







1. 为什么有编码?
计算机智能处理“数字”,但人类大多数时候处理的是“文本”。编码可以理解为编码表,是连接计算机处理的“数字”和人类处理的“文本”之间的桥梁。在编码表中,每个字母或汉字(日本字,希腊字,blabla字)对应一个二进制或十进制的编号。在将“文本”转为“数字”的时候,去编码表里找对应的“数字”,就能方便计算机的理解。比如:
字母A对应的ASCII编码:65(十进制)or 01000001(二进制)
2. 几种常见的编码
2.1 ASCII编码
美国人最早发明计算机,他们设计了ASCII编码表,只包含127个大小写字母、数字和一些符号(总计256个)。该编码的局限在于:它只解决了将英文转化为计算机能理解的语言的问题,对于中文、韩文、日文等其他语言的转换,会出现乱码(因为找不到或者找错了编码)。
后来计算机普及了,中国人想让计算机处理中文,日本人想让计算机处理日文,…,于是就有了各种编码格式,如gbk2312(一个字符占2字节),gbk(一个字符占2字节)等。
2.2 Unicode编码
由于出现了太多的编码格式,于是大牛们同意规范,进而出现了Unicode编码,它(被称为“万国码”)把所有的语言统一到一套编码里面,这样就不会出现乱码问题了。python3内部使用的就是Unicode编码。
最初的Unicode编码是固定长度的,16位,也就是2两个字节代表一个字符,这样一共可以表示65536个字符。显然,这样要表示各种语言中所有的字符是远远不够的。Unicode4.0规范考虑到了这种情况,定义了一组附加字符编码,附加字符编码采用2个16位来表示,这样最多可以定义1048576个附加字符,目前Unicode4.0只定义了45960个附加字符。因此,目前在Unicode编码格式中,一个字符(不管哪个国家的),至少以2个字节表示。其中,英文字母用2个字节,汉字用3个字节。这个编码虽然满足了所有人的需求,但是他不兼容ASCII编码,同时还占较多空间和内存(因为,计算机世界更多的字符是英文字母,明明可以1个字节就能够表示,非要用2个。)。
2.3 UTF-8编码
为了解决上述问题,UTF-8诞生了。它也是一种万国码,兼容ASCII编码,也就是说ASCII中每个字符的编码在UTF-8中是完全一样的,因此可以解码早期的文档。UTF-8的编码长度是可变的,一个字符的长度可能是1个字节,2个字节,3个字节或者4个字节。一般来说,欧洲的字母字符长度为1到2个字节,而亚洲的大部分字符则是3个字节,附加字符为4个字节。
3. 编码工作方式
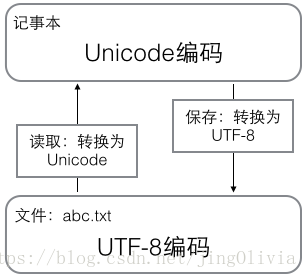
计算机内存中,统一使用Unicode编码,在.py或者.txt文件中键入文字时,计算机内存是以 Unicode 编码的方式对这些文字进行保存的。编辑完成之后,保存的时候,计算机再把 Unicode 编码转化为 UTF-8编码 保存在文件中。
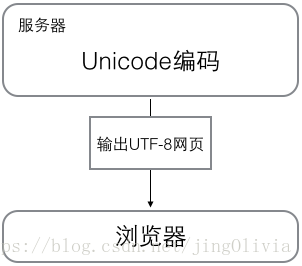
另外浏览网页时,服务器会把动态生成的 Unicode 内容,转化为 UTF-8 编码形式,再传输到浏览器,那么用户就可以看到自己能理解的语言组成的网页,比如中文、日文、韩文等等。很多网页的源代码上会有类似<meta charset='UTF-8' /> 的信息,表示该网页是 UTF-8 编码。
4. python3编码方式
python3最重要的新特性之一是对字符串和字符流的区别:
- 字符串:str类型,用于:程序内部(内存中)
- 字符流:bytes类型,用于:网络传输,保存文件
python3 程序中的字符串默认为 Unicode 编码,也就意味着,python3 字符串支持多语言。虽然 python3 字符串在内存中以 Unicode 表示,但是在网络上传输或者保存到磁盘的时候,需要把字符串(str对象)变为以字节为单位的字节流(bytes对象)。
python3中,文件的open()函数的参数:encoding指定文本的编码方式,mode有多种赋值,其中:
'b': binary mode # 返回bytes对象
't': text mode (default) # 返回str对象
