







1.Redis策略说明
1.1 Redis持久化策略
1.1.1 redis持久化问题说明
说明:redis的运行环境是内存,读写的速度很快,但是内存的特点断电即删除,所以非常容易造成业务数据的丢失。
问题:如何保证redis数据尽可能不丢?
解决方法:将redis的内存的数据定期保存到磁盘中。
1.1.2 Redis持久化策略说明
redis自身有两种持久化的策略,分别是RDB模式和AOF模式。
redis会定期将内存中的数据持久化到文件中,如果redis服务器宕机了,在重启时会根据文件的持久化文件名称实现数据的读取,从而实现内存数据的恢复。
1.1.3 RDB默认说明
1.1.3.1RDB模式介绍
1)、RDB模式时redis默认的策略 ,默认是开启的。
2)、RDB模式记录的是redis的内存快照,所以执行的效率最高,速度最快。
3)、RDB模式周期性的进行持久化,则可能会导致少量数据丢失。
4)、RDB模式是同步操作,持久化时会造成线程阻塞。
1.1.3.2 RDB模式配置
1)、指定RDB模式的名称

2)、指定持久化文件的位置。(默认条件在当前目录生成)

1.1.3.3 RDB模式持久化命令
命令:save 或 bgsave
save:要求数据立即持久化,这时其他线程会陷入阻塞状态
bgsave:在后台进行持久化操作,但是不知道具体是什么时候完成。当redis不忙时就会持久化。(不会产生阻塞异步操作)
1.1.3.4 RDB模式持久化策略
save 900 1 900秒内如果执行1次更新操作,则持久化一次
save 300 10 300秒内如果执行10次更新操作,则持久化一次
save 60 10000 60秒内如果执行10000次更新操作,则持久化一次
save 1 1 1秒内如果执行一次更新操作,则持久化一次(效率太低)
1.1.4 AOF模式
1.1.4.1 AOF模式说明
1)、AOF模式默认条件下时关闭的,需要手动开启
2)、AOF模式记录的用户的操作过程,将用户的操作命令追加到持久化文件当中。AOF模式的持久化文件较大,恢复内存数据的时间比较久,所以需要定期维护该文件。
3)、AOF模式可以实现数据的实时持久化。
4)、AOF模式由于是异步操作,所以不会陷入阻塞。
1.1.4.2 AOF模式配置
1)、开启AOF模式

2)、持久化文件名称

1.1.4.3 AOF模式内存策略
appendfsync always 用户执行一次更新操作,则持久化一次
appendfsync everysec 每秒持久化一次。(效率高,但是比RDB模式低)
appendfsync no 持久化的时间由操作系统决定(一般不用)
以上的操作是异步操作,所以不会陷入阻塞。
1.1.5 关于持久化方式的选择
原则:如果允许少量数据丢失,则首选RDB模式(快),如果内存数据不允许丢失,则选AOF模式。
实际使用: 1.redis当作缓存使用 RDB模式
2.redis当作数据库/消息中间件 AOF模式
1.2 Redis内存策略
1.2.1 关于Redis内存策略说明
redis使用内存保存用户数据,但是如果用户的数据一直存储,不删除.则必然导致内存溢出。
问题:如何实现内存数据的维护?
1.2.2 redis内存配置
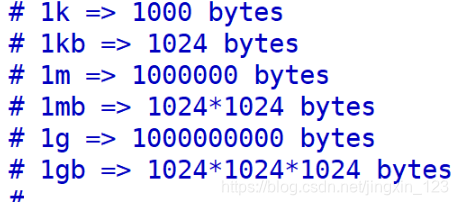
- 内存大小配置

