







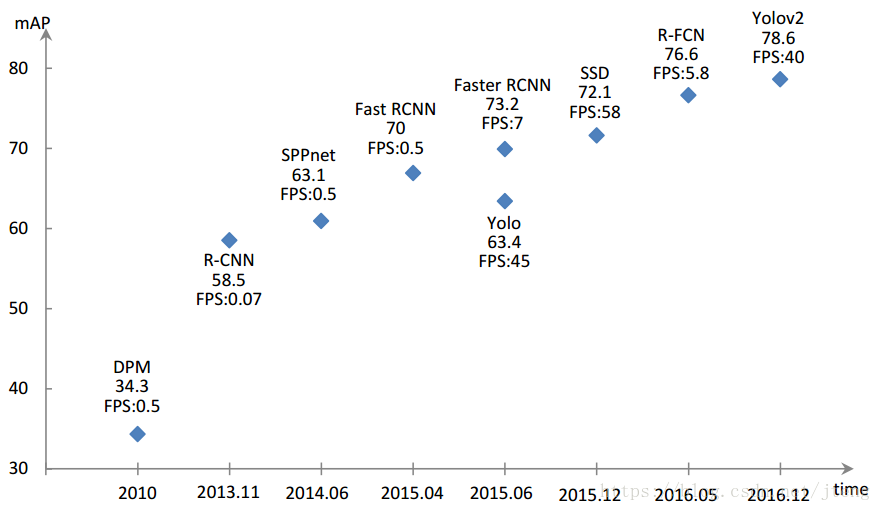
首先放图,下图总结了近年来各目标检测方法的速度和精度对比,横轴为时间,纵轴为精度,每个点处的FPS表示速度,即每秒处理图片的个数,详见另一篇文章目标检测之R-CNN。
Fast R-CNN是对SPPnet的进一步改进,主要贡献有以下三点:
1. 使用multi-task loss将目标分类和bounding box regression统一到一个模型中,实现了single-stage的end-to-end训练。
2. 不需要存储中间特征,降低了对硬盘空间的需求。
3. 在训练时采用层级采样策略,有效利用参数共享,进一步提升训练速度和精度。
1. Single-stage训练结构
Fast R-CNN的结构如下,候选区域提取部分仍然采用Selective Search,在这里候选区域换了一个名字,叫做RoI(Region of Interest),其feature map计算部分采用了SPPnet的方法,即整张图片只计算一次卷积特征提取,然后将每个RoI区域映射到feature map上,得到其对应的特征,从RoI到feature map的投影方法参见上一篇文章目标检测之SPPnet。
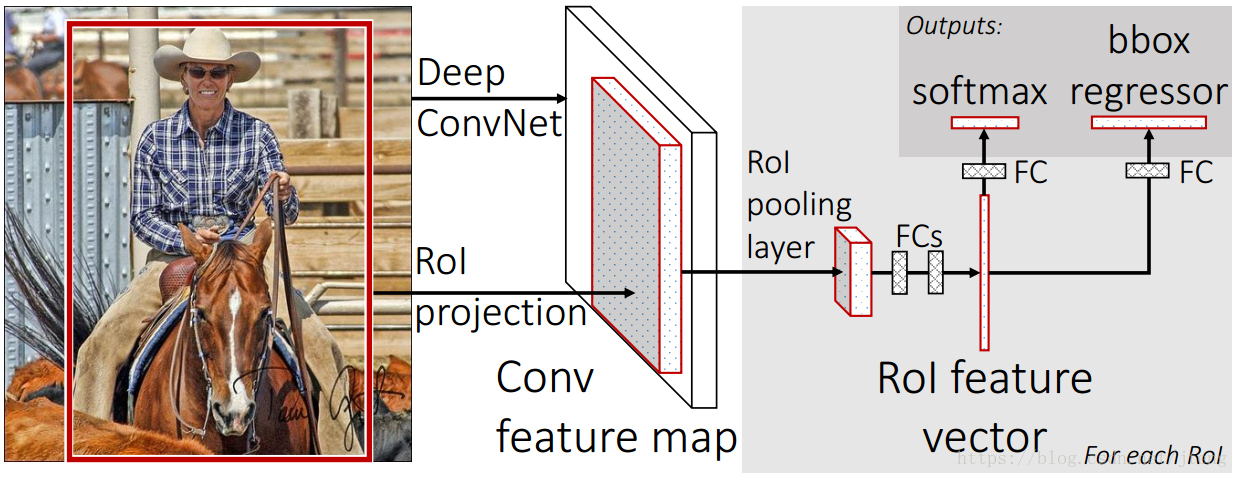
Fast R-CNN的改进之处在上图中灰色区域,首先其RoI pooling layer采用了简化的SPP layer,只从一个scale将RoI的特征进行分割,论文中使用7*7,然后进行max pooling。其次就是Fast R-CNN采用了multi task的方式联合训练目标分类和bounding box回归,其输出有两个分支,一个是softmax分类,对每个RoI,计算其在K+1个类别(一个为background)上的概率 p=(p0,⋯,pK) p = ( p 0 , ⋯ , p K ) ,另一个是bounding box回归,对每个RoI,计算其在K个类别上的位置 tk=(tkx,tky,tkw,tkh) t k = ( t x k , t y k , t w k , t h k ) ,然后进行回归。Fast R-CNN的损失函数为:
L(p,u,tu,v)=Lcls(p,u)+λ[u≥1]Lloc(tu,v) L ( p , u , t u , v ) = L c l s ( p , u ) + λ [ u ≥ 1 ] L l o c ( t u , v )
其中, u u 是RoI所属类别,如果RoI属于类则 u=k u = k ,如果为背景,则 u=0 u = 0 , v v 是RoI的ground-truth bounding box , [u≥1] [ u ≥ 1 ] 取1当 u≥1 u ≥ 1 ,否则取0,表示当RoI属于类别 k k 时,则对其预测的位置进行回归,如果是背景,则忽略其位置。分类损失函数 Lcls(p,u)=−logpu L c l s ( p , u ) = − log p u 为负对数似然函数,使真实类别u的概率最大。bounding box回归损失函数为:
Lloc(tu,v)=∑i∈{x,y,w,h}smoothL1(tui−vi)
L
