







举个用户3对物品102是否感兴趣的例子:
用户3对所有物品的评分, 有评分说明用户3喜欢这东西
同现矩阵其实就是 物品与物品之间的关联度, 这个关联度由所有用户对所有物品的评分决定
比如第一条, 说明同时有3个用户喜欢 101 与 102
计算推荐得分, 其意义是: 比如第5行, 用户3很喜欢物品105(给了得了4.5), 同时由其他用户也知道喜欢物品105的对物品102的喜欢程度(得分2), 两者相乘表示用户3因为 喜欢物品105 推算出 同时也喜欢物品102的得分。
用户3对物品102 兴趣总得分
用户3对所有物品的评分, 有评分说明用户3喜欢这东西
同现矩阵其实就是 物品与物品之间的关联度, 这个关联度由所有用户对所有物品的评分决定
比如第一条, 说明同时有3个用户喜欢 101 与 102
计算推荐得分, 其意义是: 比如第5行, 用户3很喜欢物品105(给了得了4.5), 同时由其他用户也知道喜欢物品105的对物品102的喜欢程度(得分2), 两者相乘表示用户3因为 喜欢物品105 推算出 同时也喜欢物品102的得分。
用户3对物品102 兴趣总得分
| 本帖最后由 pig2 于 2014-6-17 19:43 编辑
问题导读:
1. 推荐系统概述;
2. 推荐系统指标设计;
3. Hadoop并行算法;
4. 推荐系统架构;
5. MapReduce程序实现。
前言
Netflix电影推荐的百万美金比赛,把“推荐”变成了时下最热门的数据挖掘算法之一。也正是由于Netflix的比赛,让企业界和学科界有了更深层次的技术碰撞。引发了各种网站“推荐”热,个性时代已经到来。
一、 推荐系统概述
电子商务网站是个性化推荐系统重要地应用的领域之一,亚马逊就是个性化推荐系统的积极应用者和推广者,亚马逊的推荐系统深入到网站的各类商品,为亚马逊带来了至少30%的销售额。
不光是电商类,推荐系统无处不在。QQ,人人网的好友推荐;新浪微博的你可能感觉兴趣的人;优酷,土豆的电影推荐;豆瓣的图书推荐;大从点评的餐饮推荐;世纪佳缘的相亲推荐;天际网的职业推荐等。
推荐算法分类:
按数据使用划分:
协同过滤算法:UserCF, ItemCF, ModelCF
基于内容的推荐: 用户内容属性和物品内容属性
社会化过滤:基于用户的社会网络关系
按模型划分:
最近邻模型:基于距离的协同过滤算法
Latent Factor Mode(SVD):基于矩阵分解的模型
Graph:图模型,社会网络图模型
基于用户的协同过滤算法UserCF
基于用户的协同过滤,通过不同用户对物品的评分来评测用户之间的相似性,基于用户之间的相似性做出推荐。简单来讲就是:给用户推荐和他兴趣相似的其他用户喜欢的物品。
用例说明:

算法实现及使用介绍,请参考文章:Mahout推荐算法API详解
基于物品的协同过滤算法ItemCF
基于item的协同过滤,通过用户对不同item的评分来评测item之间的相似性,基于item之间的相似性做出推荐。简单来讲就是:给用户推荐和他之前喜欢的物品相似的物品。
用例说明:
算法实现及使用介绍,请参考文章:Mahout推荐算法API详解
注:基于物品的协同过滤算法,是目前商用最广泛的推荐算法。
协同过滤算法实现,分为2个步骤
有关协同过滤的另一篇文章,请参考:RHadoop实践系列之三 R实现MapReduce的协同过滤算法
二、 需求分析:推荐系统指标设计
下面我们将从一个公司案例出发来全面的解释,如何进行推荐系统指标设计。
案例介绍
Netflix电影推荐百万奖金比赛,http://www.netflixprize.com/ Netflix官方网站:www.netflix.com
Netflix,2006年组织比赛是的时候,是一家以在线电影租赁为生的公司。他们根据网友对电影的打分来判断用户有可能喜欢什么电影,并结合会员看过的电影以及口味偏好设置做出判断,混搭出各种电影风格的需求。
收集会员的一些信息,为他们指定个性化的电影推荐后,有许多冷门电影竟然进入了候租榜单。从公司的电影资源成本方面考量,热门电影的成本一般较高,如果Netflix公司能够在电影租赁中增加冷门电影的比例,自然能够提升自身盈利能力。
Netflix公司曾宣称60%左右的会员根据推荐名单定制租赁顺序,如果推荐系统不能准确地猜测会员喜欢的电影类型,容易造成多次租借冷门电影而并不符合个人口味的会员流失。为了更高效地为会员推荐电影,Netflix一直致力于不断改进和完善个性化推荐服务,在2006年推出百万美元大奖,无论是谁能最好地优化Netflix推荐算法就可获奖励100万美元。到2009年,奖金被一个7人开发小组夺得,Netflix随后又立即推出第二个百万美金悬赏。这充分说明一套好的推荐算法系统是多么重要,同时又是多么困难。

