







文章目录
模型加载
numpy: NumPy is the fundamental package for scientific computing in Python.
pytorch: End-to-end deep learning platform.
torchvision: This package consists of popular datasets, model architectures, and common image transformations for computer vision.
tensorboard: A suite of visualization tools to make training easier to understand, debug, and optimize TensorFlow programs.
tensorboardX: Tensorboard for Pytorch.
'''step 1'''
# Load all necessary modules here, for clearness
import torch
import numpy as np
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
# from torchvision.datasets import MNIST
import torchvision
from torchvision import transforms
from torch.optim import lr_scheduler
# from tensorboardX import SummaryWriter
from collections import OrderedDict
from matplotlib import pyplot as plt
'''step 2'''
# Whether to put data in GPU according to GPU is available or not
# cuda = torch.cuda.is_available()
# In case the default gpu does not have enough space, you can choose which device to use
# torch.cuda.set_device(device) # device: id
# Since gpu in lab is not enough for your guys, we prefer to cpu computation
device = torch.device("cuda:0")
随机种子设定与参数优化
In order to make computations deterministic on your specific problem on one specific platform and PyTorch release, there are a couple of steps to take.
'''step 3'''
# However, in the same exp, seed for torch and numpy doesn't be the same.
SEED = 47
# Sets the seed for generating random numbers, including GPU and CPU
torch.manual_seed(SEED)
# Deterministic algorithm for convolutional ops
# 采用确定性卷积:(相当于把所有操作的seed=0,以便重现,会变慢)
torch.backends.cudnn.deterministic = True
# Deterministic alogorithm for cudnn, otherwise, cuddn would choose the fastest algorithm for every
# iteration ops, which cause variability and time consuming if input changes frequently.
# 使用benchmark以启动CUDNN_FIND自动寻找最快的操作,当计算图不会改变的时候(每次输入形状相同,模型不改变)的情况下可以提高性能,反之则降低性能
torch.backends.cudnn.benchmark = False
# Seed the generator for Numpy
np.random.seed(SEED)
# torch.cuda.emptyCache()释放PyTorch的缓存分配器中的缓存内存块。当与其他进程共享GPU时特别有用。
数据分割与交叉验证
We would split Cifar10 into 5-fold and do cross validation.
The Cifar10 database (Modified National Institute of Standards and Technology database) s a collection of images that are commonly used to train machine learning and computer vision algorithms.
The CIFAR-10 dataset contains 60,000 32x32 color images in 10 different classes. The 10 different classes represent airplanes, cars, birds, cats, deer, dogs, frogs, horses, ships, and trucks. There are 6,000 images of each class
And they look like images below.

sklearn方式进行五折交叉验证
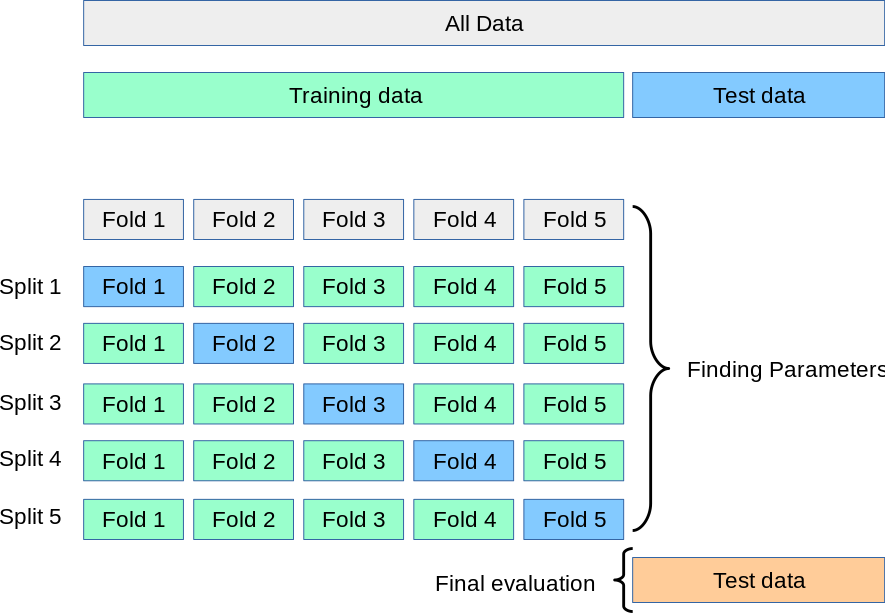
# Example to use kFold
from sklearn.model_selection import KFold
import numpy as np
train_transform = transforms.Compose([
])
dataset = torchvision.datasets.CIFAR10(root='./data',
train=True, transform=train_transform,download=True)
data = dataset.data
