







转自:http://blog.csdn.net/zhaoxinfan/article/details/9963673
在做新闻推荐系统的时候,首先要做的应该是抓取新闻,从中提取关键字,其次是运用机器学习里面的聚类分类方法根据浏览记录对用户进行分组,在组内进行推荐。在这里我只是简单说下抓取新闻之后如何从中提取出关键字,其他内容就不在这里介绍了。
关于提取关键字的理论基础,强烈推荐大家看这篇文章:TF-IDF与余弦相似性的应用(一):自动提取关键词,作者是大名鼎鼎的阮一峰。了解了提取关键字是怎么一回事后,接下来就是实践的过程了,不用担心,其实别人早就给我们写好了提取关键字的工具,自己只需要调用其接口就行,省时省力,何乐而不为呢?
目前网络上这方面的工具有不少,就使用来看主要有下面两个开源的工具,一个是北理工张华平(晓阳速来拜见导师)老师的NLPIR,专门做分词的,号称全球第一;还有一个是复旦大学fudanNLP。这两个工具各有特点:NLPIR是用C++写的,C++,C#很容易调用,JAVA调用起来还要用JNI,感觉比较麻烦;fudanNLP本身就是java实现的,JAVA调用起来很方便。所以看你的平台,这里我是JAVA,首选fudanNLP,如果非要在JAVA下使用NLPIR,建议参看这篇文章:http://blog.csdn.net/zhyh1986/article/details/9167593,下面就不介绍NLPIR了。
1、下载fudanNLP
地址看这里:https://code.google.com/p/fudannlp/downloads/list
解压后能看见很多文件,不过只需要和下面这几个文件/文件夹打交道:
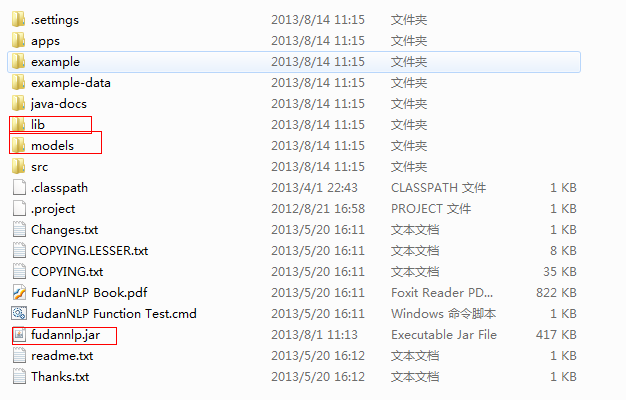
2、添加jar和models
创建一个工程,把lib下所有的jar包和fudannlp.jar包添加到项目中,同时把models文件夹拷贝到项目下:
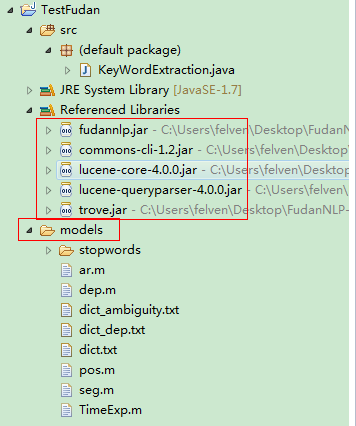
3、写关键字提取函数
添加好之后下面就可以写提取关键字的函数了,如果不知道怎么写可以参看fudanNLP自带的例子:
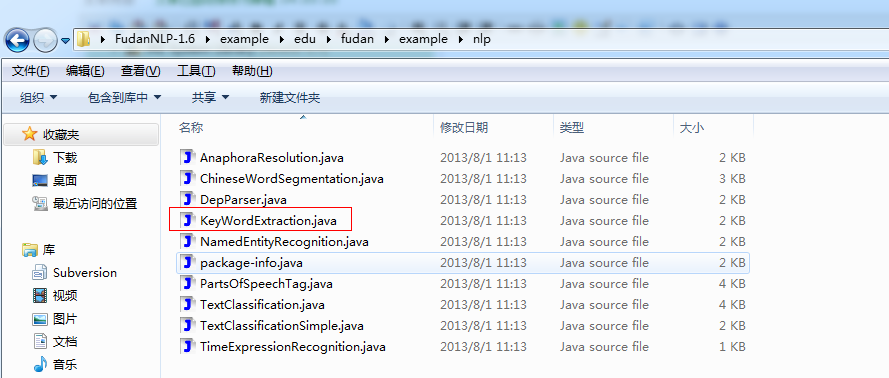
这里我只需要在原有代码的基础上加以修改,注意到提取到的关键字是作为一个Map保存起来的:
Map<String,Integer> ans = key.extract(String str, Integer n);
那我只需要传递str和n,然后读取map中的key值即可得到关键字,全部代码如下:
- import java.util.ArrayList;
- import java.util.Map;
- import org.fnlp.app.keyword.AbstractExtractor;
- import org.fnlp.app.keyword.WordExtract;
- import edu.fudan.nlp.cn.tag.CWSTagger;
- import edu.fudan.nlp.corpus.StopWords;
- public class GetKeywords {
- public ArrayList<String> GetKeyword(String News,int keywordsNumber) throws Exception{
- ArrayList<String> keywords=new ArrayList<String>();
- StopWords sw= new StopWords("models/stopwords");
- CWSTagger seg = new CWSTagger("models/seg.m");
- AbstractExtractor key = new WordExtract(seg,sw);
- //you need to set the keywords number, here you will get 10 keywords
- Map<String,Integer> ans = key.extract(News, keywordsNumber);
- for (Map.Entry<String, Integer> entry : ans.entrySet()) {
- String keymap = entry.getKey().toString();
- String value = entry.getValue().toString();
- keywords.add(keymap);
- System.out.println("key=" + keymap + " value=" + value);
- }
- return keywords;
- }
- }
输出结果是这样:

