






降维
动机1:数据压缩
将数据从二维降为一维:
对于某些高维数据,有可能它实际上只是较低维的。比如两个feature的数据,看起来是分布在二维空间中,但经过观察发现它们集中于一条直线附近,那么可以近似或者简化为一个feature,一维数据。
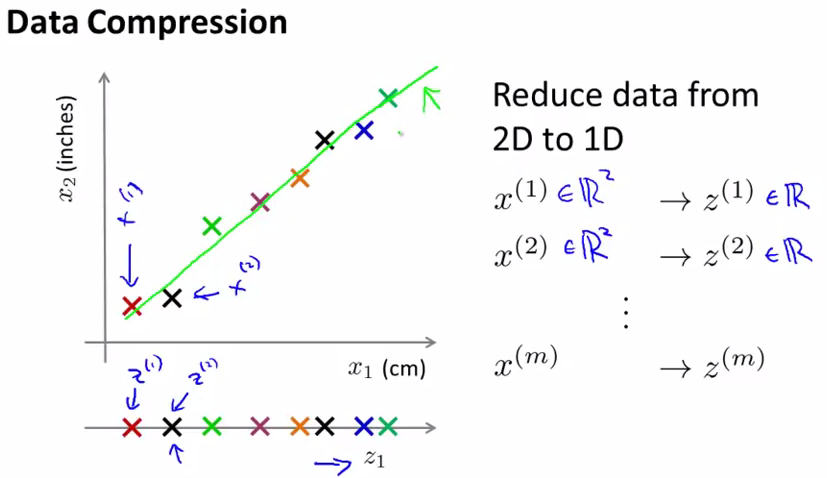
具体做法是:找出一条合适的直线,如上图中的绿色直线,然后将所有数据点投影在该直线上,然后用 z(i) 标识,这样就完成了二位数据像一维数据的映射。
这跟线性代数或者线性几何的坐标变换,或者矩阵正交基变换有直接关系,这方面数学知识学到了实际上这个内容就不用多讲了。另一个视角是统计上的视角,也就是feature之间不是相互独立的,而是相关联的,比如上面的例子中两个feature是线性相关的,那么就等于纳入了多余的feature,可以拿掉多余的feature,做模型简化。
这样做可以将内存占用量减半,使算法运行的更快。
将数据从三维降为二维:
过程和上面类似,将三维向量投射到一个二维的平面上,迫使所有数据都在同一个平面上。
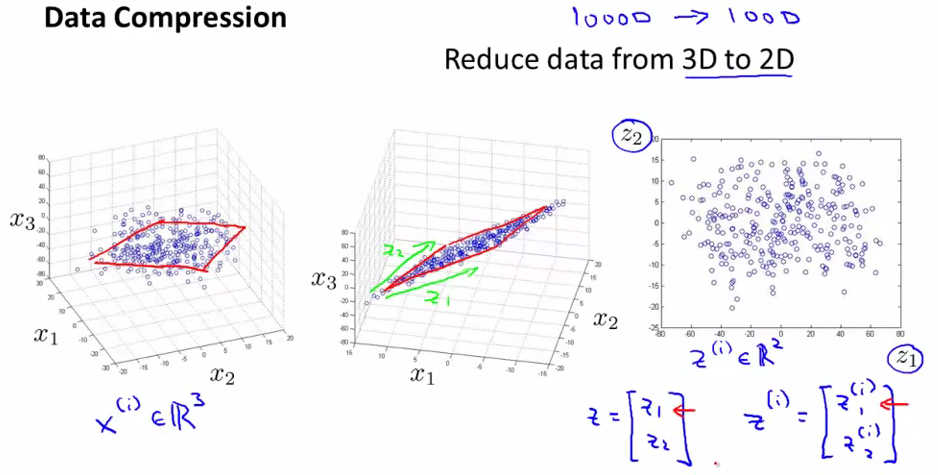
我们可以将这样的处理过程用于任何的维度降维,例如1000维降为100维
动机2:数据可视化
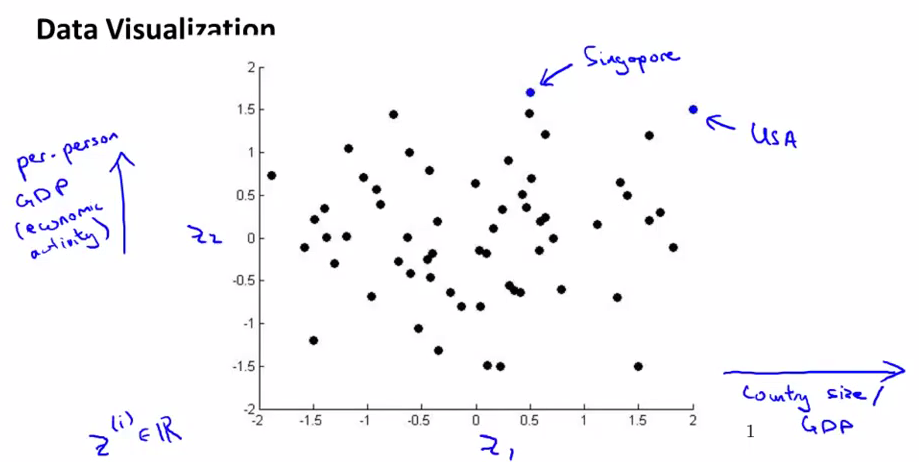