# dataset.train_labels gets list object, we should transform to numpy for convinience
label = np.array(dataset.targets)
# set numpy random seed, we can get a determinate k-fold dataset
# np.random.seed(1)
kf = KFold(n_splits=5,shuffle=True)
for train_index, test_index in kf.split(data):
print('train_index', train_index, 'test_index', test_index)
train_data, train_label = data[train_index], label[train_index]
test_data, test_label = data[test_index], label[test_index]
# here we use the last fold to be our trainset
dataset.train_data = train_data
dataset.train_labels = list(train_label)
Files already downloaded and verified
train_index [ 0 1 2 ... 49997 49998 49999] test_index [ 9 13 18 ... 49988 49990 49996]
train_index [ 1 2 3 ... 49996 49998 49999] test_index [ 0 5 7 ... 49992 49995 49997]
train_index [ 0 1 5 ... 49996 49997 49999] test_index [ 2 3 4 ... 49985 49994 49998]
train_index [ 0 2 3 ... 49997 49998 49999] test_index [ 1 10 11 ... 49970 49973 49989]
train_index [ 0 1 2 ... 49996 49997 49998] test_index [ 14 22 27 ... 49991 49993 49999]
计算训练集图片的均值和方差
def get_mean_std(dataset, ratio=0.01):
"""Get mean and std by sample ratio
"""
dataloader = torch.utils.data.DataLoader(dataset, batch_size=int(len(dataset)*ratio),
shuffle=True)
train = iter(dataloader).next()[0]
print(train.shape)
mean = np.mean(train.numpy(), axis=(0,2,3))
std = np.std(train.numpy(), axis=(0,2,3))
return mean, std
# cifar10
train_dataset = torchvision.datasets.CIFAR10('./data',
train=True, download=False,
transform=transforms.ToTensor())
test_dataset = torchvision.datasets.CIFAR10('./data',
train=False, download=False,
transform=transforms.ToTensor())
train_mean, train_std = get_mean_std(train_dataset)
test_mean, test_std = get_mean_std(test_dataset)
print(train_mean, train_std)
print(test_mean,test_std)
torch.Size([500, 3, 32, 32])
torch.Size([100, 3, 32, 32])
[0.49301627 0.47958794 0.43843597] [0.24912699 0.24832442 0.26424718]
[0.50443375 0.49348345 0.46726856] [0.23770633 0.23433787 0.25186613]
超参数设置
'''step 4'''
# set hyper parameter
batch_size = 32
n_epochs = 50
learning_rate = 1e-3
数据增广
Using suitable data augmentation usually can get a better model. However, not all augmentation function are effective to all dataset It is advisable to choose favorable function for our dataset.
transform document:[https://pytorch.org/docs/stable/torchvision/transforms.html]
here are the most commonly used functions you may interest
- torchvision.transforms.Compose()
- torchvision.transforms.CenterCrop()
- torchvision.transforms.Pad()
- torchvision.transforms.RandomCrop()
- torchvision.transforms.RandomHorizontalFlip()
- torchvision.transforms.Resize()
- torchvision.transforms.Normalize()
- torchvision.transforms.ToPILImage()
- torchvision.transforms.ToTensor()
- torchvision.transforms.RandomRotation()
There is not standard answer for how to choose a suitable augmentation for your dataset, but we try to teach you what may be useful.
