







竞赛概述
比赛地址:https://www.kaggle.com/c/dm2019springproj3
数据集为包含八类衣服的图片,目标是预测测试集中的衣服的类别。
获取测试集和验证集
准备原始数据
from typing import List
import logging
from typing import Optional
from functools import partial
from typing import Tuple
from typing import Union
from sklearn.model_selection import train_test_split
import torch.nn as nn
import numpy as np
import os
import pandas as pd
import torch
from torch.optim import Adam
from torchvision.models.resnet import BasicBlock
from torch.utils.data import DataLoader
from torch.utils.data import Dataset
from PIL import Image
from matplotlib import pyplot as plt
from torchvision.models.resnet import ResNet
from sklearn.metrics import roc_auc_score
from torch import Tensor
from torchvision import transforms
from torch.autograd import Variable
DATA_FOLDER = './image'
LABELS = './label.csv'
TRAIN_IMAGES_FOLDER = f'{DATA_FOLDER}/train'
def read_labels(path_to_file: str) -> pd.DataFrame:
labels = pd.read_csv(path_to_file)
return labels
def format_labels_for_dataset(labels: pd.DataFrame) -> np.array:
return labels['Cloth_label'].values.reshape(-1, 1)
def format_path_to_images_for_dataset(labels: pd.DataFrame, path: str) -> List:
return [os.path.join(path, f'{f}') for f in labels['Image'].values]
def get_mean_std(dataset, ratio=0.1):
"""Get mean and std by sample ratio
"""
dataloader = torch.utils.data.DataLoader(dataset, batch_size=int(len(dataset)*ratio),
shuffle=True)
train = iter(dataloader).next()[0]
mean = np.mean(train.numpy(), axis=(0,2,3))
std = np.std(train.numpy(), axis=(0,2,3))
return mean, std
分层抽样
def train_valid_split(df: pd.DataFrame) -> Tuple:
train,valid = train_test_split(df,test_size = 0.05,stratify=df['Cloth_label'])
return train, valid
数据集类
class MainDataset(Dataset):
def __init__(self,
x_dataset: Dataset,
y_dataset: Dataset,
x_tfms: Optional = None):
self.x_dataset = x_dataset
self.y_dataset = y_dataset
self.x_tfms = x_tfms
def __len__(self) -> int:
return self.x_dataset.__len__()
def __getitem__(self, index: int) -> Tuple:
x = self.x_dataset[index]
y = self.y_dataset[index]
if self.x_tfms is not None:
x = self.x_tfms(x)
return x, y
class ImageDataset(Dataset):
def __init__(self, paths_to_imgs: List):
self.paths_to_imgs = paths_to_imgs
def __len__(self) -> int:
return len(self.paths_to_imgs)
def __getitem__(self, index: int) -> Image.Image:
img = Image.open(self.paths_to_imgs[index])
img = img.convert('RGB')
return img
class LabelDataset(Dataset):
def __init__(self, labels: List):
self.labels = labels
def __len__(self) -> int:
return len(self.labels)
def __getitem__(self, index: int) -> int:
return self.labels[index]
labels = read_labels(LABELS)
train, valid = train_valid_split(labels)
train_labels = format_labels_for_dataset(train)
valid_labels = format_labels_for_dataset(valid)
train_images = format_path_to_images_for_dataset(train, TRAIN_IMAGES_FOLDER)
valid_images = format_path_to_images_for_dataset(valid, TRAIN_IMAGES_FOLDER)
train_images_dataset = ImageDataset(train_images)
valid_images_dataset = ImageDataset(valid_images)
train_labels_dataset = LabelDataset(train_labels)
valid_labels_dataset = LabelDataset(valid_labels)
加载数据
x_tfms = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor()
])
x_ttfms = transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor()
])
train_dataset = MainDataset(train_images_dataset, train_labels_dataset, x_ttfms)
valid_dataset = MainDataset(valid_images_dataset, valid_labels_dataset, x_tfms)
shuffle = True
batch_size = 64
train_dataloader = DataLoader(train_dataset,
batch_size=batch_size,
shuffle=shuffle)
valid_dataloader = DataLoader(valid_dataset,
batch_size=batch_size,
shuffle=False)
iter(train_dataloader).next()[0].shape