假如我们有很多国家的信息,每个国家都有15个维度的信息。如果能把这些信息plot出来的话,我们可以有更好的直观理解。
但是这么多的feature,我们很难把它们画出来,但是如果把这些信息转化成2D或者3D的信息的话,就可以画出来了。
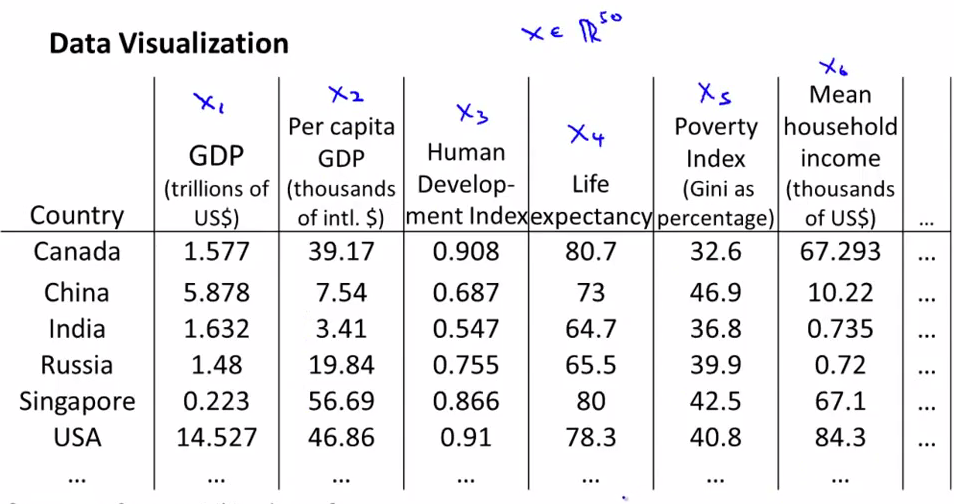
下面我们把这些信息转化成了2D的数据,但是我们难以只管了解到2个维度分别代表什么
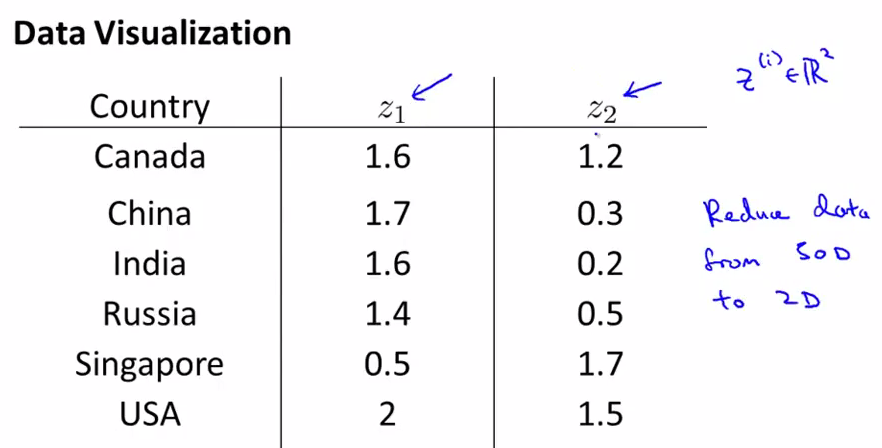
把数据plot出来,然后我们会发现横坐标和国家的整体GDP或者整体size对应,纵轴和人均GDP对应
主要成分分析(principal component analysis)
举个两维的例子(高维的例子相应要把直线调整为超平面)既然我们想找到两个feature实际处于的那一条直线,我们就针对直线做优化,计算数据点投影到直线上的距离,找到让这些投影距离尽量小的直线,这就是我们要找的结果。沿着这条直线的方向向量大小(记为u)就是一个主成份。
下面给出PCA问题的描述:
- 问题是要将n维数据降至k维
- 目标是找到向量u1,u,u3……uk使得总投射误差最小
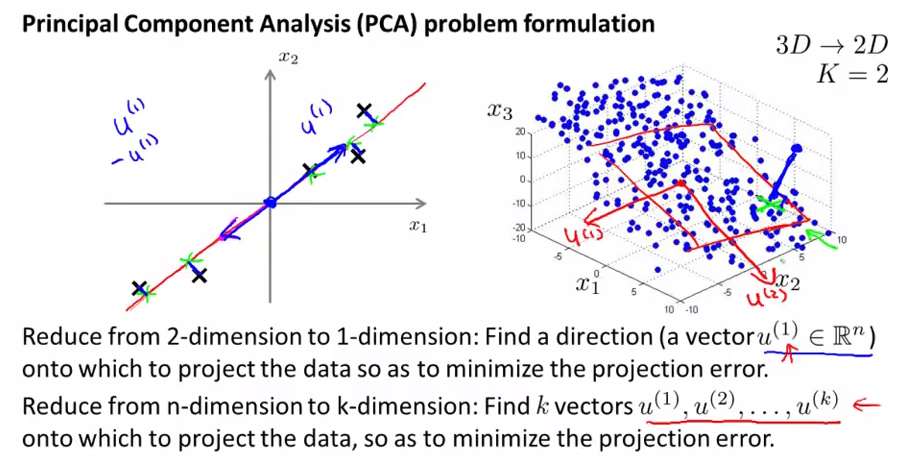
注意:PCA与线性回归是两种不同的算法,PCA最小化的是投射误差,线性回归最小化预测误差
PCA算法
第一步:均值归一化

