







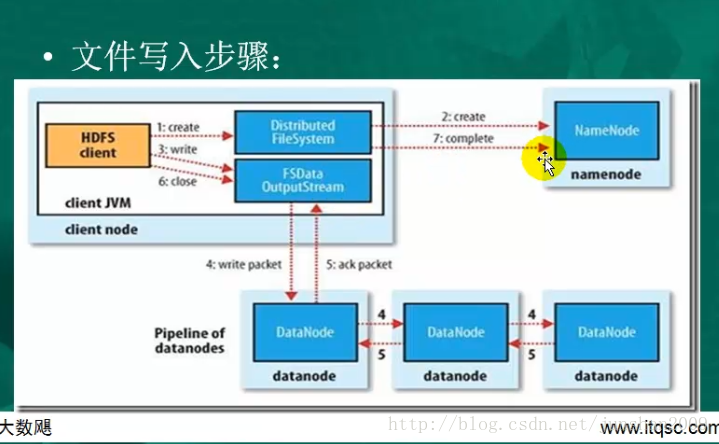
HDFS Hadoop Dietribute Filesystem
存储块 block --负责管理文件路径和逻辑关系的Namenode–负责具体的读写操作的Datanodes
MapReduce
Map-combiner-shuffler-reduce
YARN介绍
客户端和集群之间交流的任务管理系统
ZoopKeeper 用于故障转移,当资源管理器失败后,另一个可以马上恢复.
datanode–读取数据

- 每台Salve服务器都运行一个
- 负责把HDFS数据块读写到本地文件系统
- 负责物理节点的存储管理
- 一次写入,多次读取,不修改
- 文件由数据块组成,默认大小64M
Hadoop工作过程
MAP实现类
split,map,combiner,shuffle
REDUCE实现类
实现reduce,实现输出

常用操作命令
-Expunge清空 hdfs垃圾箱
-Get拷贝文件到本地
-GetMerge源文件和目标文件作为输入,将源文件中的所有文件合并成一个本地文件
-ls列出文件,类似于linux的ll
–LSr递归列出文件
–Mkdir创建目录
–moveFromLocal跟put类似,源文件在拷贝之后会被删除
–Mv移动
–put上环
–rm删除
HIVE介绍
进入hive的操作界面 hive
元数据存储
Hive将元数据存储在数据库中,如Mysql,或者Derby嵌入式数据库
如将元数据存储在Mysql中,在table中可以见到建立的所有表信息,Hive的元数据包括表的名字,表和列和分区及其属性,表的目录结构等,一般存储在Mysql中
HIve的常用进程和服务
MataStore
数据格式
数据更新
Hive是针对多读少写实现,所以不支持改写和添加,所有数据在加载时确定
和关系型数据库的比较



! cat hive里面打开文件















 2637
2637











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









