







学过数据挖掘和机器学习课的人估计都知道有weka这么一个开源软件,这个软件实现了很多聚类,分类算法。如果没有接触过这个软件,可以参看这篇文章,看完后基本就了解的差不多了: http://blog.csdn.net/yangliuy/article/details/7589306
当然,很多情况下我们不是直接使用这个软件,而是希望把软件中的算法拿过来集成到我们自己的系统中,也就是通常意义上的二次开发。由于weka是开源的,二次开发自然很方面。下面来简单说说如何进行二次开发。
首先在本地安装weka,在安装目录下找到jar包
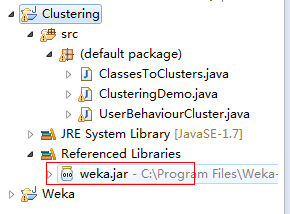
在eclipse下新建一个工程,导入weka的jar包
接下来就可以尽情使用weka里面提供的算法了,这里我使用的EM算法对用户进行聚类
import java.io.*;
import weka.core.*;
import weka.clusterers.*;
import weka.filters.*;
import weka.filters.unsupervised.attribute.Remove;
/**
* This class shows how to perform a "classes-to-clusters"
* evaluation like in the Explorer using EM. The class needs as
* first parameter an ARFF file to work on. The last attribute is
* interpreted as the class attribute.
* <p/>
* This code is based on the method "startClusterer" of the
* "weka.gui.explorer.ClustererPanel" class and the
* "evaluateClusterer" method of the "weka.clusterers.ClusterEvaluation"
* class.
*
* @author FracPete (fracpete at waikato dot ac dot nz)
*/
public class ClassesToClusters {
public static void main(String[] args) throws Exception {
// load data
BufferedReader reader = new BufferedReader(new FileReader("C:/Users/felven/Desktop/1.arff"));
Instances data = new Instances(reader);
data.setClassIndex(data.numAttributes() - 1);
// generate data for clusterer (w/o class)
Remove filter = new Remove();
filter.setAttributeIndices("" + (data.classIndex() + 1));
filter.setInputFormat(data);
Instances dataClusterer = Filter.useFilter(data, filter);
// train clusterer
EM clusterer = new EM();
// set further options for EM, if necessary...
String[] options = new String[4];
// max. iterations
options[0] = "-I";
options[1] = "100";
//set cluseter numbers
options[2]="-N";
options[3]="3";
clusterer.setOptions(options);
clusterer.buildClusterer(dataClusterer);
// evaluate clusterer
ClusterEvaluation eval = new ClusterEvaluation();
eval.setClusterer(clusterer);
eval.evaluateClusterer(data);
// print results
System.out.println(eval.clusterResultsToString());
}
}由于weka使用的文件大多是arff格式的,这里我的程序从桌面上读入一个arff格式的文件,对其中数据进行聚类,在控制台下输出聚类的情况分析。
当然,我们也可以实现稍复杂的功能,例如把结果输出到文件,同时为了美观,把程序按模块进行分解。
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
import weka.clusterers.ClusterEvaluation;
import weka.clusterers.EM;
import weka.core.Instances;
import weka.core.converters.ConverterUtils.DataSource;
import weka.filters.Filter;
import weka.filters.unsupervised.attribute.Remove;
