







今天使用到了volatile关键字,之前了解到这个关键字,但是不知道他的具体作用是什么,下面就来详细解释一下他的作用:
在java线程并发处理中,有一个关键字volatile的使用目前存在很大的混淆,以为使用这个关键字,在进行多线程并发处理的时候就可以万事大吉。
Java语言是支持多线程的,为了解决线程并发的问题,在语言内部引入了 同步块(synchronized) 和 volatile 关键字机制。
synchronized
同步块大家都比较熟悉,通过 synchronized 关键字来实现,所有加上synchronized 和 块语句,在多线程访问的时候,同一时刻只能有一个线程能够用synchronized 修饰的方法 或者 代码块。
volatile
用volatile修饰的变量,线程在每次使用变量的时候,都会读取变量修改后的最新的值。volatile很容易被误用,用来进行原子性操作。
下面看一个例子,我们实现一个计数器,每次线程启动的时候,会调用计数器inc方法,对计数器进行加一
- package com.volatiles.demo;
-
- public class VolatileTest {
-
- private int data = 0;
-
- public static void main(String[] args) throws Exception{
-
- final VolatileTest obj = new VolatileTest();
- //创建1000个线程对变量data进行加1操作
- for(int i=0;i<1000;i++){
- new Thread(){
- @Override
- public void run(){
- try{
- Thread.sleep(1);
- obj.data++;
- }catch(Exception e){
- e.printStackTrace();
- }
- }
- }.start();
- }
- //打印结果
- System.out.println("data:"+obj.data);
-
- }
-
- }
运行结果:data:995
实际运算结果每次可能都不一样,本机的结果为:运行结果:data:995,可以看出,在多线程的环境下,data并没有期望结果是1000
很多人以为,这个是多线程并发问题,只需要在变量data之前加上volatile就可以避免这个问题,那我们在修改代码看看,看看结果是不是符合我们的期望 :
运行结果:data:992
运行结果还是没有我们期望的1000,下面我们分析一下原因
我们都知道jvm运行时刻内存的分配。其中有一个内存区域是jvm虚拟机栈,每一个线程运行时都有一个线程栈,线程栈保存了线程运行时候变量值信息。当线程访问某一个对象时候值的时候,首先通过对象的引用找到对应在堆内存的变量的值,然后把堆内存变量的具体值load到线程本地内存中,建立一个变量副本,之后线程就不再和对象在堆内存变量值有任何关系,而是直接修改副本变量的值,在修改完之后的某一个时刻(线程退出之前),自动把线程变量副本的值回写到对象在堆中变量。这样在堆中的对象的值就产生变化了。下面一幅图
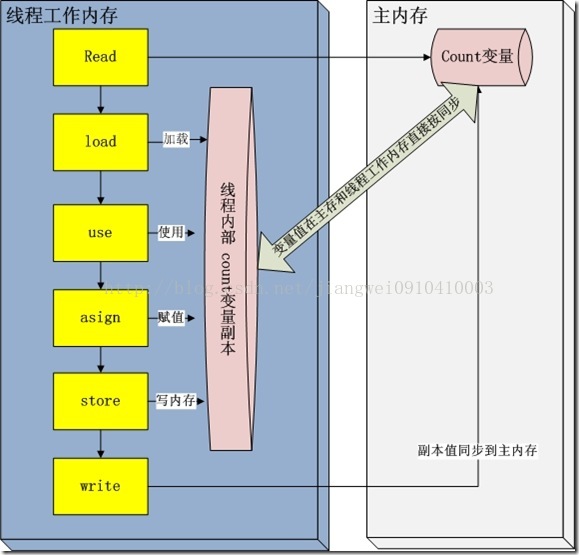
描述这一过程:
read and load 从主存复制变量到当前工作内存
use and assign 执行代码,改变共享变量值
store and write 用工作内存数据刷新主存相关内容
其中use and assign 可以多次出现
但是这一些操作并不是原子性,也就是 在read load之后,如果主内存data变量发生修改之后,线程工作内存中的值由于已经加载,不会产生对应的变化,所以计算出来的结果会和预期不一样。
对于volatile修饰的变量,jvm虚拟机只是保证从主内存加载到线程工作内存的值是最新的
例如假如线程1,线程2 在进行read,load 操作中,发现主内存中data的值都是5,那么都会加载这个最新的值
在线程1对data进行修改之后,会write到主内存中,主内存中的data变量就会变为6
线程2由于已经进行read,load操作,在进行运算之后,也会更新主内存data的变量值为6
导致两个线程及时用volatile关键字修改之后,还是会存在并发的情况。
今天使用到了volatile关键字,之前了解到这个关键字,但是不知道他的具体作用是什么,下面就来详细解释一下他的作用:
在java线程并发处理中,有一个关键字volatile的使用目前存在很大的混淆,以为使用这个关键字,在进行多线程并发处理的时候就可以万事大吉。
Java语言是支持多线程的,为了解决线程并发的问题,在语言内部引入了 同步块(synchronized) 和 volatile 关键字机制。
synchronized
同步块大家都比较熟悉,通过 synchronized 关键字来实现,所有加上synchronized 和 块语句,在多线程访问的时候,同一时刻只能有一个线程能够用synchronized 修饰的方法 或者 代码块。
volatile
用volatile修饰的变量,线程在每次使用变量的时候,都会读取变量修改后的最新的值。volatile很容易被误用,用来进行原子性操作。
下面看一个例子,我们实现一个计数器,每次线程启动的时候,会调用计数器inc方法,对计数器进行加一
- package com.volatiles.demo;
- public class VolatileTest {
- private int data = 0;
- public static void main(String[] args) throws Exception{
- final VolatileTest obj = new VolatileTest();
- //创建1000个线程对变量data进行加1操作
- for(int i=0;i<1000;i++){
- new Thread(){
- @Override
- public void run(){
- try{
- Thread.sleep(1);
- obj.data++;
- }catch(Exception e){
- e.printStackTrace();
- }
- }
- }.start();
- }
- //打印结果
- System.out.println("data:"+obj.data);
- }
- }
实际运算结果每次可能都不一样,本机的结果为:运行结果:data:995,可以看出,在多线程的环境下,data并没有期望结果是1000
很多人以为,这个是多线程并发问题,只需要在变量data之前加上volatile就可以避免这个问题,那我们在修改代码看看,看看结果是不是符合我们的期望 :
运行结果:data:992
运行结果还是没有我们期望的1000,下面我们分析一下原因
我们都知道jvm运行时刻内存的分配。其中有一个内存区域是jvm虚拟机栈,每一个线程运行时都有一个线程栈,线程栈保存了线程运行时候变量值信息。当线程访问某一个对象时候值的时候,首先通过对象的引用找到对应在堆内存的变量的值,然后把堆内存变量的具体值load到线程本地内存中,建立一个变量副本,之后线程就不再和对象在堆内存变量值有任何关系,而是直接修改副本变量的值,在修改完之后的某一个时刻(线程退出之前),自动把线程变量副本的值回写到对象在堆中变量。这样在堆中的对象的值就产生变化了。下面一幅图
描述这一过程:
read and load 从主存复制变量到当前工作内存
use and assign 执行代码,改变共享变量值
store and write 用工作内存数据刷新主存相关内容
其中use and assign 可以多次出现
但是这一些操作并不是原子性,也就是 在read load之后,如果主内存data变量发生修改之后,线程工作内存中的值由于已经加载,不会产生对应的变化,所以计算出来的结果会和预期不一样。
对于volatile修饰的变量,jvm虚拟机只是保证从主内存加载到线程工作内存的值是最新的
例如假如线程1,线程2 在进行read,load 操作中,发现主内存中data的值都是5,那么都会加载这个最新的值
在线程1对data进行修改之后,会write到主内存中,主内存中的data变量就会变为6
线程2由于已经进行read,load操作,在进行运算之后,也会更新主内存data的变量值为6
导致两个线程及时用volatile关键字修改之后,还是会存在并发的情况。