其实后面那个value值应该是用来标记某个词重要性的,值越大证明越可能是关键词,这里我并不需要用到。
好了,调用别人的工具就是这么简单,当然fudanNLP的功能远不止这些,可以上它的演示网站看看:http://jkx.fudan.edu.cn/nlp/
注:fudanNLP的关键词提取技术并不是用TF-IDF,而是类似于Pagerank的Textrank,具体可以参看这篇论文:
R. Mihalcea and P. Tarau. 2004. TextRank – bringing order into texts
感谢晓阳童鞋更正
最后附上别人写的通过web service调用FudanNLP的代码:
- import java.io.BufferedReader;
- import java.io.IOException;
- import java.io.InputStreamReader;
- import java.net.URL;
- import java.net.URLEncoder;
- /**
- * FudanNLP Web Services使用示例
- * @author 赵嘉亿
- */
- public class Demo {
- static String u = "http://jkx.fudan.edu.cn/fudannlp/";
- public static String nlp(String func, String input) throws IOException {
- // must encode url!! if we write FudannlpResource.seg(String) this way
- input = URLEncoder.encode(input, "utf-8"); //utf-8 重要!
- URL url = new URL( u + func + "/" + input);
- StringBuffer sb = new StringBuffer();
- BufferedReader out = new BufferedReader(new InputStreamReader(url.openStream(), "utf-8")); //utf-8 重要!
- String line;
- while ((line = out.readLine()) != null)
- sb.append(line);
- out.close();
- return sb.toString();
- }
- public static String welcome() throws IOException {
- URL url = new URL(u);
- StringBuffer sb = new StringBuffer();
- BufferedReader out = new BufferedReader(new InputStreamReader(url.openStream(), "utf-8"));
- String line;
- while ((line = out.readLine()) != null)
- sb.append(line);
- out.close();
- return sb.toString();
- }
- public static String nlp(String func) throws IOException {
- URL url = new URL(u + func);
- StringBuffer sb = new StringBuffer();
- BufferedReader out = new BufferedReader(new InputStreamReader(url.openStream(), "utf-8"));
- String line;
- while ((line = out.readLine()) != null)
- sb.append(line);
- out.close();
- return sb.toString();
- }
- public static void main(String[] args) throws IOException {
- // 也可直接用IE访问 http://jkx.fudan.edu.cn/fudannlp/seg/开源中文自然语言处理工具包 FudanNLP
- System.out.println(welcome());
- System.out.println(nlp("key"));
- System.out.println(nlp("seg", "开源中文自然语言处理工具包 FudanNLP"));
- System.out.println(nlp("ner", "开源中文自然语言处理工具包 FudanNLP"));
- System.out.println(nlp("time", "2010-10-10"));
- }
- }















 1435
1435

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