We use cifar10 as our dataset in this class. so, here are some suggestion when you use it.
The size of images in cifar10 are 32×32, it maybe not suitable to choose rotation operation for the images, becuase rotation will bring black pixels, those black pixels may exist after randomcrop operation.
we suggest that you can consider to use horizontal flip in nature dataset but not use vertical flip. becuase you know it is very rare for an object to be inverted.
%matplotlib inline
from PIL import Image
# rotate 30°
transform_rotate = transforms.RandomRotation((30,30))
transform_horizontalflip = transforms.RandomHorizontalFlip(p=1)
transform_verticalflip = transforms.RandomVerticalFlip(p=1)
# the first image in cifar10 trainset
img = Image.open('./img/example.jpg')
plt.imshow(img)
plt.axis('off')
plt.show()

# a cat image
img1 = Image.open('./img/cat.jpeg')
plt.imshow(img1)
plt.axis('off')
plt.show()

# rotate the image
img2 = transform_rotate(img1)
plt.imshow(img2)
plt.axis('off')
plt.show()

# horizontal flip the image
img3 = transform_horizontalflip(img1)
plt.imshow(img3)
plt.axis('off')
plt.show()

# vertical flip the image
img4 = transform_verticalflip(img1)
plt.imshow(img4)
plt.axis('off')
plt.show()

'''step 5'''
'''
the mean and variance below are from get_mean_std() function, every time you run the above function may get
defferent value, because we use sampling
'''
'''
notice: we usually will not use the dataset above, because its transform function has been change the numpy
data to tensor data, but those transformations such as filp, rotation, crop, pad should be done before the
data transforms to tensor.
'''
train_transform = transforms.Compose([
transforms.RandomHorizontalFlip(),
# transforms.RandomRotation(10),
transforms.ToTensor(), # Convert a PIL Image or numpy.ndarray to tensor.
# Normalize a tensor image with mean 0.1307 and standard deviation 0.3081
transforms.Normalize((0.4924044, 0.47831464, 0.44143882), (0.25063434, 0.2492162, 0.26660094))
])
# transform2
# train_transform = transforms.Compose([
# transforms.RandomCrop(32, padding=4),
# transforms.RandomHorizontalFlip(),
# transforms.ToTensor(),
# transforms.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5))])
test_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.49053448, 0.47128814, 0.43724576), (0.24659537, 0.24846372, 0.26557055))
])
train_dataset = torchvision.datasets.CIFAR10(root='./data',
train=True,
transform=train_transform,
download=True)
test_dataset = torchvision.datasets.CIFAR10(root='./data',
train=False,
transform=test_transform,
download=False)
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=False)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset,
batch_size=batch_size,
shuffle=False)
Files already downloaded and verified
分类网络
引入resnet18
resnet18 = torchvision.models.resnet18()
print(resnet18)
ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer2): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer3): Sequential(
(0): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer4): Sequential(
(0): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(avgpool): AvgPool2d(kernel_size=7, stride=1, padding=0)
(fc): Linear(in_features=512, out_features=1000, bias=True)
)
在原始模型的基础上进行更改
As we can see, the resnet model we import from torchvison.models downsamples five times, It means that the size of feature maps in avgpooling layer is only 1×1, we may lose too much information during the convolution layers. It’s worth noting that before enter the blocks, the input images have been downsapled tow times, we lose lots of information. so, fixing the first two downsaple layer may be a good choise.