torch.Size([64, 3, 224, 224])
引入模型
import torchvision.models as models
save_path = './models/resnet101.pth'
model = models.resnet101()
saved_parametes = torch.load(save_path)
model.load_state_dict(saved_parametes)
count = 0
middle_optim = []
out_optim = []
for k in model.children():
count += 1
if count > 7:
for param in k.parameters():
out_optim.append(param)
elif count > 1:
for param in k.parameters():
middle_optim.append(param)
else :
for param in k.parameters():
param.requires_grad = False
model.fc = nn.Sequential(nn.Dropout(0.1), nn.Linear(2048, 8))
model
ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): Bottleneck(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(downsample): Sequential(
(0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(2): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
)
(layer2): Sequential(
(0): Bottleneck(
(conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(2): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(3): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
)
(layer3): Sequential(
(0): Bottleneck(
(conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(downsample): Sequential(
(0): Conv2d(512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(2): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(3): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(4): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(5): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(6): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(7): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(8): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(9): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(10): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(11): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(12): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(13): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(14): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(15): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(16): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(17): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(18): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(19): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(20): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(21): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(22): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
)
(layer4): Sequential(
(0): Bottleneck(
(conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(downsample): Sequential(
(0): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
(2): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
)
)
(avgpool): AvgPool2d(kernel_size=7, stride=1, padding=0)
(fc): Sequential(
(0): Dropout(p=0.1)
(1): Linear(in_features=2048, out_features=8, bias=True)
)
)
训练函数
def train(model, train_dataloader, loss_func, optimizer, device):
total_loss = 0
for i, (images, targets) in enumerate(train_dataloader):
images = images.to(device)
targets = targets.to(device).squeeze()
outputs = model(images)
# print(outputs.shape)
# print(targets.shape)
loss = loss_func(outputs, targets)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
if (i + 1) % 100 == 0:
print ("Step [{}/{}] Train Loss: {:.4f}"
.format(i+1, len(train_dataloader), loss.item()))
return total_loss / len(train_dataloader)
def evaluate(model, val_loader, train_dataloader, device):
"""
model: CNN networks
val_loader: a Dataloader object with validation data
device: evaluate on cpu or gpu device
return classification accuracy of the model on val dataset
"""
# evaluate the model
model.eval()