- 修改内存策略

1.2.3 LRU算法
LRU是Least Recently Used的缩写,即最近最少使用,是一种常用的页面置换算法,选择最近最久未使用的页面予以淘汰。该算法赋予每个页面一个访问字段,用来记录一个页面自上次被访问以来所经历的时间 t,当须淘汰一个页面时,选择现有页面中其 t 值最大的,即最近最少使用的页面予以淘汰。
维度: 时间T
1.2.4 LFU算法
LFU(least frequently used (LFU) page-replacement algorithm)。即最不经常使用页置换算法,要求在页置换时置换引用计数最小的页,因为经常使用的页应该有一个较大的引用次数。但是有些页在开始时使用次数很多,但以后就不再使用,这类页将会长时间留在内存中,因此可以将引用计数寄存器定时右移一位,形成指数衰减的平均使用次数。
维度: 引用次数
1.2.5 Redis内存策略
1.volatile-lru 在设定了超时时间的数据中,采用LRU算法进行数据删除
2.allkeys-lru 所有数据都采用LRU算法进行数据删除
3.volatile-lfu 在设定了超时时间的数据中,采用LFU算法进行数据删除
4.allkeys-lfu 所有数据都采用LFU算法进行数据删除
5.volatile-random 设定了超时时间的数据随机删除
6.allkeys-random 所有的数据随机删除
7.volatile-ttl 将马上要超时的数据提前删除
8.noeviction 默认的策略。如果内存数据满了,但是不删除数据,直接报错返回
2. Redis分片策略
2.1 Redis分片说明
2.1.1 问题描述
一般公司业务比较复杂时,需要将海量的数据实现缓存的处理。这时如果只有一台redis能否实现该功能。
思路: 能否准备多台redis服务器 共同使用内存空间,从而实现用户业务处理。
2.1.2 Redis分片机制说明
说明:由多台redis公共处理用户的业务数据。实现了redis内存数据的动态扩。称之为分片机制。
特点:多台redis当作1台使用
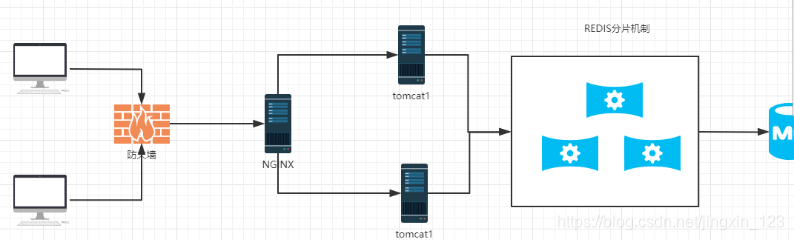
2.2Redis分片搭建
2.2.1搭建步骤
1).关闭原有的redis服务器.

2).创建分片目录
[root@localhost redis]# mkdir shards
3).复制redis配置文件到指定的目录下
image-20200421114159560
4).修改redis的端口号

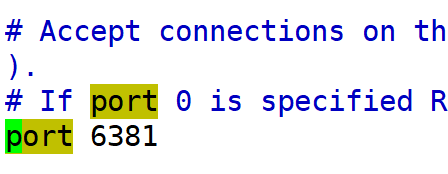
5).启动redis服务器
命令:
redis-server 6379.conf & redis-server 6380.conf & redis-server 6381.conf &
启动检查:

2.2.2redis分片测试
public class TestShardsRedis {
/**
* 通过1个API操作后台3台redis.
* 问题:redis分片中的数据是如何存取???
*/
@Test
public void testShards() {
List<JedisShardInfo> shards = new ArrayList<JedisShardInfo>();
shards.add(new JedisShardInfo("192.168.126.129",6379));
shards.add(new JedisShardInfo("192.168.126.129",6380));
shards.add(new JedisShardInfo("192.168.126.129",6381));
ShardedJedis shardedJedis = new ShardedJedis(shards);
shardedJedis.set("redis", "测试redis分片是否可用");
System.out.println(shardedJedis.get("redis"));
}
}
2.3一致性hash
一致性哈希算法在1997年由麻省理工学院提出,是一种特殊的哈希算法,目的是解决分布式缓存的问题。 [1] 在移除或者添加一个服务器时,能够尽可能小地改变已存在的服务请求与处理请求服务器之间的映射关系。一致性哈希解决了简单哈希算法在分布式哈希表( Distributed Hash Table,DHT) 中存在的动态伸缩等问题 [2] 。
总结:一致性hash主要解决分布式环境下缓存存储性问题.要求尽可能小的改变已存储的数据. 主要可以实现动态的伸缩.
2.3.1一致性hash原理
常识:
1).hash一般取值区间范围 0-2^32
2).如果对相同的数据进行hash 则hash的结果相同.
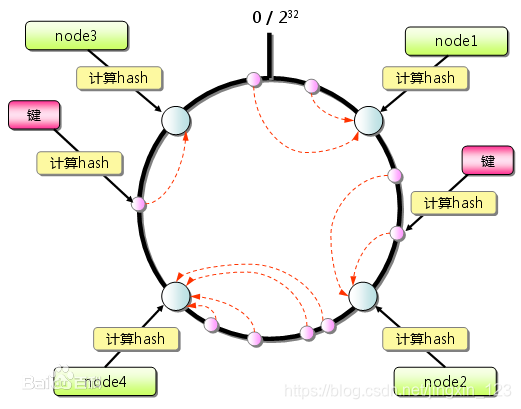
按照顺时针的方向进行数据的存储.
2.3.2均衡性
问题说明:如果节点是根据hash计算之后获取的数据.则可能出现如下的现象
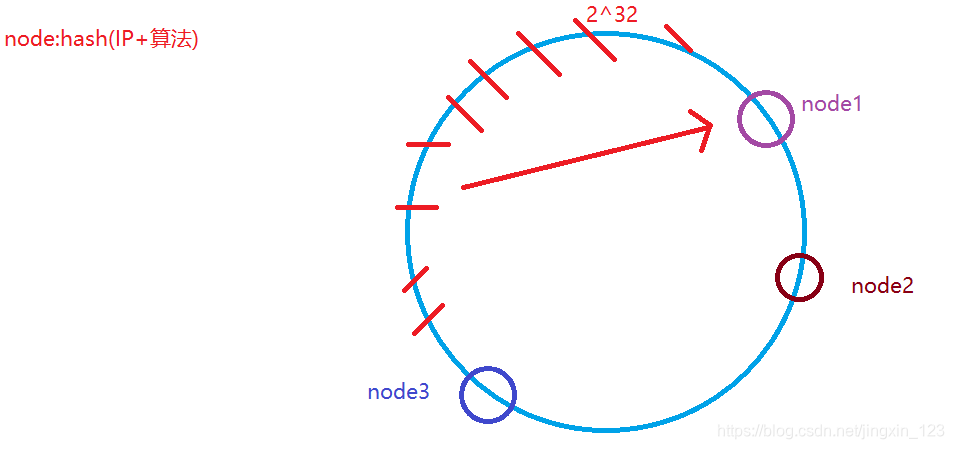