'''step 6'''
class ResNet18(nn.Module):
def __init__(self):
super(ResNet18,self).__init__()
original_model = torchvision.models.resnet18()
original_model.conv1.stride = 1
self.feature_extractor = nn.Sequential(
*(list(original_model.children())[0:3]),
*(list(original_model.children())[4:-2]),
nn.AdaptiveAvgPool2d(1)
)
self.fc = nn.Linear(512,10)
def forward(self, x):
out1 = self.feature_extractor(x)
out1 = out1.view(out1.size(0),-1)
out2 = self.fc(out1)
return out2
print(ResNet18())
ResNet18(
(feature_extractor): Sequential(
(0): Conv2d(3, 64, kernel_size=(7, 7), stride=1, padding=(3, 3), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace)
(3): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(4): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(5): Sequential(
(0): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(6): Sequential(
(0): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(7): AdaptiveAvgPool2d(output_size=1)
)
(fc): Linear(in_features=512, out_features=10, bias=True)
)
模型训练
We would define training function here. Additionally, hyper-parameters, loss function, metric would be included here too.
设置超参数
setting hyperparameters like below
hyper paprameters include following part
- learning rate: usually we start from a quite bigger lr like 1e-1, 1e-2, 1e-3, and slow lr as epoch moves.
- n_epochs: training epoch must set large so model has enough time to converge. Usually, we will set a quite big epoch at the first training time.
- batch_size: usually, bigger batch size mean’s better usage of GPU and model would need less epoches to converge. And the exponent of 2 is used, eg. 2, 4, 8, 16, 32, 64, 128. 256. (方便性能优化。因为线程数通常是这种数字)
'''step 7'''
# create a model object
# model = torchvision.models.resnet18()
# model.avgpool = nn.AdaptiveAvgPool2d(1)
# model.fc = nn.Linear(512,10)
model = ResNet18()
model.to(device)
# Cross entropy
loss_fn = torch.nn.CrossEntropyLoss()
# l2_norm can be done in SGD
# optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate, momentum=0.9)
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate, betas=(0.9, 0.99))
对模型参数进行初始化
Pytorch provide default initialization (uniform intialization) for linear layer. But there is still some useful intialization method.
Read more about initialization from this link
torch.nn.init.normal_
torch.nn.init.uniform_
torch.nn.init.constant_
torch.nn.init.eye_
torch.nn.init.xavier_uniform_
torch.nn.init.xavier_normal_
torch.nn.init.kaiming_uniform_
训练流程
- Shuffle whole training data
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True, **kwargs)
-
For each mini-batch data
- load mini-batch data
for batch_idx, (data, target) in enumerate(train_loader): \ ...- compute gradient of loss over parameters
output = net(data) # make prediction loss = loss_fn(output, target) # compute loss loss.backward() # compute gradient of loss over parameters- update parameters with gradient descent
optimzer.step() # update parameters with gradient descent
'''step 8'''
def train(train_loader, model, loss_fn, optimizer,device):
"""train model using loss_fn and optimizer. When thid function is called, model trains for one epoch.
Args:
train_loader: train data
model: prediction model
loss_fn: loss function to judge the distance between target and outputs
optimizer: optimize the loss function
Returns:
total_loss: loss
"""
# set the module in training model, affecting module e.g., Dropout, BatchNorm, etc.
model.train()
total_loss = 0
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad() # clear gradients of all optimized torch.Tensors'
outputs = model(data) # make predictions
loss = loss_fn(outputs, target) # compute loss
total_loss += loss.item() # accumulate every batch loss in a epoch
loss.backward() # compute gradient of loss over parameters
optimizer.step() # update parameters with gradient descent
average_loss = total_loss / batch_idx # average loss in this epoch
return average_loss
'''step 9'''
def evaluate(loader, model, loss_fn, device):
"""test model's prediction performance on loader.
When thid function is called, model is evaluated.
