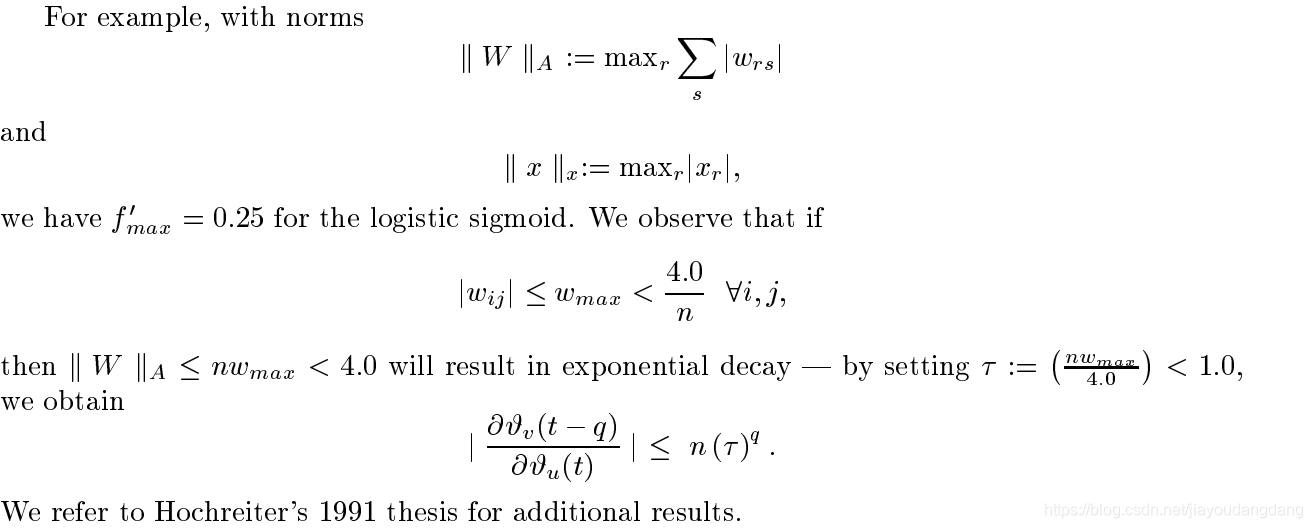
3.2 CONSTANT ERROR FLOW: NAIVE APPROACH
A single unit. 为了避免错误信号消失,我们如何通过具有单个连接的单个unitj来获得恒定的误差?根据上述规则,在时间t处,j的局部错误回流为![]() 。为了强制通过j产生恒定误差,我们要求:
。为了强制通过j产生恒定误差,我们要求:
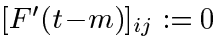
注意与Mozer的固定时间常数系统(1992)相似。 1.0的时间常数适用于潜在的无限时滞。
The constant error carrousel。整合上面的微分方程式,我们得到,对于任意netj(t)的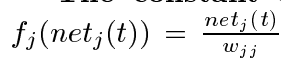 。这意味着:fj必须是线性的,并且unitj的激活必须保持恒定:
。这意味着:fj必须是线性的,并且unitj的激活必须保持恒定:
在实验中,利用恒等函数fj: fj (x) = x, ∀x来保证;设置wjj = 1.0。我们称之为常误差卡鲁塞尔(constant error carrousel CEC)。CEC将是LSTM的中心特性(参见第4节)。
当然,unitj不仅与自身相连,还与其他unit相连。这引发了两个明显的、相关的问题(也是所有其他基于梯度的方法所固有的):
- 输入权重冲突:为简单起见,让我们集中讨论一个附加的输入权重wji。 假设可以通过响应某个输入接通单元j并使其长时间处于活动状态(直到有助于计算所需的输出)来减小总误差。假设i不为零,由于必须使用相同的输入权重来存储某些输入并忽略其他输入,因此wji在此期间通常会收到冲突的权重更新信号(回想j是线性的):这些信号将尝试使wji参与 在(1)中存储输入(通过打开j)和(2)保护输入(通过防止j被无关紧要的后续输入切换为o)。 这种冲突使学习变得困难,并需要通过输入权重来控制“写操作”的更上下文相关的机制。
- 输出权重冲突:假设j已打开并且当前存储了一些先前的输入。为简单起见,让我们集中讨论一个额外的输出权重wkj。必须使用相同的wkj既要在某些时间检索j的内容,又要防止j在其他时间干扰k。只要单位j不为零,wkj就会吸引序列处理过程中产生的有争议的权重更新信号:这些信号将试图使wkj参与(1)访问存储在j中的信息,并且——在不同的时间——(2)保护单元k不受j的干扰。例如,对于许多任务,某些“短时滞错误”可以在早期训练阶段减少。但是,在以后的训练阶段,j可能会通过试图参与减少更多困难的“长时间滞后误差”而突然开始在本来可以控制的情况下引起可避免的误差。同样,这种冲突使学习变得困难,并需要一种更上下文相关的机制来通过输出权重控制“读取操作”。