l
o
c
(
t
u
,
v
)
=
∑
i
∈
{
x
,
y
,
w
,
h
}
smooth
L
1
(
t
i
u
−
v
i
)
其中,
smoothL1(x)={0.5x2|x|−0.5if|x|<1otherwise
smooth
L
1
(
x
)
=
{
0.5
x
2
i
f
|
x
|
<
1
|
x
|
−
0.5
o
t
h
e
r
w
i
s
e
smoothL1(⋅)
smooth
L
1
(
⋅
)
函数对outlier不敏感,因为bounding box的位置被归一化到[0,1]范围内,所以
|tu−v|
|
t
u
−
v
|
应该小于1,对于outlier使用
L1
L
1
损失函数,可降低其对误差的影响。
2. 不需要存储中间特征,降低硬盘空间需求。
R-CNN和SPPnet是multi-stage的训练方式,需要将CNN提取的特征保存在硬盘中,然后再进行SVM分类和bounding box regression,由于一张图片有大量的region proposals(约2000个),所以特征占用几百G的硬盘空间,磁盘的读写也减慢了训练速度。Fast R-CNN实现了end-to-end的训练方式,不要保存中间特征,既节省了硬盘空间,又提升了训练速度。
3. 层级采样策略,有效利用参数共享。
来自同一个图片的RoI之间多有重叠,所以在每个batch训练时,如果RoI来自同一个图片,只对一个图片计算feature map,就可以得到多个RoI的feature,否则,如果每个RoI均来自不同的图片,就需要对每个图片均计算feature map,从而加大计算量。同时,为了保证每个batch的多样性,Fast R-CNN在生成一个batch时,首先随机选择N个图片,然后对每个图片,选择R/N个RoI(R为训练的batch size),这样可保证多个RoI来自同一个图片,论文中设置N=2,R=128。
在生成一个batch时,图片是随机选择的,RoI不是随机选择,因为要保证每个batch中正例(RoI包含object)和负例(RoI为background)的比例合理,防止样本不均衡。论文中选择25%的RoI为正例,正例选择的标准为该RoI与所有ground-truth box的IoU的最大值大于等于0.5,负例选择的标准为该RoI与所有ground-truth box的IoU的最大值在[0.1,0.5)范围内。
Fast R-CNN是基于区域的目标检测方法的第二次改进,使用multi-task loss实现了end-to-end训练,并采取了一些数据采样的技巧,进一步提升速度和精度。但是,候选区域仍然使用其他方法(如Selective Search, Edge Boxes)生成,所以,Fast R-CNN仍然是一个two-stage的方法,而且Selective Search等方法多运行在CPU上,速度较慢,所以才有了Faster R-CNN将候选区域步骤纳入到网络模型中,实现真正的single-stage目标检测。














 1457
1457











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