Args:
loader: data for evaluation
model: prediction model
loss_fn: loss function to judge the distance between target and outputs
Returns:
total_loss
accuracy
"""
# context-manager that disabled gradient computation
with torch.no_grad():
# set the module in evaluation mode
model.eval()
correct = 0.0 # account correct amount of data
total_loss = 0 # account loss
for batch_idx, (data, target) in enumerate(loader):
data, target = data.to(device), target.to(device)
outputs = model(data) # make predictions
# return the maximum value of each row of the input tensor in the
# given dimension dim, the second return vale is the index location
# of each maxium value found(argmax)
_, predicted = torch.max(outputs, 1)
# Detach: Returns a new Tensor, detached from the current graph.
#The result will never require gradient.
correct += (predicted == target).cpu().sum().detach().numpy()
loss = loss_fn(outputs, target) # compute loss
total_loss += loss.item() # accumulate every batch loss in a epoch
accuracy = correct*100.0 / len(loader.dataset) # accuracy in a epoch
average_loss = total_loss / len(loader)
return average_loss, accuracy
Define function fit and use train_epoch and test_epoch
In this section we will produce tow method to change learning rate during the period of training
-
use optimizer.param_groups to change the learning rate in the optimizer at any epoch you want**(任意手动调整学习率)**
-
use optimizer.lr_scheduler.StepLR() to change the learning rate in the optimizer every several of epoch**(使用函数调整学习率)**
when you find training loss and accuracy tend to be gentle, it maybe usful to decay the learning rate, but it is not always effective, you should do more experience to choose a suitable hyper parameters for your model
'''step 10'''
def fit(train_loader, val_loader, model, loss_fn, optimizer, n_epochs, device):
"""train and val model here, we use train_epoch to train model and
val_epoch to val model prediction performance
Args:
train_loader: train data
val_loader: validation data
model: prediction model
loss_fn: loss function to judge the distance between target and outputs
optimizer: optimize the loss function
n_epochs: training epochs
Returns:
train_accs: accuracy of train n_epochs, a list
train_losses: loss of n_epochs, a list
"""
train_accs = [] # save train accuracy every epoch
train_losses = [] # save train loss every epoch
test_accs = []
test_losses = []
# scheduler = lr_scheduler.StepLR(optimizer,step_size=6,gamma=0.1)
for epoch in range(n_epochs): # train for n_epochs
# train model on training datasets, optimize loss function and update model parameters
# change the learning rate at any epoch you want
# if n_epochs % 6 == 0 and n_epochs != 0:
# lr = lr * 0.1
# for param_group in optimizer.param_groups:
# param_groups['lr'] = lr
train_loss= train(train_loader, model, loss_fn, optimizer, device=device)
# evaluate model performance on train dataset
_, train_accuracy = evaluate(train_loader, model, loss_fn, device=device)
# change the learning rate by scheduler
# scheduler.step()
message = 'Epoch: {}/{}. Train set: Average loss: {:.4f}, Accuracy: {:.4f}'.format(epoch+1, \
n_epochs, train_loss, train_accuracy)
print(message)
# save loss, accuracy
train_accs.append(train_accuracy)
train_losses.append(train_loss)
show_curve(train_accs,'tranin_accs')
show_curve(train_losses,'train_losses')
# evaluate model performance on val dataset
val_loss, val_accuracy = evaluate(val_loader, model, loss_fn, device=device)
test_accs.append(val_accuracy)
test_losses.append(val_loss)
show_curve(test_accs,'test_accs')
show_curve(test_losses,'test_losses')
if epoch%7 == 0:
for param_group in optimizer.param_groups:
param_group['lr'] = param_group['lr']*0.98
message = 'Epoch: {}/{}. Validation set: Average loss: {:.4f}, Accuracy: {:.4f}'.format(epoch+1, \
n_epochs, val_loss, val_accuracy)
print(message)
return train_accs, train_losses
'''step 10'''
def show_curve(ys, title):
"""plot curlve for Loss and Accuacy
!!YOU CAN READ THIS LATER, if you are interested
Args:
ys: loss or acc list
title: Loss or Accuracy
"""
x = np.array(range(len(ys)))
y = np.array(ys)
plt.plot(x, y, c='b')
plt.axis()
plt.title('{} Curve:'.format(title))
plt.xlabel('Epoch')
plt.ylabel('{} Value'.format(title))
plt.show()
'''step 12'''
train_accs, train_losses = fit(train_loader, test_loader, model, loss_fn, optimizer, n_epochs, device=device)
保存模型
Pytorch provide two kinds of method to save model. We recommmend the method which only saves parameters. Because it’s more feasible and dont’ rely on fixed model.