当然,输入和输出权重冲突并不是长时间的延迟所特有的,而是在短时间的延迟中才发生的。但是,在长时间滞后的情况下,它们的作用尤为明显:随着时间滞后的增加,(1)必须保护存储的信息免受越来越长时间的干扰,并且-尤其是在学习的高级阶段-(2)越来越多的正确输出也需要采取防扰措施。
由于上述问题,仅当某些简单问题涉及本地输入/输出表示和非重复输入模式时,幼稚的方法才能很好地起作用(请参阅Hochreiter 1991和Silva等人1996)。 下一节说明如何正确执行操作。
存储单元和门单元。为了构建一种允许通过特殊的自连接单元实现恒定误差而又没有naive的方法的缺点的体系结构,我们通过引入其他功能,扩展了3.2节中由自连接的线性单元j体现的constant error carrousel CEC。引入了一个乘法输入门单元,以保护存储在j中的存储器内容不受无关输入的干扰。同样,引入了乘法输出门单元,通过存储在j中的当前不相关的存储内容来保护其他单元免受干扰。
由此产生的更复杂的单元称为存储单元(参见图1)。第j个存储单元表示为cj。每个存储单元围绕具有固定自连接(CEC)的中央线性单元构建。除了netcj之外,cj还从乘法单元outj(“输出门”)和另一个乘法单元inj(“输入门”)获得输入。inj在时间t的激活用yinj(t)表示,outj的用youtj(t)表示。我们有
![]()
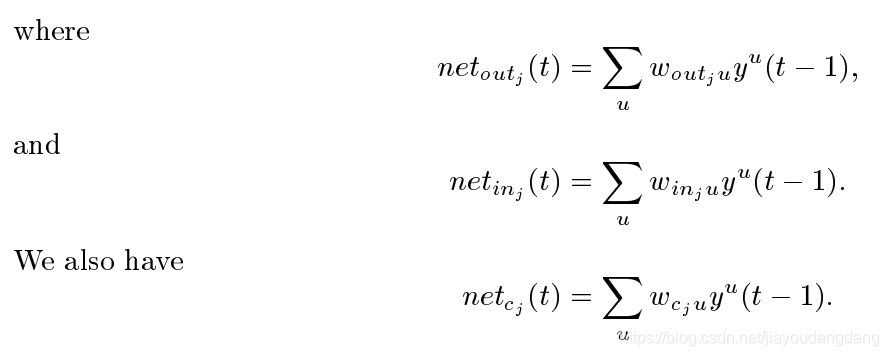
总和u可以代表输入单元,门单元,存储单元,甚至是常规的隐藏单元(如果有的话)(另请参见以下“网络拓扑”段落)。所有这些不同类型的单位都可以传达有关网络当前状态的有用信息。例如,输入门(输出门)可以使用来自其他存储单元的输入来决定是否在其存储单元中存储(访问)某些信息。甚至可能存在像wcjcj这样的循环自连接。由用户决定网络拓扑。有关示例,请参见图2。
在t时刻,cj的输出ycj(t)是: ![]()
其中,内部状态scj(t)是![]()
可微函数g压制netcj;可微函数h缩放从内部状态scj计算的存储单元输出。
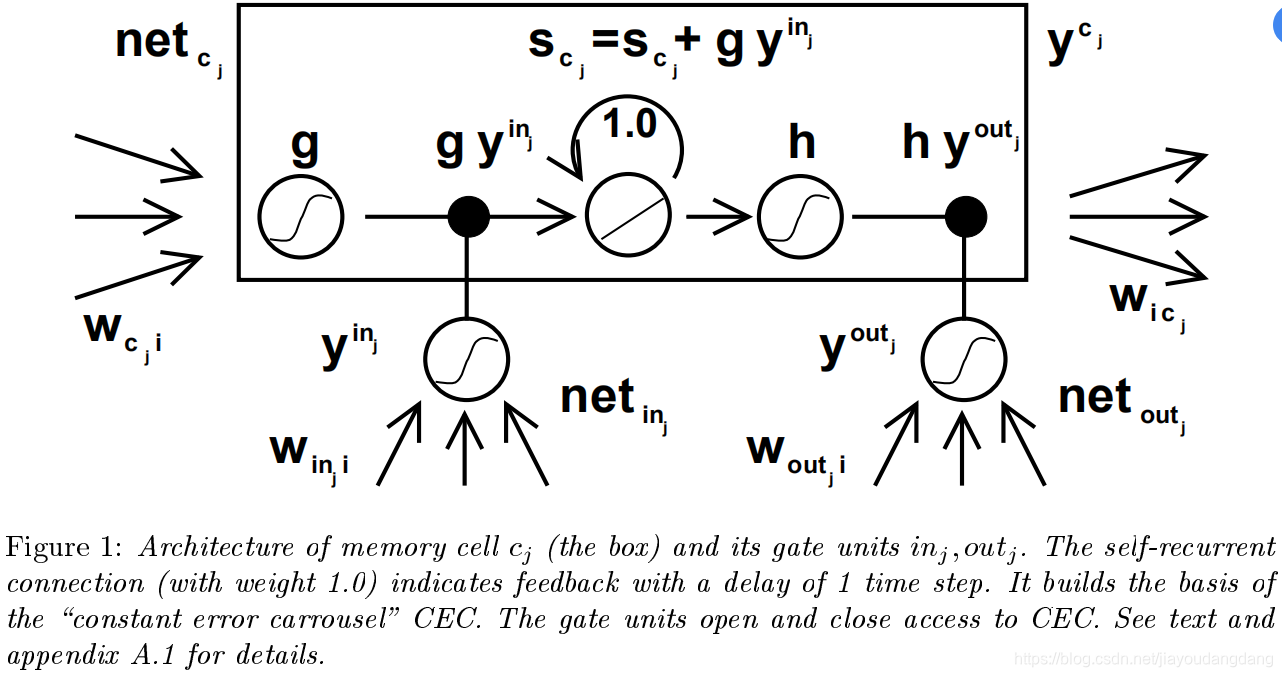
图1:存储单元cj(盒)及其门单元inj,outj的体系结构。自循环连接(权重为1.0)以1个时间步长的延迟指示反馈。它构建了“恒定误差轮播” CEC的基础。门单元打开和关闭对CEC的访问。有关详细信息,请参见文本和附录A.1。
