







http://cjp1989.iteye.com/blog/1856613 这篇文章已经介绍了ictclas在win32位下面的配置,下载他的源码,那个工程师可以直接运行的。
这里是在那篇文章的基础上介绍ictclas在win64位下面的配置,以及如何解决UTF-8乱码的问题。
1、首先下载那个作者的文件,导入到工程中去

2、去http://ictclas.nlpir.org/downloads 下载64位的JNI:
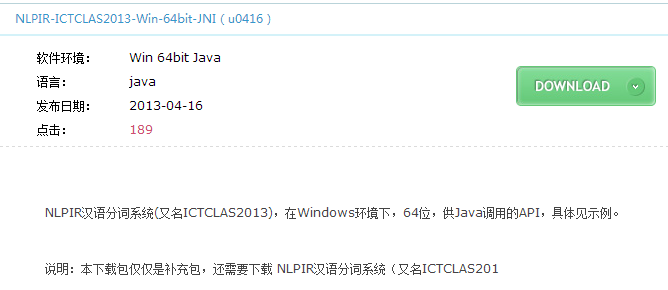
3、用下载得到的文件替换原来工程中的文件
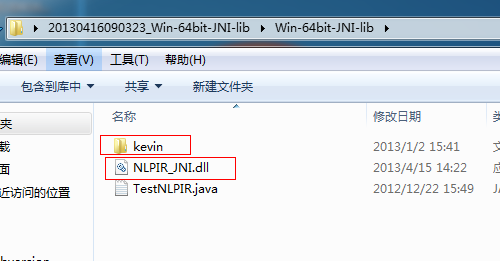
上面是下载的

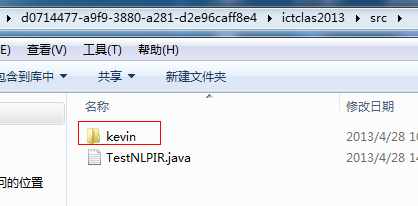
上面两个是等待被替换的
4、把工程文本编码方式改成utf-8
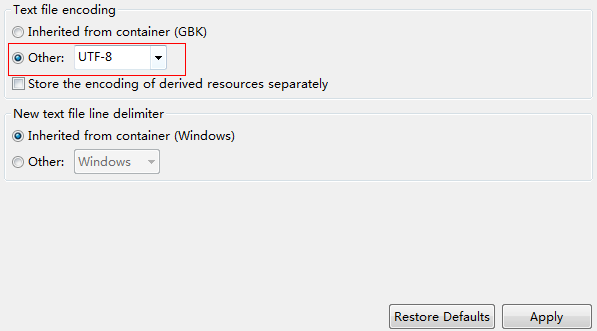
5、自己写utf-8格式文件的读取方式,不要用工程中的NLPIR_GetFileKeyWords()函数
全部代码如下:
import kevin.zhang.NLPIR;
import java.util.*;
import java.io.*;
public class TestNLPIR {
public static void main(String[] args) throws Exception{
String filePath = "./test/test-utf8.TXT";
String tt=new String();
try{
BufferedReader in = new BufferedReader(new InputStreamReader(new FileInputStream(filePath), "UTF8"));
String str;
while ((str = in.readLine()) != null) {
tt+=str;
}
test(tt);
}
catch (Exception ex){
}
}
public static void test(String sInput){
try{
System.out.println(sInput);
NLPIR testNLPIR = new NLPIR();
String argu = "./file/";
System.out.println("NLPIR_Init");
if (testNLPIR.NLPIR_Init(argu.getBytes("GB2312"),0) == false){
System.out.println("Init Fail!");
return;
}
byte nativeBytes[]=testNLPIR.NLPIR_GetKeyWords(sInput.getBytes("GB2312"), 20, true);
String nativeStr = new String(nativeBytes, 0, nativeBytes.length, "GB2312");
String outline[] = new String[50];
outline = nativeStr.split(" ", -1);
System.out.println("关键词识别结果为:");
for(int i=0;i<outline.length;i++){
String newoutline[] = new String[3];
newoutline=outline[i].split("/",-1);
System.out.println(newoutline[0]+","+newoutline[2]);
}
testNLPIR.NLPIR_Exit();
}
catch (Exception ex){
}
}
}
前面提到过如何用FudanNLP提取关键字,但是组长不满意,只好换成了ictclas,希望这下不要再折腾了吧。















 9601
9601

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