When saving parameters, we not only save learnable parameters in model, but also learnable parameters in optimizer.
A common PyTorch convention is to save models using either a .pt or .pth file extension.
Read more abount save load from this link
Generally speaking, to save our disk space and training time, we usually save the best model in Verification set and the last model for the last epoch.
the next cell will show you how to save the parameters of model and models.
# to save the parameters of a model
torch.save(model.state_dict(), './params/resnet18_params.pt')
# to save the model
torch.save(model, './params/resnet18.pt')
You can get your the performance of your model at test set in every epoch. so, you can save the best model during the training period. Please add this function into your train() function
迁移学习
In this section, you will learn how to load the parameters you trained to your new model
model1 = torchvision.models.resnet18()
print(model1.state_dict())
# generate a parameters file of model1
torch.save(model1.state_dict(),'./params/resnet18_params.pt')
model2 = torchvision.models.resnet18()
model2.fc = nn.Linear(512,10)
Now, we want to load model1’s parameters to model2, however, they have different structure, we can’t simply use model2.load() or model2.load_state_dict(). we should load part of the parameters of the model1 to model2. For examlpe, if we want to load the convolution layers parameters, we can do like below.
'''
parameters are saved as dict in .pt file, so, we should get its keys first.
'''
print(model2.state_dict().keys())
odict_keys(['conv1.weight', 'bn1.weight', 'bn1.bias', 'bn1.running_mean', 'bn1.running_var', 'bn1.num_batches_tracked', 'layer1.0.conv1.weight', 'layer1.0.bn1.weight', 'layer1.0.bn1.bias', 'layer1.0.bn1.running_mean', 'layer1.0.bn1.running_var', 'layer1.0.bn1.num_batches_tracked', 'layer1.0.conv2.weight', 'layer1.0.bn2.weight', 'layer1.0.bn2.bias', 'layer1.0.bn2.running_mean', 'layer1.0.bn2.running_var', 'layer1.0.bn2.num_batches_tracked', 'layer1.1.conv1.weight', 'layer1.1.bn1.weight', 'layer1.1.bn1.bias', 'layer1.1.bn1.running_mean', 'layer1.1.bn1.running_var', 'layer1.1.bn1.num_batches_tracked', 'layer1.1.conv2.weight', 'layer1.1.bn2.weight', 'layer1.1.bn2.bias', 'layer1.1.bn2.running_mean', 'layer1.1.bn2.running_var', 'layer1.1.bn2.num_batches_tracked', 'layer2.0.conv1.weight', 'layer2.0.bn1.weight', 'layer2.0.bn1.bias', 'layer2.0.bn1.running_mean', 'layer2.0.bn1.running_var', 'layer2.0.bn1.num_batches_tracked', 'layer2.0.conv2.weight', 'layer2.0.bn2.weight', 'layer2.0.bn2.bias', 'layer2.0.bn2.running_mean', 'layer2.0.bn2.running_var', 'layer2.0.bn2.num_batches_tracked', 'layer2.0.downsample.0.weight', 'layer2.0.downsample.1.weight', 'layer2.0.downsample.1.bias', 'layer2.0.downsample.1.running_mean', 'layer2.0.downsample.1.running_var', 'layer2.0.downsample.1.num_batches_tracked', 'layer2.1.conv1.weight', 'layer2.1.bn1.weight', 'layer2.1.bn1.bias', 'layer2.1.bn1.running_mean', 