1.节点会出现严重的负载不均的现象. 有的多/有的少
2.如果redis采用这样的方式进行数据的存储.则势必造成数据的提前删除(丢失).
均衡性说明:
由于节点计算可能会出现负载不均的现象.则可以引入虚拟节点实现数据的动态的平衡. 相对的平均.
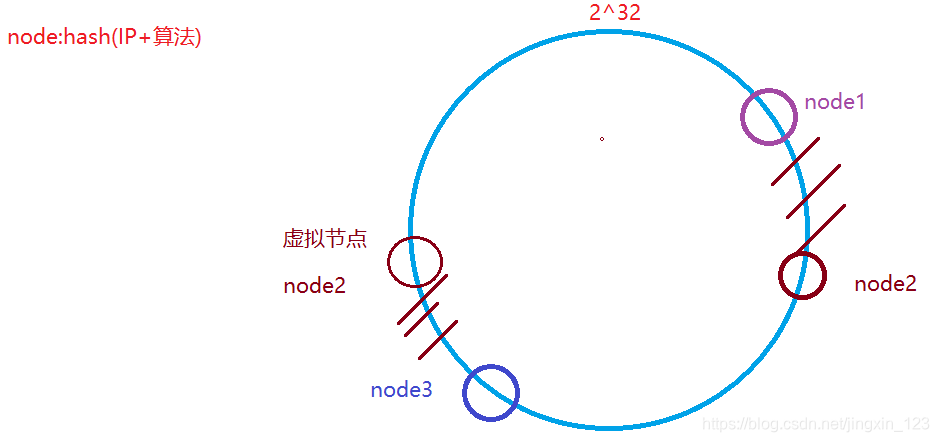
2.3.3单调性
单调性是指在新增或者删减节点时,可以实现数据的动态的迁移,不影响用户的使用.
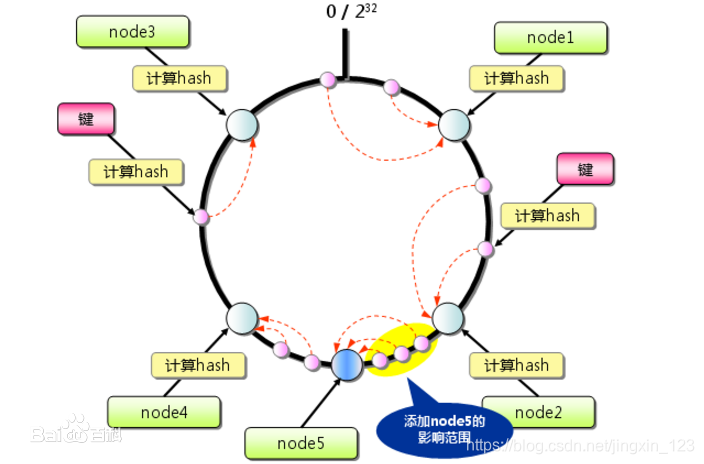
2.3.4分散性
分散性是指数据应该分散地存放在分布式集群中的各个节点(节点自己可以有备份),不必每个节点都存储所有的数据 鸡蛋不要放到一个篮子里
2.4SpringBoot整合Redis分片
2.4.1编辑properties文件
将redis节点数据写入配置文件中.
#配置redis分片机制
redis.nodes=192.168.126.129:6379,192.168.126.129:6380,192.168.126.129:6381
2.4.2编辑redis配置类
@Configuration //标识配置类
@PropertySource("classpath:/properties/redis.properties") //spring容器去加载配置文件
public class RedisConfig {
@Value("${redis.nodes}")
private String nodes; //注入redis的节点信息. node,node,node
//配置redis的分片机制
@Bean
public ShardedJedis shardedJedis() {
List<JedisShardInfo> info = new ArrayList<JedisShardInfo>();
String[] arrayNode = nodes.split(","); //node=host:port
for (String node : arrayNode) {
String host = node.split(":")[0];
int port = Integer.parseInt(node.split(":")[1]);