public class UserBehaviourCluster {
private Instances instances;
private String sourceFile;
private String targetFile;
private int maxCluster;
private int[] assignment;
public UserBehaviourCluster(String sourceFile, String targetFile, int maxCluster) {
this.sourceFile = sourceFile;
this.targetFile = targetFile;
this.maxCluster = maxCluster;
}
public void loadData() throws Exception {
DataSource dataSource = new DataSource(sourceFile);
instances = dataSource.getDataSet();
}
public void cluster() throws Exception {
//set attribute 1 weight to 0
instances.attribute(0).setWeight(0);
EM clusterer = new EM();
// set further options for EM, if necessary...
String[] options = new String[4];
// max. iterations
options[0] = "-I";
options[1] = "100";
//set cluseter numbers
options[2]="-N";
options[3]= Integer.toString(maxCluster);
clusterer.setOptions(options);
clusterer.buildClusterer(instances);
// evaluate clusterer
ClusterEvaluation eval = new ClusterEvaluation();
eval.setClusterer(clusterer);
eval.evaluateClusterer(instances);
// print results
//System.out.println(eval.clusterResultsToString());
assignment = new int[instances.numInstances()];
for (int j = 0; j<instances.numInstances() ; j++){
assignment[j]=clusterer.clusterInstance(instances.get(j) );
System.out.println(assignment[j]);
}
}
public void writeResult() throws Exception {
FileReader fr = null;
BufferedReader br = null;
FileWriter fw = null;
BufferedWriter bw = null;
String line=null;
int j=0;
try {
fr = new FileReader(sourceFile);
br = new BufferedReader(fr);
fw = new FileWriter(targetFile);
bw = new BufferedWriter(fw);
line=br.readLine();
bw.write(line+",cluster\n");
while((line=br.readLine())!=null){
bw.write(line+","+assignment[j++]+"\n");
}
} finally {
if (br != null) {
br.close();
}
if (bw != null) {
bw.close();
}
}
}
public void process() throws Exception{
loadData();
cluster();
writeResult();
}
public static void main(String[] args) throws Exception{
UserBehaviourCluster cluster=new UserBehaviourCluster("C:/Users/felven/Desktop/test3.csv", "C:/Users/felven/Desktop/test4.csv", 2);
cluster.process();
}
}
上面userBehaviourCluster中第三个参数指定的是最终聚类的个数,这里要求数据聚为3类。
其中读入的文件格式如下:
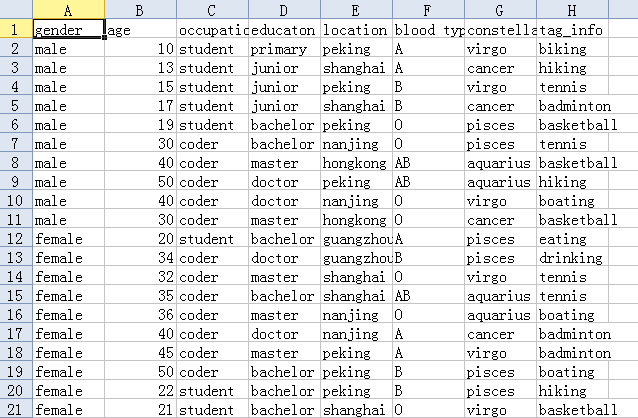
输出文件格式如下:
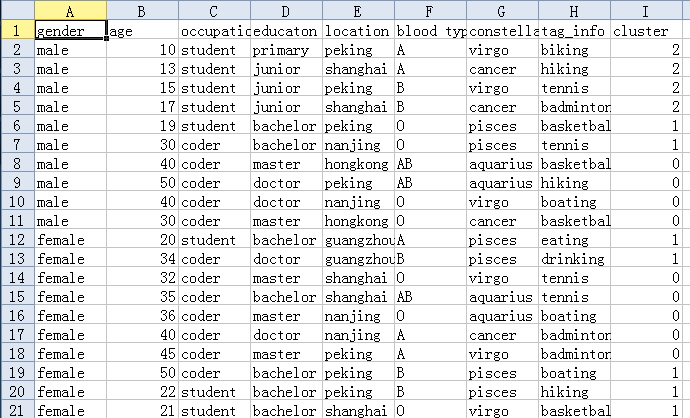
感觉还不错吧,更多的内容可以看这里: http://weka.wikispaces.com/Use+Weka+in+your+Java+code
最后要感谢老大在java方面提供帮助,我java实在太菜了。














 1200
1200











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