为什么门单位?为了避免输入权值冲突,inj控制了内存单元cj的输入连接的误差。为了绕过cj的输出权值,outj控制来自单位j的输出连接的错误。换句话说,网络可以使用inj来决定何时在内存单元cj中保留或覆盖信息,而使用outj来决定何时访问内存单元cj以及何时防止其他单元受到cj的干扰(参见图1)。
存储单元的CEC中的错误信号不能改变{但是通过输出门进入单元的不同错误信号(在不同的时间)可以被叠加。通过适当地扩展,输出门必须了解在其CEC中应该捕获哪些错误。输入门必须学会何时释放错误,再次通过适当地扩展它们。从本质上说,乘性门单元通过CEC打开和关闭对恒定误差的访问。
分布式输出表示通常需要输出门。虽然—一个可能是必需的,但两个门不一定都是必需的。例如,在第5节的2a和2b实验中,将可能只使用输入门。实际上,在本地输出编码的情况下不需要输出门-通过简单地将相应的权重设置为零,就可以防止存储单元干扰已经学习的输出。然而,即使在这种情况下,输出门也可能是有益的:它们阻止了网络存储长时间滞后记忆(通常很难学习)的尝试,从而干扰了代表容易学习的短时间滞后记忆的激活。(例如,这在实验1中将被证明非常有用。)
网络拓扑结构Network topology。我们使用一个输入层、一个隐含层和一个输出层的网络。(完全)自连接的隐层包含内存单元和相应的栅极单元(为了方便起见,我们将位于隐层中的内存单元和栅极单元都称为隐层)。所述隐层还可以包含提供栅极单元和存储器单元输入的常规“隐单元”。所有层中的所有单元(门单元除外)都有指向连接(作为输入)到上面层中的所有单元(或所有更高的层实验2a和2b)。
存储单元块Memory cell blocks。共享相同的输入门和输出门的内存单元形成一个称为大小为S的内存单元块的结构。记忆单元块促进信息存储—与传统的神经网络一样,在单个单元内编码分布式输入并不容易。由于每个内存单元块与单个内存单元(即两个)具有同样多的门单元,因此块架构甚至可以更特殊一些(请参阅段落“计算复杂性”)。大小为1的内存单元块只是一个简单的内存单元。在实验(第5部分)中,我们将使用不同大小的存储单元块。
学习learning。我们使用RTRL的一个变体(例如,Robinson和Fallside 1987),它适当地考虑了输入和输出门所引起的变化的乘法动力学。然而,以确保non-decaying错误backprop通过内部状态的记忆细胞,与截断BPTT(例如,威廉姆斯和彭1990),错误到达"存储单元网络输入”(细胞cj,这包括netcj、netinj netoutj)得不到传播更久远的时代(尽管他们服务变化的权重)。只有在2个内存单元中,错误才会通过之前的内部状态scj传播回来。为了可视化这一点:一旦一个错误信号到达一个内存单元输出,它将被输出门激活和h’缩放。然后它在记忆细胞的CEC中,在那里它可以无限地慢下来而不需要被缩放。只有当它通过输入门和g离开存储单元时,它才通过输入门激活和g’再次被缩放。然后,它用于在截断之前更改传入的权重(有关显式公式,请参阅附录)。