info.add(new JedisShardInfo(host, port));
}
return new ShardedJedis(info);
}
}
3.Redis哨兵机制
3.1Redis分片缺点
3.1.1分片缺点说明
说明:redis分片虽然可以实现内存的扩容,但是没有实现redis高可用.如果后期redis服务器一旦宕机.则可能会影响整个redis分片的运行.
缺点:没有高可用!!!
3.2Redis主从
3.2.2Redis高可用的设计
准备3台redis 1台当作主机 2台当作从机
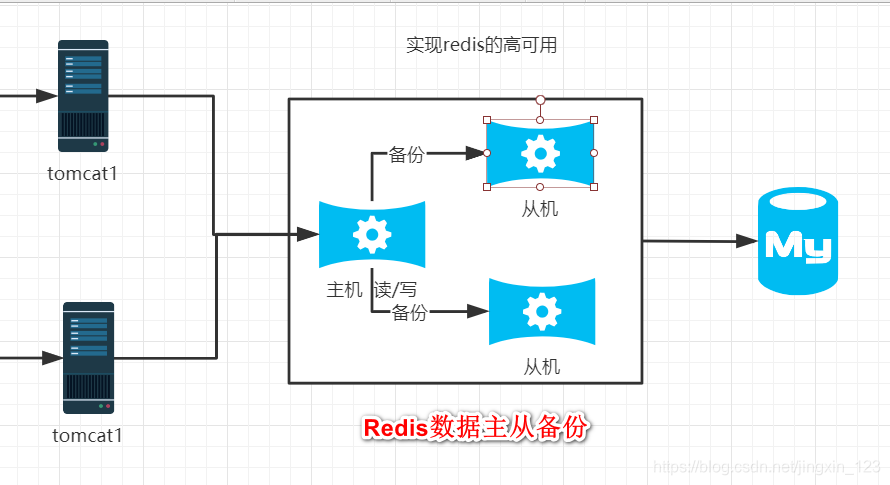
3.2.3 Redis主从搭建
1).复制文件目录
将原有shards文件目录复制为sentinel.
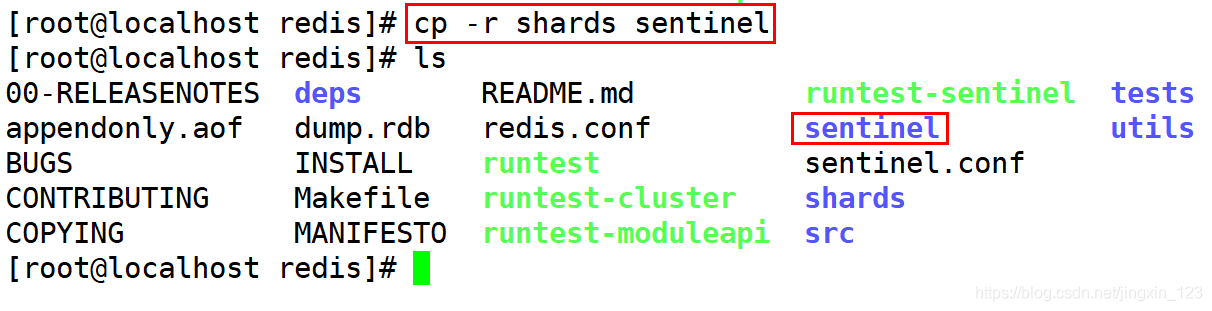
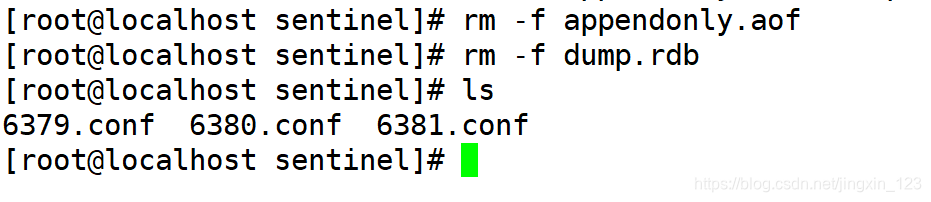
2).删除多余的持久化文件
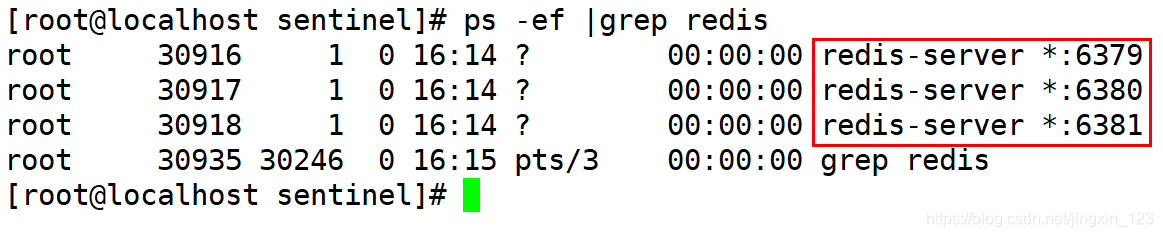
3).启动3台redis服务器
redis-server 6379.conf & redis-server 6380.conf & redis-server 6381.conf &
4).主从搭建命令
1)要求:在redis客户端中执行. 6379主机 6380/6381从机
salveof 主机IP地址 端口号
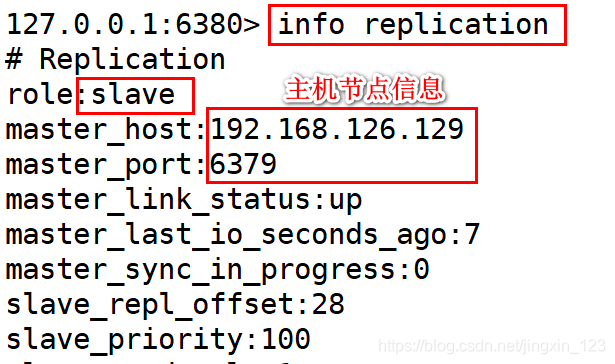
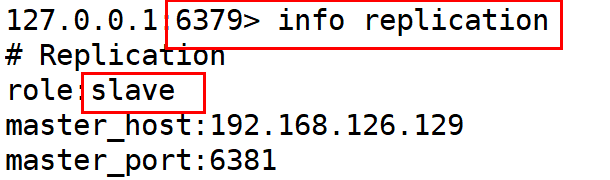
2).检查redis节点状态信息.命令如下:
info replication
3).实现主从挂载: 要求在从节点中挂载主机.
127.0.0.1:6380> SLAVEOF 192.168.126.129 6379
127.0.0.1:6381> SLAVEOF 192.168.126.129 6379
3.2.4主从测试
1).检查主机的状态信息
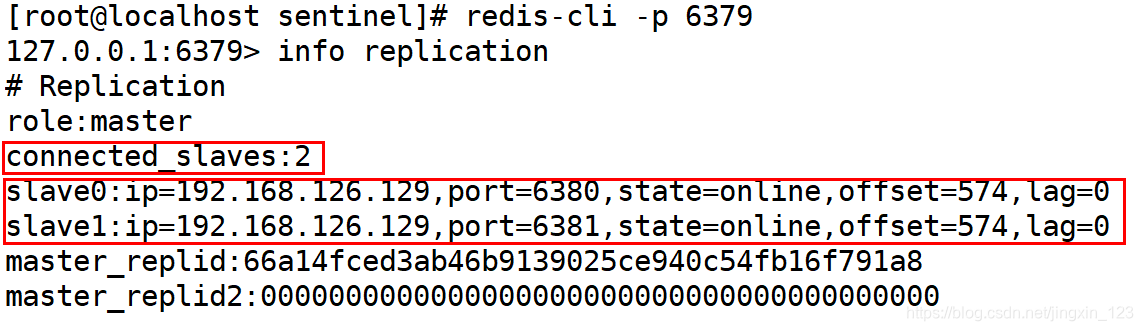
2).主从测试 操作主机检查从机数据是否能够实现同步.

