









Spark应用程序的提交离不开Spark Driver,后者是驱动应用程序在Spark集群上执行的原动力。了解Spark Driver的初始化,有助于理解Spark应用程序与Spark Driver的关系。
而Spark Driver的初始化始终围绕着SparkContext的初始化。SparkContext可以算得上是Spark应用程序的发动机引擎,轿车要想跑起来,发动机首先要启动。SparkContext初始化完毕,才能向Spark集群提交应用程序。发动机只需以较低的转速,就可以在平坦的公路上游刃有余;在山区,你可能需要一台能够提供大功率的发动机,这样才能满足你转山的体验。发动机的参数都是通过驾驶员操作油门、档位等传送给发动机的,而SparkContext的配置参数则由SparkConf负责,SparkConf(在《spark2.1.0之配置与源码分析》一文详细介绍)就是你的操作面板。
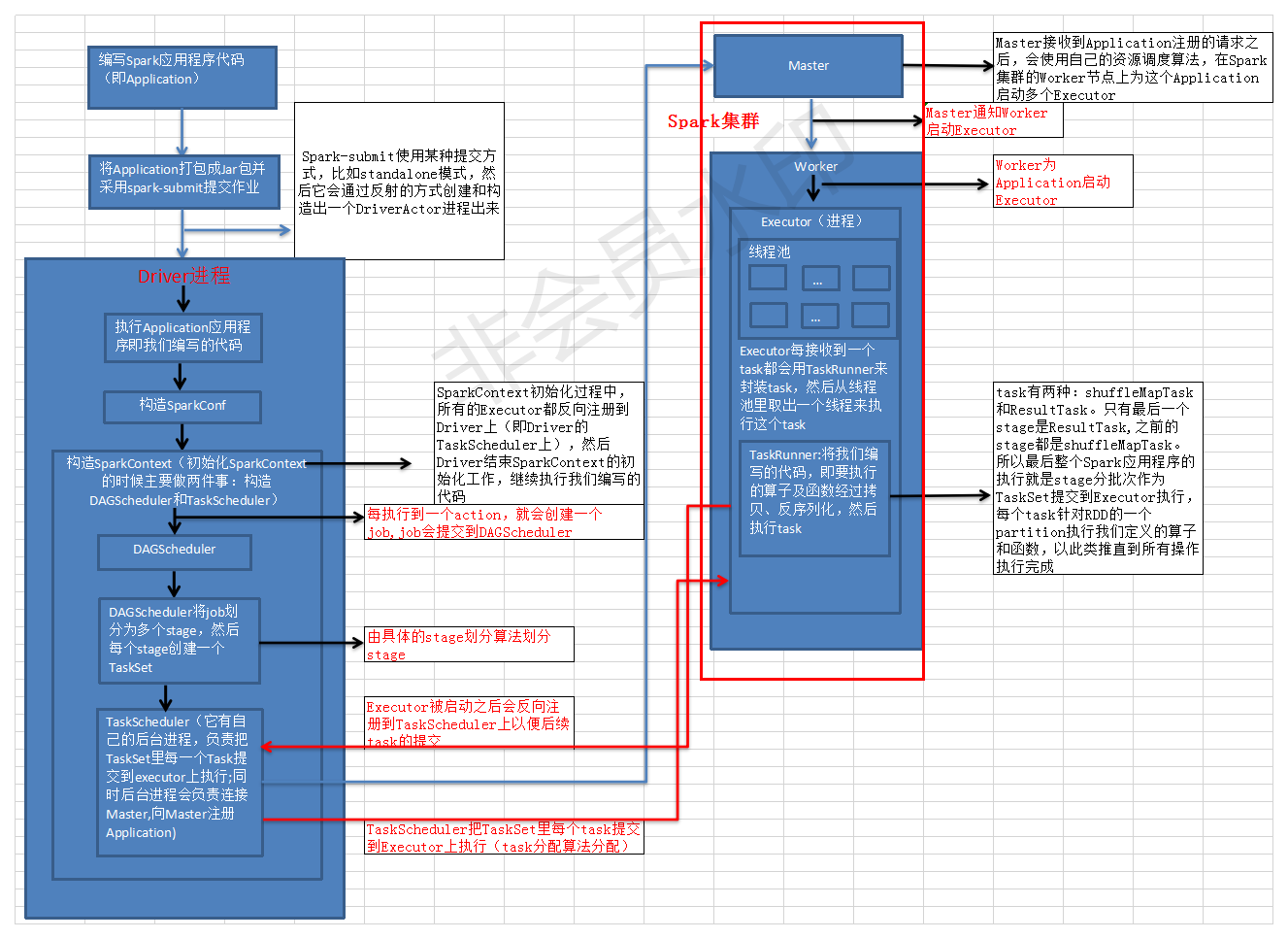
Spark架构原理图如图1所示
在讲解SparkContext的初始化过程之前,我们先来认识下SparkContext中的各个组成部分,如图2所示:
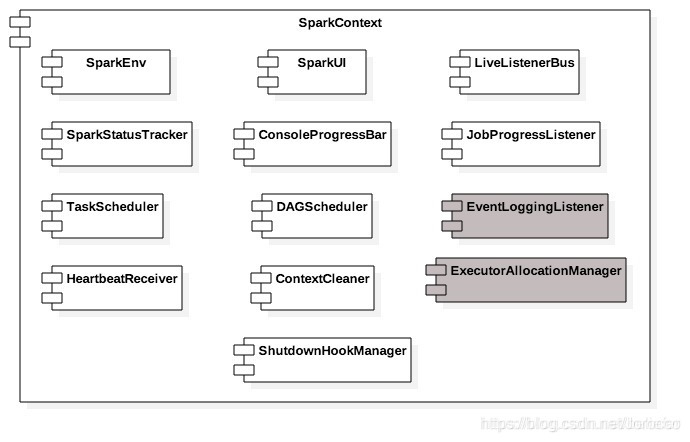
从图2可以知道SparkContext主要由以下部分组成。
-
SparkEnv:Spark运行时环境。Executor是处理任务的执行器,它依赖于SparkEnv提供的运行时环境。此外在Driver中也包含了SparkEnv,这是为了保证local模式下任务的执行。SparkEnv内部包含了很多组件,例如serializerManager、RpcEnv、BlockManager、mapOutputTracker等。
-
LiveListenerBus:SparkContext中的事件总线,可以接收各个使用方的事件,并且通过异步方式对事件进行匹配后调用SparkListener的不同方法。LiveListenerBus的具体内容已经在3.3节详细介绍,此处不再赘述。
-
SparkUI:Spark的用户界面。SparkUI间接依赖于计算引擎、调度系统、存储体系,作业(Job)、阶段(Stage)、存储、执行器(Executor)等组件的监控数据都会以SparkListenerEvent的形式投递到LiveListenerBus中,SparkUI将从各个SparkListener中读取数据并显示到Web界面。
-
SparkStatusTracker:提供对于作业、Stage(阶段)等的监控信息。SparkStatusTracker是一个低级的API,这意味着只能提供非常脆弱的一致性机制。
-
ConsoleProgressBar:利用SparkStatusTracker的API,在控制台展示Stage的进度。由于SparkStatusTracker存在的一致性问题,所以ConsoleProgressBar在控制台的显示往往有一定时延。
-
DAGScheduler:DAG调度器,是调度系统中的重要组件之一。负责创建Job,将DAG中的RDD划分到不同的Stage、提交Stage等。SparkUI中有关Job和Stage的监控数据都来自DAGScheduler。
-
TaskScheduler:任务调度器,是调度系统中的重要组件之一。TaskScheduler按照调度算法对集群管理器已经分配给应用程序的资源进行二次调度后分配给任务。TaskScheduler调度的Task是由DAGScheduler创建的,所以DAGScheduler是TaskScheduler的前置调度。
-