# context-manager that disabled gradient computation
with torch.no_grad():
correct = 0
total = 0
for i, (images, targets) in enumerate(train_dataloader):
images = images.to(device)
targets = targets.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1)
# print(predicted.shape, targets.shape)
correct += (predicted.reshape(-1,1) == targets).sum().item()
total += targets.size(0)
accuracy = correct / total
print('Accuracy on Train Set: {:.4f} %'.format(100 * accuracy))
correct = 0
total = 0
for i, (images, targets) in enumerate(val_loader):
images = images.to(device)
targets = targets.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1)
correct += (predicted.reshape(-1,1) == targets).sum().item()
total += targets.size(0)
accuracy = correct / total
print('Accuracy on Test Set: {:.4f} %'.format(100 * accuracy))
return accuracy
import matplotlib.pyplot as plt
# 画单条变化曲线
def show_curve(ys, title):
x = np.array(range(len(ys)))
y = np.array(ys)
plt.plot(x, y, c='b')
plt.axis()
plt.title('{} curve'.format(title))
plt.xlabel('epoch')
plt.ylabel('{}'.format(title))
plt.show()
# 画两条对比变化曲线
def show_double_curve(y1, y2, title, ylabel, label1, label2, locc = 'upper right'):
x = np.array(range(len(y1)))
y1 = np.array(y1)
y2 = np.array(y2)
plt.plot(x, y1, c='b', label = label1)
plt.plot(x, y2, c='r', label = label2)
plt.axis()
plt.title('{} curve'.format(title))
plt.xlabel('epoch')
plt.ylabel('{}'.format(ylabel))
plt.legend(bbox_to_anchor=(1.0, 1), borderaxespad=0, loc = locc)
plt.show()
# 画多条对比曲线
def show_multiple_curve(ys, title, ylabel, labels, locc = 'upper right'):
x = np.array(range(len(ys[0])))
for i in range(len(ys)):
plt.plot(x, np.array(ys[i]), label = labels[i])
plt.axis()
plt.title('{} curve'.format(title))
plt.xlabel('epoch')
plt.ylabel('{}'.format(ylabel))
plt.legend(bbox_to_anchor=(1.0, 1), borderaxespad=0, loc = locc)
plt.show()
def fit(model, num_epochs, optimizer, device):
# loss and optimizer
loss_func = nn.CrossEntropyLoss(weight=torch.tensor((1.0,1.0,1.0,1.0,1.0,1.1,1.0,1.0)))
model.to(device)
loss_func.to(device)
# log train loss and test accuracy
losses = []
accs = []
for epoch in range(num_epochs):
print('Epoch {}/{}:'.format(epoch + 1, num_epochs))
# train step
loss = train(model, train_dataloader, loss_func, optimizer, device)
losses.append(loss)
# evaluate step
accuracy = evaluate(model, valid_dataloader, train_dataloader, device)
accs.append(accuracy)
# 优化学习率的调整
if epoch%10 == 0:
for param_group in optimizer.param_groups:
param_group['lr'] = param_group['lr']*0.8
save_path = './resnet101-'+str(epoch)+'.pt'
torch.save(model.state_dict(), save_path)
# show curve
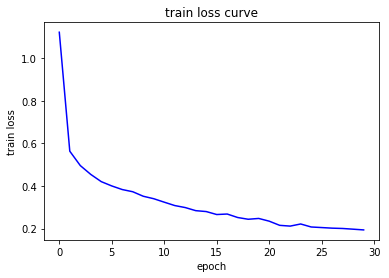
show_curve(losses, "train loss")
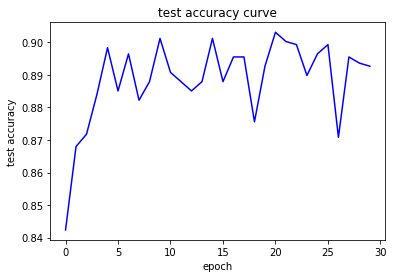
show_curve(accs, "test accuracy")
return losses, accs
开启训练
# Hyper-parameters
num_epochs = 30
lr = 1e-5
# Device configuration
device = torch.device('cuda:0')
# optimizer
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
fit(model, num_epochs, optimizer, device)
Epoch 1/30:
Step [100/313] Train Loss: 1.2160
Step [200/313] Train Loss: 0.9256
Step [300/313] Train Loss: 0.7754
Accuracy on Train Set: 80.0150 %
Accuracy on Test Set: 84.2355 %
Epoch 2/30:
Step [100/313] Train Loss: 0.3921
Step [200/313] Train Loss: 0.5579
Step [300/313] Train Loss: 0.6548
Accuracy on Train Set: 82.9407 %
Accuracy on Test Set: 86.7996 %
Epoch 3/30:
Step [100/313] Train Loss: 0.5355
Step [200/313] Train Loss: 0.5536
Step [300/313] Train Loss: 0.2885
Accuracy on Train Set: 84.3211 %
Accuracy on Test Set: 87.1795 %
Epoch 4/30:
Step [100/313] Train Loss: 0.4193
Step [200/313] Train Loss: 0.3024
Step [300/313] Train Loss: 0.5797
Accuracy on Train Set: 84.8662 %