3.3Redis哨兵实现
3.3.1哨兵实现原理
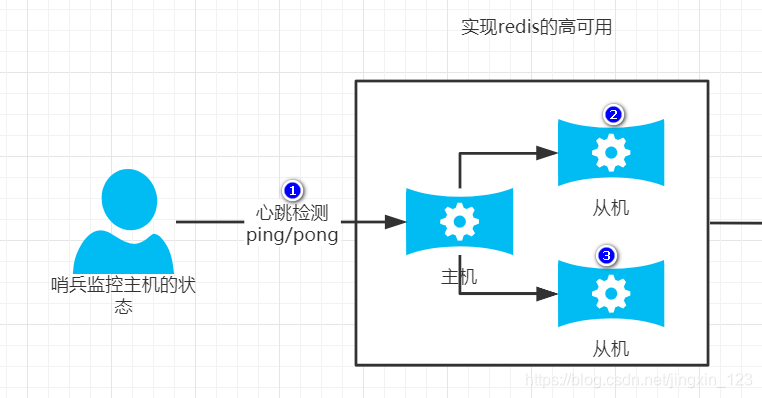
1.哨兵服务启动时,首先会监控主节点,并且获取主节点的状态信息.(主从的关系)
2.当哨兵连续3次ping主节点,如果都没有得到响应则断定主节点宕机.开始进行选举机制.根据自己内部的规则挑选其中一台从机当作新的主机.
3.如果有新的主机当选,则剩余的节点都要充当新主机的从.
3.3.2哨兵配置
1).复制配置文件到sentinel目录中
cp sentinel.conf sentinel/
2).关闭保护模式