HeartbeatReceiver:心跳接收器。所有执行Executor都会向HeartbeatReceiver发送心跳信息,HeartbeatReceiver接收到Executor的心跳信息后,首先更新Executor的最后可见时间,然后将此信息交给TaskScheduler作进一步处理。
-
ContextCleaner:上下文清理器。ContextCleaner实际用异步方式清理那些超出应用作用域范围的RDD、ShuffleDependency和Broadcast等信息。
-
JobProgressListener:作业进度监听器。JobProgressListener在3.3.3节介绍SparkListener的继承体系时提到过,根据之前的介绍我们知道JobProgressListener将注册到LiveListenerBus中作为事件监听器之一使用。
-
EventLoggingListener:将事件持久化到存储的监听器,是SparkContext中的可选组件。当spark.eventLog.enabled属性为true时启用。
-
ExecutorAllocationManager:Executor(执行器)动态分配管理器。顾名思义,可以根据工作负载动态调整Executor的数量。在配置spark.dynamicAllocation.enabled属性为true的前提下,在非local模式下或者当spark.dynamicAllocation.testing属性为true时启用。
除了以上介绍的这些SparkContext内部组件,SparkContext内部还包括以下属性:
- creationSite:类型为CallSite,其中保存着线程栈中最靠近栈顶的用户定义的类及最靠近栈底的Scala或者Spark核心类信息,CallSite的shortForm属性保存着以上信息的简短描述,CallSite的longForm属性则保存着以上信息的完整描述。Spark自带的examples项目中有对单词进行计数的应用例子JavaWordCount,运行JavaWordCount得到的CallSite对象的属性值分别为:
shortForm:“getOrCreate at JavaWordCount.java:48”;
longForm:“org.apache.spark.sql.SparkSession$Builder.getOrCreate(SparkSession.scala:860)
org.apache.spark.examples.JavaWordCount.main(JavaWordCount.java:48)”。
- allowMultipleContexts:是否允许多个SparkContext实例。默认为false,可以通过属性spark.driver.allowMultipleContexts来控制。
- startTime:SparkContext启动的时间戳。
- stopped:标记SparkContext是否已经停止的状态,采用原子类型AtomicBoolean。
- addedFiles:用于每个本地文件的URL与添加此文件到addedFiles时的时间戳之间的映射缓存。
- addedJars:用于每个本地Jar文件的URL与添加此文件到addedJars时的时间戳之间的映射缓存。
- persistentRdds:用于对所有持久化的RDD保持跟踪。
- executorEnvs:用于存储环境变量。executorEnvs中环境变量都将传递给执行任务的Executor使用。
- sparkUser:当前系统的登录用户,也可以通过系统环境变量SPARK_USER进行设置。这里使用的Utils的getCurrentUserName方法。
- checkpointDir:RDD计算过程中保存检查点时所需要的目录。