第二步:计算协方差矩阵
∑
:
∑=1m∑ni=1(x(i))(x(i))T
第三步:计算协方差矩阵的特征向量(eigenvectors)

下一步就是如何得到k维空间表示的每个点了。公式如下,最终得到的z就是x的k维表示
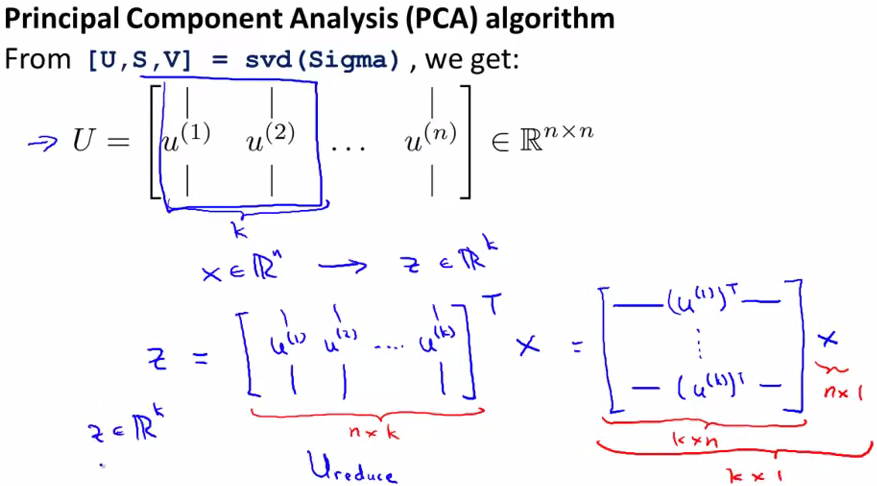
下面是梳理之后的PCA过程

其中,x是n*1维,z是k*1维
选择主要成分的数量
主要成分分析是减少投射的平均均方误差:
1m∑mi=1||x(i)−x(i)approve||2
训练集的方差为:
1m∑mi=1||x(i)||2
我们希望在平均均方误差占训练集方差的比例尽可能小的情况下选择尽可能小的K值

以variance retained数值作为评估PCA的一个指标,一般来说95%-99%是比较常用的取值范围。即使取99%,也经常会取得很好的降维效果,因为很多的feature都有着很强的相关性。
如果我们希望这个比例小于1%,就意味着原有数据的偏差有99%都被保留下来了。
关于如何取得k的值,下图左边是一个直观的逻辑,但是这样的计算量很大,索性svd有一个很好的特性,它的返回结果s可以用来计算variance retained数值

下面是总结之后的计算过程

注意:在压缩数据之后,我们可以这样球的·原有的特征:
x(i)approve=Ureducez(i)














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