3).开启后台启动

4).编辑哨兵监控配置
要求: 必须实现主从配置 image-20200421172035454

5).修改哨兵推选时间
改为10秒

6).修改哨兵选举的超时时间

3.3.3哨兵启动测试
哨兵主要功能: 实现redis节点高可用. 主机宕机之后,可以自动的实现选举,选举新的主机.
哨兵命令:
redis-sentinel sentinel.conf

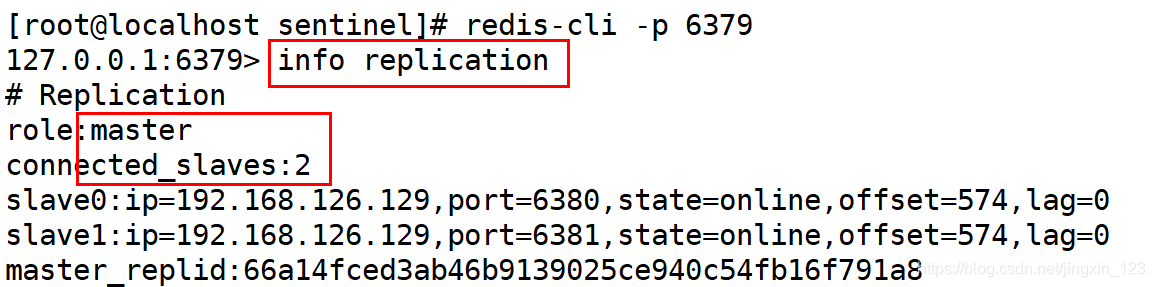
高可用测试说明:
1.检查主机的状态,之后将redis主节点宕机.
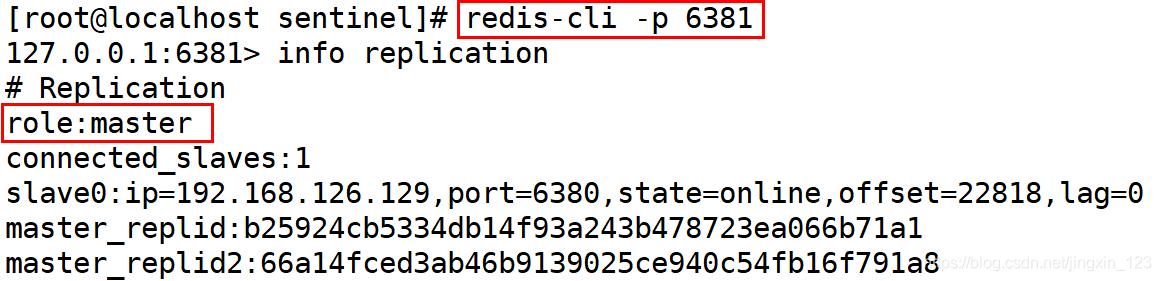
2.10秒之后,检查redis从节点,检查是否实现高可用.
3.重启redis主机,检查主机是否成为新主机的从.
3.3.4redis哨兵测试
原理说明:
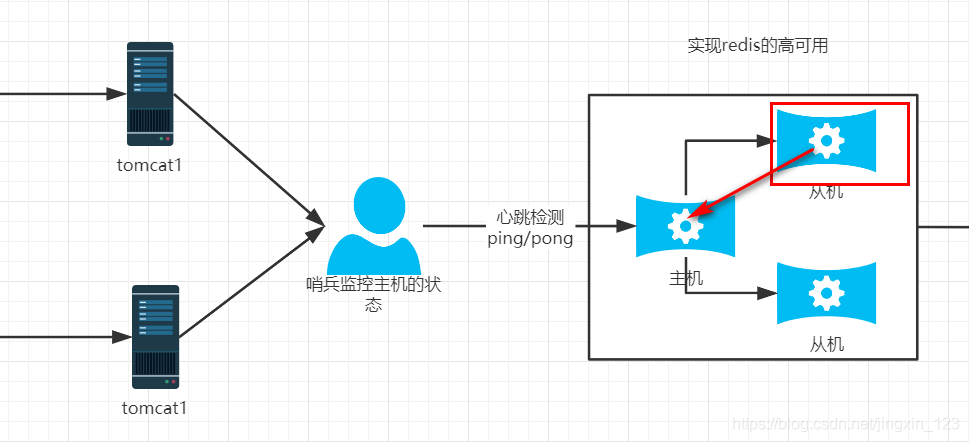
用户通过哨兵操作主机,用户无需了解当前的redis谁是主机.对于用户而言不关心.用户只需要知道操作可以正常执行即可.
public class TestSentinel {
/**
* 测试哨兵是否可用
* masterName: 查找当前主机的变量名称
* sentinels: Set集合信息 存储哨兵的节点信息
*/
@Test
public void test01() {
Set<String> sentinels = new HashSet<>();
sentinels.add("192.168.126.129:26379");
JedisSentinelPool sentinelPool =
new JedisSentinelPool("mymaster", sentinels);
//利用池动态获取jedis对象
Jedis jedis = sentinelPool.getResource();
jedis.set("redis", "redis哨兵机制!!!!!!");
System.out.println(jedis.get("redis"));
}
}
注意事项:
1.哨兵机制能否当作分片使用? 不可以
原因:分片实现了内存扩容,每个节点都可以set数据.
哨兵机制实现了高可用.只有主节点才能set数据
测试原则: 测试分片启动分片的服务 测试哨兵 启动哨兵所有服务() READONLY You can’t write against
a read only replica.















 302
302











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