str类和bytes类有着几乎一模一样的方法列表,最大的区别就是encode()和decode()
4.1 encode() 方法
str类的方法,以指定的编码格式编码str对象,返回bytes对象。
默认的编码方式为utf-8
s = '中国'
s_utf8 = s.encode(encoding='utf-8', errors='strict')
# 不改变s的类型,返回一个新的bytes对象
# 效果同 s_utf8 = bytes(s, encoding='utf-8')
print(type(s))
print(type(s_utf8))
# encoding:要使用的编码方式,如Unicode,utf-8等。
# errors:可选参数,默认为strict,表示如果发生错误,则返回一个UnicodeError。
# 输出结果为:
<class 'str'>
<class 'bytes'>
4.2 decode() 方法
bytes类的方法,以指定的编码格式(与编码时(encode())保持一致)解码bytes对象,返回str对象。
print(type(s_utf8.decode(encoding='utf-8', errors='strict')))
# 输出结果为:
<class 'str'>
5. 区分以下编码
5.1 系统默认编码
Windows简体中文,默认编码(cmd,Windows的txt文件)为gbk。
如果将超过gbk范围的utf-8码写入系统的txt文件,会报错;在cmd中的print时也会报错。处理方法:
将utf-8码encode为bytes再写入或print。
5.2 编辑界面编码
编辑界面编码默认为ASCII,即写的程序语句默认是ASCII,但一旦涉及到ASCII不能表示的,就隐形转化为系统默认编码。程序中的字符串默认编码为Unicode,也就是内存中的编码格式。
5.3 运行界面编码
cmd中运行程序,默认显示文本的编码是ASCII,一旦超出范围就隐式转换为系统编码。
pycharm运行界面的默认编码是utf-8。所以有时在pycharm中print没问题的字符串,到cmd中print就会出问题。
5.4 代码文件编码
代码文件(py文件)本身也是文本,它也需要在硬盘或者其他载体上保存,默认编码为系统编码。这样的话,一旦py文件复制到其他系统中,就会出问题(乱码)。
注意:py文件开头声明文件的编码方式:
# -- coding: utf-8--
只是告诉python编译器在读取代码文件时按utf-8方式读取,但这个声明不能将py文件保存为utf-8格式的。
5.5 读入文件编码
当从网络和硬盘读入文件时,实际上读到的是字节流:
- 硬盘读入文件的默认编码方式是系统编码方式,当出现超过
gbk范围的字节出现,会报错。 - 网络读入文件时,因为读入的是字节,不会报错,但一旦
print时就会报错。
所以,如果不能按照读入文本的编码方式转化为Unicode,就会出问题。
处理方式:
因为read()没有编码方式参数,只能读入bytes,然后再解码为Unicode或者其他编码方式。这时需要先判断读入内容的编码方式,用chardet的detect()方法,接收bytes类型的参数,返回一个结果字典,包含编码方式和新都区间。
import chardet
with open(file_path, ''rb) as f:
s = f.read()
print(chardet.detect(s))
# 输出结果为:
{'encoding': 'GB2312', 'confidence': 0.99}
5.6 写出文件编码
如果想将文本直接以Unicode码保存到文件,用encode('unicode-escape')转化为bytes,写入文件。
参考资料
[1]关于Unicode字符集
[2]python3 字符集编码以及python3 乱码问题
[3]一步一步搞定Python3.6编码问题
[4]Python3编码问题(Python2请忽略)














 750
750











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