Accuracy on Test Set: 88.4141 %
Epoch 5/30:
Step [100/313] Train Loss: 0.4501
Step [200/313] Train Loss: 0.4018
Step [300/313] Train Loss: 0.3488
Accuracy on Train Set: 85.9665 %
Accuracy on Test Set: 89.8386 %
Epoch 6/30:
Step [100/313] Train Loss: 0.3978
Step [200/313] Train Loss: 0.3459
Step [300/313] Train Loss: 0.3008
Accuracy on Train Set: 86.1265 %
Accuracy on Test Set: 88.5090 %
Epoch 7/30:
Step [100/313] Train Loss: 0.3948
Step [200/313] Train Loss: 0.4905
Step [300/313] Train Loss: 0.3760
Accuracy on Train Set: 87.3918 %
Accuracy on Test Set: 89.6486 %
Epoch 8/30:
Step [100/313] Train Loss: 0.5180
Step [200/313] Train Loss: 0.3036
Step [300/313] Train Loss: 0.4482
Accuracy on Train Set: 87.8420 %
Accuracy on Test Set: 88.2241 %
Epoch 9/30:
Step [100/313] Train Loss: 0.3126
Step [200/313] Train Loss: 0.3995
Step [300/313] Train Loss: 0.3744
Accuracy on Train Set: 88.6572 %
Accuracy on Test Set: 88.7939 %
Epoch 10/30:
Step [100/313] Train Loss: 0.2054
Step [200/313] Train Loss: 0.4323
Step [300/313] Train Loss: 0.3302
Accuracy on Train Set: 88.8522 %
Accuracy on Test Set: 90.1235 %
Epoch 11/30:
Step [100/313] Train Loss: 0.2355
Step [200/313] Train Loss: 0.5266
Step [300/313] Train Loss: 0.2800
Accuracy on Train Set: 89.1473 %
Accuracy on Test Set: 89.0788 %
Epoch 12/30:
Step [100/313] Train Loss: 0.2636
Step [200/313] Train Loss: 0.3671
Step [300/313] Train Loss: 0.2092
Accuracy on Train Set: 89.6974 %
Accuracy on Test Set: 88.7939 %
Epoch 13/30:
Step [100/313] Train Loss: 0.3200
Step [200/313] Train Loss: 0.3300
Step [300/313] Train Loss: 0.3699
Accuracy on Train Set: 89.6224 %
Accuracy on Test Set: 88.5090 %
Epoch 14/30:
Step [100/313] Train Loss: 0.2236
Step [200/313] Train Loss: 0.3208
Step [300/313] Train Loss: 0.1846
Accuracy on Train Set: 90.0725 %
Accuracy on Test Set: 88.7939 %
Epoch 15/30:
Step [100/313] Train Loss: 0.2346
Step [200/313] Train Loss: 0.3074
Step [300/313] Train Loss: 0.2684
Accuracy on Train Set: 90.8427 %
Accuracy on Test Set: 90.1235 %
Epoch 16/30:
Step [100/313] Train Loss: 0.1905
Step [200/313] Train Loss: 0.2527
Step [300/313] Train Loss: 0.2021
Accuracy on Train Set: 90.5626 %
Accuracy on Test Set: 88.7939 %
Epoch 17/30:
Step [100/313] Train Loss: 0.1206
Step [200/313] Train Loss: 0.3244
Step [300/313] Train Loss: 0.2537
Accuracy on Train Set: 90.9977 %
Accuracy on Test Set: 89.5537 %
Epoch 18/30:
Step [100/313] Train Loss: 0.1617
Step [200/313] Train Loss: 0.2114
Step [300/313] Train Loss: 0.4865
Accuracy on Train Set: 91.5579 %
Accuracy on Test Set: 89.5537 %
Epoch 19/30:
Step [100/313] Train Loss: 0.1708
Step [200/313] Train Loss: 0.0944
Step [300/313] Train Loss: 0.1791
Accuracy on Train Set: 90.4926 %
Accuracy on Test Set: 87.5594 %
Epoch 20/30:
Step [100/313] Train Loss: 0.1717
Step [200/313] Train Loss: 0.1779
Step [300/313] Train Loss: 0.2752
Accuracy on Train Set: 91.4179 %
Accuracy on Test Set: 89.2688 %
Epoch 21/30:
Step [100/313] Train Loss: 0.1503
Step [200/313] Train Loss: 0.4163
Step [300/313] Train Loss: 0.1866
Accuracy on Train Set: 92.2381 %
Accuracy on Test Set: 90.3134 %
Epoch 22/30:
Step [100/313] Train Loss: 0.2909
Step [200/313] Train Loss: 0.2325
Step [300/313] Train Loss: 0.2737
Accuracy on Train Set: 92.7832 %
Accuracy on Test Set: 90.0285 %
Epoch 23/30:
Step [100/313] Train Loss: 0.1519
Step [200/313] Train Loss: 0.3601
Step [300/313] Train Loss: 0.2178
Accuracy on Train Set: 92.8632 %
Accuracy on Test Set: 89.9335 %
Epoch 24/30:
Step [100/313] Train Loss: 0.0935
Step [200/313] Train Loss: 0.2453
Step [300/313] Train Loss: 0.2041
Accuracy on Train Set: 92.5181 %
Accuracy on Test Set: 88.9839 %
Epoch 25/30:
Step [100/313] Train Loss: 0.4866