- localProperties:由InheritableThreadLocal保护的线程本地变量,其中的属性值可以沿着线程栈传递下去,供用户使用。
- _conf:SparkContext的配置,通过调用SparkConf的clone方法的克隆体。在SparkContext初始化的过程中会对conf中的配置信息做校验,例如:用户必须给自己的应用程序设置spark.master(采用的部署模式)和spark.app.name(用户应用的名称);用户设置的spark.master属性为yarn时,spark.submit.deployMode属性必须为cluster且必须设置spark.yarn.app.id属性。
- _jars:用户设置的Jar文件。当用户选择的部署模式是yarn时,_jars是由spark.jars属性指定的jar文件和spark.yarn.dist.jars属性指定的jar文件的并集。其它模式下只采用由spark.jars属性指定的jar文件。这里使用了Utils的getUserJars方法。
- _files:用户设置的文件。可以使用spark.files属性进行指定。
- _eventLogDir:事件日志的路径。当spark.eventLog.enabled属性为true时启用。默认为/tmp/spark-events,也可以通过spark.eventLog.dir属性指定。
- _eventLogCodec:事件日志的压缩算法。当spark.eventLog.enabled属性与spark.eventLog.compress属性皆为true时启用。压缩算法默认为lz4,也可以通过spark.io.compression.codec属性指定。Spark目前支持的压缩算法包括:lzf、snappy和lz4三种。
- _hadoopConfiguration:Hadoop的配置信息,具体根据Hadoop(Hadoop2.0之前的版本)和Hadoop Yarn(Hadoop2.0+的版本)的环境有所区别。如果系统属性SPARK_YARN_MODE为true或者环境变量SPARK_YARN_MODE为true,那么将会是Yarn的配置,否则为Hadoop配置。
- _executorMemory:Executor的内存大小。默认值为1024MB。可以通过设置环境变量(SPARK_MEM或者SPARK_EXECUTOR_MEMORY)或者spark.executor.memory属性指定。其中spark.executor.memory的优先级最高,SPARK_EXECUTOR_MEMORY次之,SPARK_MEM是老版本Spark遗留下来的配置方式,未来将会废弃。
- _applicationId:当前应用的标识。TaskScheduler启动后会创建应用标识,SparkContext中的_applicationId就是通过调用TaskScheduler的applicationId方法获得的。
- _applicationAttemptId:当前应用尝试执行的标识。Spark Driver在执行时会多次尝试执行,每次尝试都将生成一个标识来代表应用尝试执行的身份。
- _listenerBusStarted:LiveListenerBus是否已经启动的标记。
- nextShuffleId:类型为AtomicInteger,用于生成下一个Shuffle的身份标识。
- nextRddId:类型为AtomicInteger,用于生成下一个RDD的身份标识。














 1627
1627











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









