







转自:http://blog.csdn.net/mindfloating/article/details/49103611
我们知道 HDFS 最早是根据 GFS(Google File System)的论文概念模型来设计实现的。
然后呢,我就去把 GFS 的原始论文找出来仔细看了遍,GFS 的整体架构图如下:
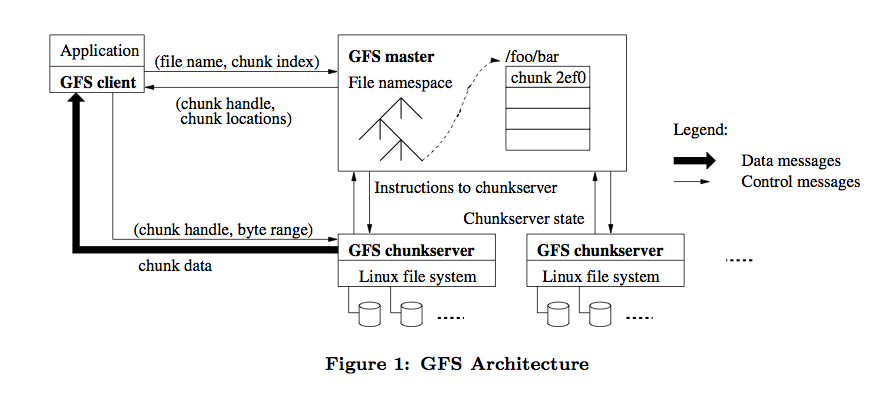
HDFS 参照了它所以大部分架构设计概念是类似的,比如 HDFS NameNode 相当于 GFS Master,HDFS DataNode 相当于 GFS chunkserver。
但还有些细节不同的地方,所以本文主要分析下不同的地方。
写入模型
HDFS 在考虑写入模型时做了一个简化,就是同一时刻只允许一个写入者或追加者。
在这个模型下同一个文件同一个时刻只允许一个客户端写入或追加。
而 GFS 则允许同一时刻多个客户端并发写入或追加同一文件。
允许并发写入带来了更复杂的一致性问题。
多个客户端并发写入时,它们之间的顺序是无法保证的,同一个客户端连续追加成功的多个记录也可能被打断。
这意味着一个客户端在连续写入文件数据时,它的数据最终在文件中的分布可能是不连续的。
所谓一致性就是,对同一个文件,所有的客户端看到的数据是一致的,不管它们是从哪个副本读取的。
如果允许多个客户端同时写一个文件,怎么保证写入数据在多个副本间一致?
我们前面讲 HDFS 时它只允许一个写入者按流水线方式写入多个副本,写入顺序一致,写入完成后数据将保持最终一致。
而对多个客户端而言,就必须让所有同时写入的客户端按同一种流水线方式去写入,才可能保证写入顺序一致。
这个写入流程我们下一节详细分析。
写入流程
GFS 使用租约机制来保障在跨多个副本的数据写入中保持顺序一致性。
GFS Master 将 chunk 租约发放给其中一个副本,这个副本我们就称为主副本,其他副本称为次副本。
由主副本来确定一个针对该 chunk 的写入顺序,次副本则遵守这个顺序,这样就保障了全局顺序一致性。
chunk 租约机制的设计主要是为了减轻 Master 的负担,由主副本所在的 chunkserver 来承担流水线顺序的安排。
如下图,我们详细描述下这个过程。
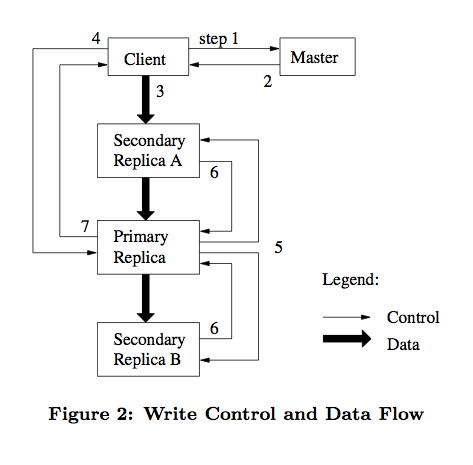
- 客户端请求 Master 询问哪个 chunkserver 持有租约以及其他副本的位置。
如果没有 chunkserver 持有租约,说明该 chunk 最近没有写操作。
Master 则选择将租约授权给其中一台 chunkserver。 - Master 返回客户端主副本和次副本的位置信息。
客户端缓存这些信息以备将来使用。
客户端以后不再需要联系 Master,除非主副本所在 chunkserver 不可用或返回租约过期了。 - 客户端选择最优的网络顺序推送数据,chunkserver 将数据先缓存在内部的 LRU 缓存中。
GFS 中采用数据流和控制流分离的方法,从而能够基于网络拓扑结构更好地调度数据流的传输。 - 一旦所有的副本确认收到了数据,客户端将发送一个写请求控制命令到主副本。
由主副本分配连续的序列号来确定最终的写入顺序。 - 主副本转发写请求到所有次副本,次副本按主副本安排的顺序执行写入操作。
- 次副本写完后向主副本应答确认操作完成。
- 最后主副本应答客户端,若任意副本写入过程中出现错误,将报告给客户端,由客户端发起重试。
GFS 和 HDFS 的写入流程都采用了流水线方式,但 HDFS 没有分离数据流和控制流。
HDFS 的数据流水线写入在网络上的传输顺序与最终写入文件的顺序一致。
而 GFS 数据在网络上的传输顺序与最终写入文件的顺序可能不一致。
GFS 在支持并发写入和优化网络数据传输方面做出了最佳的折衷。
总结
GFS 的论文发表于 2003 年,后来大部分的分布式文件系统设计实现或多或少都参考了 GFS 的设计思路。
而 HDFS 算是开源分布式文件系统中最完整实现了 GFS 论文中的概念模型。
但 HDFS 依然简化了 GFS 中关于并发写的思路,本文就两者的写入模型和过程做了一些对比说明,并希望引发一些思考。
参考
[1] Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung. The Google File System
[2] Hadoop Documentation. HDFS Architecture.
[3] Robert Chansler, Hairong Kuang, Sanjay Radia, Konstantin Shvachko, and Suresh Srinivas. The Hadoop Distributed File System
[4] Tom White. Hadoop: The Definitive Guide. O’Reilly Media(2012-05), pp 94-96
[5] Yongjun Zhang. Understanding HDFS Recovery Processes
[6] Hairong
Kuang,
Konstantin
Shvachko,
Nicholas
Sze,
Sanjay
Radia,
Robert
Chansler
, Yahoo!
HDFS
team
Design Specification: Append/Hflush/Read
Design
[7] HDFSteam. Design Specification: HDFS Append and Truncates















 3053
3053

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