计算的复杂性。与Mozer的重点循环支持算法(Mozer 1989)一样,只需要存储和更新导数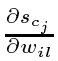 。因此LSTM算法非常特殊,更新复杂度为O(W),其中W表示权值的数量(详见附录A.1)。因此,对于完全经常网,LSTM和BPTT的每一步更新复杂度是相同的(而RTRL要差得多)。但是,与完整的BPTT不同的是,LSTM在空间和时间上是局部的:不需要将序列处理期间观察到的激活值存储在具有无限大小的堆栈中。
。因此LSTM算法非常特殊,更新复杂度为O(W),其中W表示权值的数量(详见附录A.1)。因此,对于完全经常网,LSTM和BPTT的每一步更新复杂度是相同的(而RTRL要差得多)。但是,与完整的BPTT不同的是,LSTM在空间和时间上是局部的:不需要将序列处理期间观察到的激活值存储在具有无限大小的堆栈中。
滥用问题及解决方法Abuse problem and solutions。在学习阶段的开始,可以在不存储信息的情况下减少错误。因此,该网络将倾向于滥用记忆细胞,例如,作为偏见细胞。,它可能使它们的激活保持不变,并使用传出连接作为其他单元的自适应阈值)。潜在的问题是:释放被滥用的记忆细胞并使其用于进一步的学习可能需要很长时间。如果两个记忆单元存储相同的(冗余的)信息,就会出现类似的“滥用”问题。至少有两个解决滥用问题:(1)顺序网络建设(例如,Fahlman 1991):一个存储单元和相应的单元门时被添加到网络错误停止减少(见实验2节5)。(2)输出门偏见:每个输出门负初始偏差,将最初的记忆细胞激活为零。带有更多负偏差的记忆细胞将被自动分配”稍后(参见第5节中的实验1、3、4、5、6)。
内部状态漂移和补救措施。如果记忆细胞cj的输入大部分是正的或大部分是负的,那么它的内部状态sj会随着时间的推移而漂移。这是潜在的危险,因为h’ (sj)将采用非常小的值,而梯度将消失。解决这个问题的一种方法是选择一个合适的函数h,但是h(x) = x的缺点是不限制内存单元的输出范围。我们在学习之初解决漂移问题的简单而有效的方法是使输入门inj最初偏向于零。虽然在h’ (sj)与yinj和f’ inj的量级之间存在贸易,但与漂移效应相比,输入门偏差的潜在负效应可以忽略不计。对于logistic sigmoid激活函数,似乎不需要对初始偏差进行ne-tuning,正如5.4节中的实验4和实验5所证实的那样。