- int i1;
- int geti1() {return i1;}
- volatile int i2;
- int geti2()
- {return i2;}
- int i3;
- synchronized int geti3() {return i3;}
- geti1()
得到存储在当前线程中i1的数值。多个线程有多个i1变量拷贝,而且这些i1之间可以互不相同。换句话说,另一个线程可能已经改变了它线程内的i1值,而这个值可以和当前线程中的i1值不相同。事实上,Java有个思想叫“主”内存区域,这里存放了变量目前的“准确值”。每个线程可以有它自己的变量拷贝,而这个变量拷贝值可以和“主”内存区域里存放的不同。因此实际上存在一种可能:“主”内存区域里的i1值是1,线程1里的i1值是2,线程2里的i1值是3——这在线程1和线程2都改变了它们各自的i1值,而且这个改变还没来得及传递给“主”内存区域或其他线程时就会发生。
而 geti2()得到的是“主”内存区域的i2数值。用volatile修饰后的变量不允许有不同于“主”内存区域的变量拷贝。换句话说,一个变量经 volatile修饰后在所有线程中必须是同步的;任何线程中改变了它的值,所有其他线程立即获取到了相同的值。理所当然的,volatile修饰的变量存取时比一般变量消耗的资源要多一点,因为线程有它自己的变量拷贝更为高效。
既然volatile关键字已经实现了线程间数据同步,又要 synchronized干什么呢?呵呵,它们之间有两点不同。首先,synchronized获得并释放监视器——如果两个线程使用了同一个对象锁,监视器能强制保证代码块同时只被一个线程所执行——这是众所周知的事实。但是,synchronized也同步内存:事实上,synchronized在“ 主”内存区域同步整个线程的内存。因此,执行geti3()方法做了如下几步:
1. 线程请求获得监视this对象的对象锁(假设未被锁,否则线程等待直到锁释放)
2. 线程内存的数据被消除,从“主”内存区域中读入(Java虚拟机能优化此步。。。[后面的不知道怎么表达,汗])
3. 代码块被执行
4. 对于变量的任何改变现在可以安全地写到“主”内存区域中(不过geti3()方法不会改变变量值)
5. 线程释放监视this对象的对象锁
因此volatile只是在线程内存和“主”内存间同步某个变量的值,而synchronized通过锁定和解锁某个监视器同步所有变量的值。显然synchronized要比volatile消耗更多资源。
一个变量声明为volatile,就意味着这个变量是随时会被其他线程修改的,因此不能将它cache在线程memory中。















 318
318

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