上图为比赛的各支队伍的排名!
补充说明:
1. Netflix的比赛是基于静态数据的,就是给定“训练级”,匹配“结果集”,“结果集”也是提前就做好的,所以这与我们每天运营的系统,其实是不一样的。
2. Netflix用于比赛的数据集是小量的,整个全集才666MB,而实际的推荐系统都要基于大量历史数据的,动不动就会上GB,TB等
Netflix数据下载
部分训练集:http://graphlab.org/wp-content/uploads/2013/07/smallnetflix_mm.train_.gz 部分结果集:http://graphlab.org/wp-content/uploads/2013/07/smallnetflix_mm.validate.gz 完整数据集:http://www.lifecrunch.biz/wp-content/uploads/2011/04/nf_prize_dataset.tar.gz
所以,我们在真实的环境中设计推荐的时候,要全面考量数据量,算法性能,结果准确度等的指标。
推荐算法选型:基于物品的协同过滤算法ItemCF,并行实现
数据量:基于Hadoop架构,支持GB,TB,PB级数据量
算法检验:可以通过 准确率,召回率,覆盖率,流行度 等指标评判。
结果解读:通过ItemCF的定义,合理给出结果解释
这里我使用”Mahout In Action”书里,第一章第六节介绍的分步式基于物品的协同过滤算法进行实现。Chapter 6: Distributing recommendation computations
测试数据集:small.csv
每行3个字段,依次是用户ID,电影ID,用户对电影的评分(0-5分,每0.5为一个评分点!)
算法的思想:
1. 建立物品的同现矩阵
2. 建立用户对物品的评分矩阵
3. 矩阵计算推荐结果
1). 建立物品的同现矩阵
按用户分组,找到每个用户所选的物品,单独出现计数及两两一组计数。
2). 建立用户对物品的评分矩阵
按用户分组,找到每个用户所选的物品及评分
3). 矩阵计算推荐结果
同现矩阵*评分矩阵=推荐结果

图片摘自”Mahout In Action”
MapReduce任务设计

图片摘自”Mahout In Action”
解读MapRduce任务:
步骤1: 按用户分组,计算所有物品出现的组合列表,得到用户对物品的评分矩阵
步骤2: 对物品组合列表进行计数,建立物品的同现矩阵
步骤3: 合并同现矩阵和评分矩阵
步骤4: 计算推荐结果列表
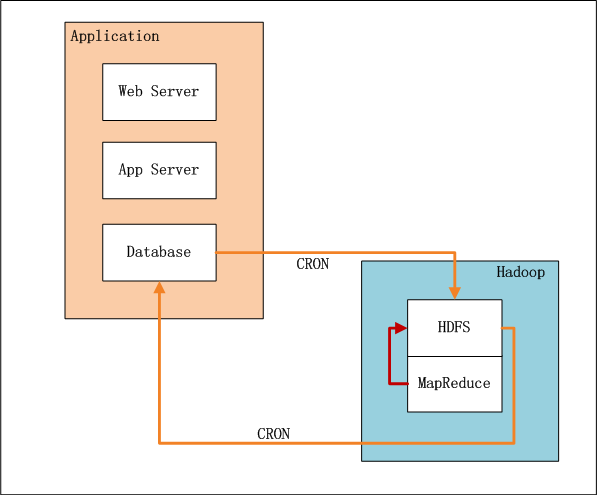
上图中,左边是Application业务系统,右边是Hadoop的HDFS, MapReduce。
五、 程序开发:MapReduce程序实现
win7的开发环境 和 Hadoop的运行环境 ,请参考文章:用Maven构建Hadoop项目
新建Java类:
Recommend.java,主任务启动程序
Step1.java,按用户分组,计算所有物品出现的组合列表,得到用户对物品的评分矩阵
Step2.java,对物品组合列表进行计数,建立物品的同现矩阵
Step3.java,合并同现矩阵和评分矩阵
Step4.java,计算推荐结果列表
HdfsDAO.java,HDFS操作工具类
1). Recommend.java,主任务启动程序
源代码:
计算结果:
3). Step2.java,对物品组合列表进行计数,建立物品的同现矩阵
源代码:
计算结果:
4). Step3.java,合并同现矩阵和评分矩阵
源代码:
计算结果:
5). Step4.java,计算推荐结果列表
源代码:
计算结果:
对Step4过程优化,请参考本文最后的补充内容。
6). HdfsDAO.java,HDFS操作工具类
详细解释,请参考文章:Hadoop编程调用HDFS
源代码:
这样我们就自己编程实现了MapReduce化基于物品的协同过滤算法。
RHadoop的实现方案,请参考文章:RHadoop实践系列之三 R实现MapReduce的协同过滤算法
Mahout的实现方案,请参考文章:Mahout分步式程序开发 基于物品的协同过滤ItemCF
我已经把整个MapReduce的实现都放到了github上面:
https://github.com/bsspirit/maven_hadoop_template/releases/tag/recommend |
http://f.dataguru.cn/thread-229459-1-1.html


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









