







本博文讲述的内容主要包括:
1,SparkStreaming on Kafka Receiver 工作原理机制
2,SparkStreaming on Kafka Receiver案例实战
3,SparkStreaming on Kafka Receiver源码解析
一:SparkStreaming on Kafka Receiver 简介:
1、Spark-Streaming获取kafka数据的两种方式-Receiver与Direct的方式,可以从代码中简单理解成Receiver方式是通过zookeeper来连接kafka队列,Direct方式是直接连接到kafka的节点上获取数据了。
2、基于Receiver的方式:
这种方式使用Receiver来获取数据。Receiver是使用Kafka的高层次Consumer API来实现的。receiver从Kafka中获取的数据都是存储在Spark Executor的内存中的,然后Spark Streaming启动的job会去处理那些数据。
然而,在默认的配置下,这种方式可能会因为底层的失败而丢失数据。如果要启用高可靠机制,让数据零丢失,就必须启用Spark Streaming的预写日志机制(Write Ahead Log,WAL)。该机制会同步地将接收到的Kafka数据写入分布式文件系统(比如HDFS)上的预写日志中。所以,即使底层节点出现了失败,也可以使用预写日志中的数据进行恢复。
补充说明:
(1)、Kafka中的topic的partition,与Spark中的RDD的partition是没有关系的。所以,在KafkaUtils.createStream()中,提高partition的数量,只会增加一个Receiver中,读取partition的线程的数量。不会增加Spark处理数据的并行度。
(2)、可以创建多个Kafka输入DStream,使用不同的consumer group和topic,来通过多个receiver并行接收数据。
(3)、如果基于容错的文件系统,比如HDFS,启用了预写日志机制,接收到的数据都会被复制一份到预写日志中。因此,在KafkaUtils.createStream()中,设置的持久化级别是StorageLevel.MEMORY_AND_DISK_SER。