Step [200/313] Train Loss: 0.2984
Step [300/313] Train Loss: 0.0891
Accuracy on Train Set: 92.7982 %
Accuracy on Test Set: 89.6486 %
Epoch 26/30:
Step [100/313] Train Loss: 0.1899
Step [200/313] Train Loss: 0.1949
Step [300/313] Train Loss: 0.3306
Accuracy on Train Set: 93.0283 %
Accuracy on Test Set: 89.9335 %
Epoch 27/30:
Step [100/313] Train Loss: 0.3766
Step [200/313] Train Loss: 0.2792
Step [300/313] Train Loss: 0.1051
Accuracy on Train Set: 90.6827 %
Accuracy on Test Set: 87.0845 %
Epoch 28/30:
Step [100/313] Train Loss: 0.2363
Step [200/313] Train Loss: 0.1957
Step [300/313] Train Loss: 0.2659
Accuracy on Train Set: 93.2383 %
Accuracy on Test Set: 89.5537 %
Epoch 29/30:
Step [100/313] Train Loss: 0.0640
Step [200/313] Train Loss: 0.2918
Step [300/313] Train Loss: 0.1198
Accuracy on Train Set: 93.5134 %
Accuracy on Test Set: 89.3637 %
Epoch 30/30:
Step [100/313] Train Loss: 0.1177
Step [200/313] Train Loss: 0.1807
Step [300/313] Train Loss: 0.1878
Accuracy on Train Set: 93.2833 %
Accuracy on Test Set: 89.2688 %
生成预测结果
import os
from PIL import Image
def get_resultcsv(model):
path = f'{DATA_FOLDER}/test/'
# df = pd.read_csv('sample_submission.csv')
imgs = os.listdir(path)
model.eval()
label = []
i = 0
with torch.no_grad():
for name in imgs:
i += 1
img = Image.open(path+name)
img = img.convert('RGB')
img = x_tfms(img)
s = model(img.unsqueeze(0).to(device))
_, pre = torch.max(s.data, dim=1)
label.append(pre.item())
if i%200 == 0:
print ("Step [{}/{}] prediction!".format(i, len(imgs)))
df = pd.DataFrame({'Image': [x for x in imgs],'Cloth_label':label})
df.to_csv("result.csv",index=False,sep=',')
get_resultcsv(model)
Step [200/4500] prediction!
Step [400/4500] prediction!
Step [600/4500] prediction!
Step [800/4500] prediction!
Step [1000/4500] prediction!
...
Step [4200/4500] prediction!
Step [4400/4500] prediction!
def evaluate_result(predict, label):
import numpy as np
total = np.zeros(8)
correct = np.zeros(8)
for p, l in zip(predict, label):
total[l] += 1
if p == l:
correct[p] += 1
for i in range(8):
print('第'+str(i)+'类预测的准确率为'+str(correct[i]/total[i])+'——('+str(correct[i])+'/'+str(total[i])+')')
print('总准确率为:'+str(np.sum(correct)/np.sum(total))+'——('+str(np.sum(correct))+'/'+str(np.sum(total))+')')
def evaluate_model(model):
model.eval()
with torch.no_grad():
predict = []
label = []
print('训练集准确率:')
for i, (images, targets) in enumerate(train_dataloader):
s = model(images.to(device))
_, pre = torch.max(s.data, dim=1)
predict += list(pre.cpu().numpy())
label += list(targets.cpu().numpy())
evaluate_result(predict, label)
predict = []
label = []
print('验证准确率:')
for i, (images, targets) in enumerate(valid_dataloader):
s = model(images.to(device))
_, pre = torch.max(s.data, dim=1)
predict += list(pre.cpu().numpy())
label += list(targets.cpu().numpy())
evaluate_result(predict, label)
evaluate_model(model)
训练集准确率:
第0类预测的准确率为0.923959827834——(1288.0/1394.0)
第1类预测的准确率为0.917473255222——(1801.0/1963.0)
第2类预测的准确率为0.975753991721——(1650.0/1691.0)
第3类预测的准确率为0.930970724191——(3021.0/3245.0)
第4类预测的准确率为0.972012917115——(1806.0/1858.0)
第5类预测的准确率为0.757729580065——(1642.0/2167.0)
第6类预测的准确率为0.941563786008——(2288.0/2430.0)
第7类预测的准确率为0.973127501429——(5106.0/5247.0)
总准确率为:0.930332583146——(18602.0/19995.0)
验证准确率:
第0类预测的准确率为0.905405405405——(67.0/74.0)
第1类预测的准确率为0.893203883495——(92.0/103.0)
第2类预测的准确率为0.943820224719——(84.0/89.0)
第3类预测的准确率为0.894736842105——(153.0/171.0)
第4类预测的准确率为0.989795918367——(97.0/98.0)
第5类预测的准确率为0.649122807018——(74.0/114.0)
第6类预测的准确率为0.9453125——(121.0/128.0)
第7类预测的准确率为0.913043478261——(252.0/276.0)
总准确率为:0.892687559354——(940.0/1053.0)















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