'layer2.1.bn1.running_var', 'layer2.1.bn1.num_batches_tracked', 'layer2.1.conv2.weight', 'layer2.1.bn2.weight', 'layer2.1.bn2.bias', 'layer2.1.bn2.running_mean', 'layer2.1.bn2.running_var', 'layer2.1.bn2.num_batches_tracked', 'layer3.0.conv1.weight', 'layer3.0.bn1.weight', 'layer3.0.bn1.bias', 'layer3.0.bn1.running_mean', 'layer3.0.bn1.running_var', 'layer3.0.bn1.num_batches_tracked', 'layer3.0.conv2.weight', 'layer3.0.bn2.weight', 'layer3.0.bn2.bias', 'layer3.0.bn2.running_mean', 'layer3.0.bn2.running_var', 'layer3.0.bn2.num_batches_tracked', 'layer3.0.downsample.0.weight', 'layer3.0.downsample.1.weight', 'layer3.0.downsample.1.bias', 'layer3.0.downsample.1.running_mean', 'layer3.0.downsample.1.running_var', 'layer3.0.downsample.1.num_batches_tracked', 'layer3.1.conv1.weight', 'layer3.1.bn1.weight', 'layer3.1.bn1.bias', 'layer3.1.bn1.running_mean', 'layer3.1.bn1.running_var', 'layer3.1.bn1.num_batches_tracked', 'layer3.1.conv2.weight', 'layer3.1.bn2.weight', 'layer3.1.bn2.bias', 'layer3.1.bn2.running_mean', 'layer3.1.bn2.running_var', 'layer3.1.bn2.num_batches_tracked', 'layer4.0.conv1.weight', 'layer4.0.bn1.weight', 'layer4.0.bn1.bias', 'layer4.0.bn1.running_mean', 'layer4.0.bn1.running_var', 'layer4.0.bn1.num_batches_tracked', 'layer4.0.conv2.weight', 'layer4.0.bn2.weight', 'layer4.0.bn2.bias', 'layer4.0.bn2.running_mean', 'layer4.0.bn2.running_var', 'layer4.0.bn2.num_batches_tracked', 'layer4.0.downsample.0.weight', 'layer4.0.downsample.1.weight', 'layer4.0.downsample.1.bias', 'layer4.0.downsample.1.running_mean', 'layer4.0.downsample.1.running_var', 'layer4.0.downsample.1.num_batches_tracked', 'layer4.1.conv1.weight', 'layer4.1.bn1.weight', 'layer4.1.bn1.bias', 'layer4.1.bn1.running_mean', 'layer4.1.bn1.running_var', 'layer4.1.bn1.num_batches_tracked', 'layer4.1.conv2.weight', 'layer4.1.bn2.weight', 'layer4.1.bn2.bias', 'layer4.1.bn2.running_mean', 'layer4.1.bn2.running_var', 'layer4.1.bn2.num_batches_tracked', 'fc.weight', 'fc.bias'])
We can see the last layer of convolution is ‘layer4.1.bn2.num_batches_tracked’. Now, let’s load it to our new model.
pretrained_params = torch.load('./params/resnet18_params.pt')
model2_params = model2.state_dict()
for (pretrained_key,pretrained_val), (model2_key,model2_val) in zip(list(pretrained_params.items()),list(model2_params.items())):
model2_params[model2_key] = pretrained_val
if model2_key == 'layer4.1.bn2.num_batches_tracked':
break
# don't forget to load parametes dict to your model!!!
model2.load_state_dict(model2_params)
print(model1.state_dict())
print(model2.state_dict())
模型集成
when you trained your model for several times, you can emsemble those models to predict test set.
for example, if you trained three models using the same train set, when a new image arrivied, it will be sent to those models and get three predictions, you can design a voting mechanism to improve the performance of your model.















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