SparkStreaming on Kafka Receiver 工作原理图如下所示:
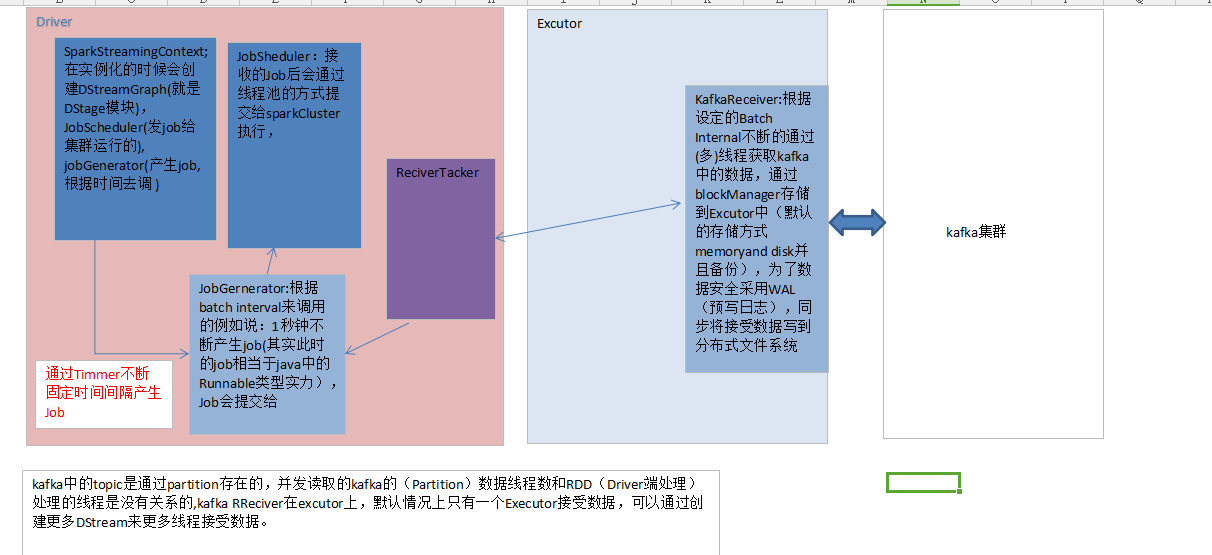
二、SparkStreaming on Kafka Receiver案例实战:
1、在进行SparkStreaming on Kafka Receiver案例的环境前提:
(1)spark 安装成功,spark 1.6.0(local方式除外)
(2)zookeeper 安装成功
(3)kafka 安装成功
(4)启动集群和zookeeper和kafka
在这里我采用local的方式进行试验,代码如下:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
2、SparkStreaming on Kafka Receiver运行在集群上的步骤及结果:
1,首先启动zookeeper服务:
2,接下来启动Kafka服务
3,在eclipse上观察结果:
三:SparkStreaming on Kafka Receiver源码解析
1,首先看一下KafkaUtils(包含zookeeper的配置等等):
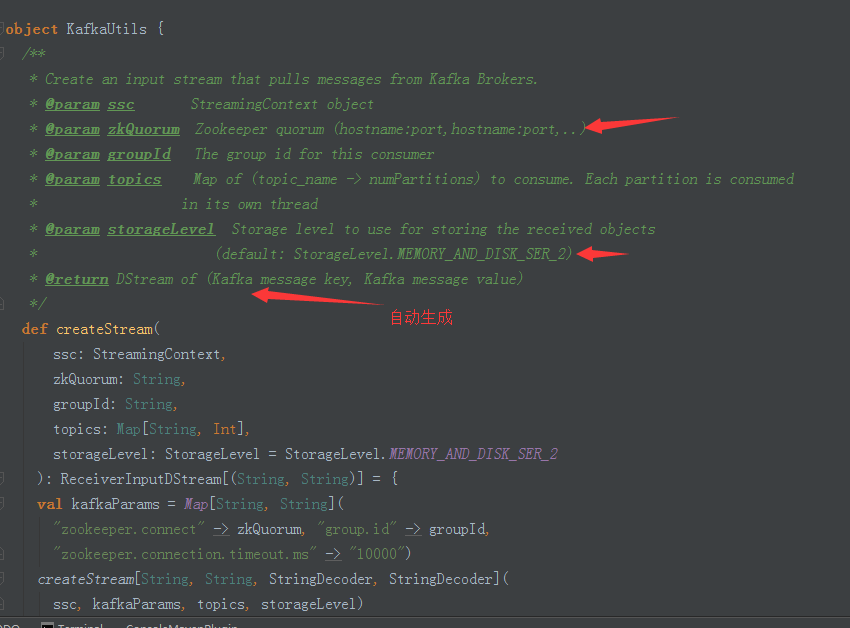
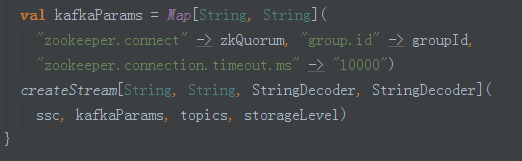
2、在这里创建了KafkaInputDStream:

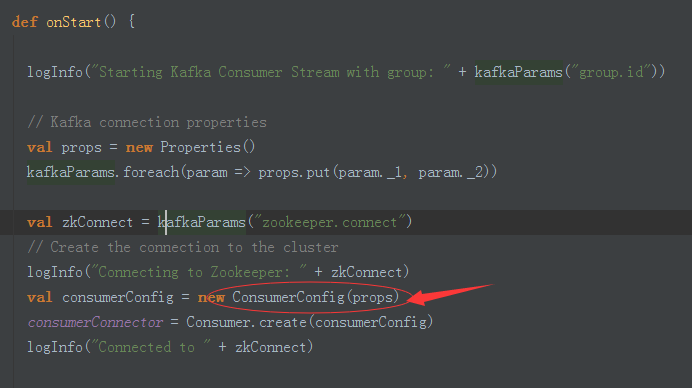
3、这里证明KafkaInputStream为consumer
4、在这里拥有线程池(处理topic)
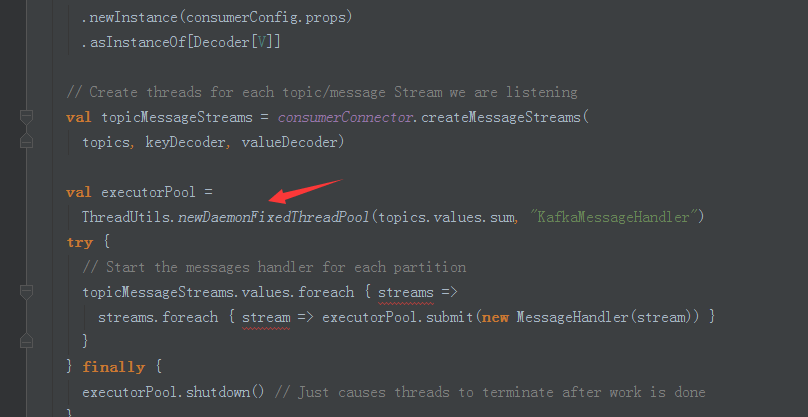
5,不同的接受方式(第一个为wal方式)
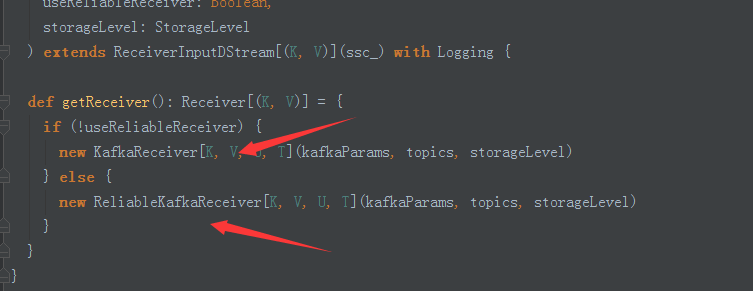
补充说明:
使用Spark Streaming可以处理各种数据来源类型,如:数据库、HDFS,服务器log日志、网络流,其强大超越了你想象不到的场景,只是很多时候大家不会用,其真正原因是对Spark、spark streaming本身不了解。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