5 实验
略
6 讨论
LSTM的限制
LSTM算法特别有效的截断后向版本不会轻易解决类似于“强烈延迟的XOR问题”的问题,后者的目标是计算先前在嘈杂序列中某处发生的两个广泛分离的输入的XOR。 这是因为仅存储输入中的一个将无助于减少预期的错误-从无法通过首先解决更简单的子目标来逐步减少错误的意义上说,这项任务是不可分解的。
在理论上,这种限制可以通过使用全梯度(也许有额外的传统隐藏单元接收来自存储单元的输入)来避免)。但由于以下原因,我们不建议计算全梯度:(1)它增加了计算复杂度。(2)只有对于截断的LSTM,才能显示通过CECs的恒定误差。(3)我们确实用非截断LSTM进行了一些实验。对于截断的LSTM,没有任何意义,这正是因为在CECs错误之外,现在往往会迅速消失。出于同样的原因,完整的BPTT不优于截断的BPTT。
每个存储单元块需要两个附加单元(输入和输出门)。 但是,与标准递归网络相比,权重的数量增加不超过9倍:在LSTM体系结构中,每个常规的隐藏单元最多被3个单元代替,权重的数量增加了9倍。在完全连接的情况下为32。但是请注意,我们的实验在LSTM和竞争方法的体系结构中使用了相当可比的权重数。
一般而言,由于存储单元中CEC会产生恒定的误差,因此LSTM会遇到类似于前馈网络的问题,因为前馈网络会立即看到整个输入字符串。 例如,有些任务可以通过随机权重猜测快速解决,但不能通过具有较小权重初始化的截断LSTM算法快速解决,例如500步奇偶校验问题(请参阅第5节介绍)。在这里,LSTM的问题类似于具有500个输入的前馈网络的问题,试图解决500位奇偶校验。实际上,LSTM通常表现得很像前向网络,该前向网络由反向传播技术训练,可以看到整个输入。但这也正是为什么它在具有重要搜索空间的许多非平凡任务上明显优于以前的方法的原因。
LSTM的“ recency”概念没有任何其他方法所能解决的问题。但是,所有基于梯度的方法都因实际无法精确计算离散时间步长而产生差异。 在99步或100步之前,似乎需要一种附加的计数机制,然而,更简单的任务(例如只需要在3步和11步之间进行区别)不会对LSTM造成任何问题。 LSTM可以在存储单元的输出和输入之间建立适当的负连接,因此可以为最新的输入赋予更多权重,并在必要时学习衰减。















 2468
2468











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











