







高斯混合模型(GMM),是一种可以用来匹配测试数据集的常用模型。和K-means一样,经常用来做数据分类,其中应用的Expectation-Maximization(EM)算法更是可以看做k-means 的一般特例。
首先区别两个概念
1.单高斯分布模型(GSM)
这里我们不要把单高斯分布和单变量高斯分布混淆了,虽然他们只是维数不同,但是理解成单变量可能会对我们的多高斯分布的理解造成混乱。
这个是单变量高斯模型(也即正态分布):
这个是单高斯分布模型
N(x;u,Σ)=12π√|Σ|exp[−12(x−u)T]Σ−1(x−u)
比如我们有下面这样一组数据集[1,2],
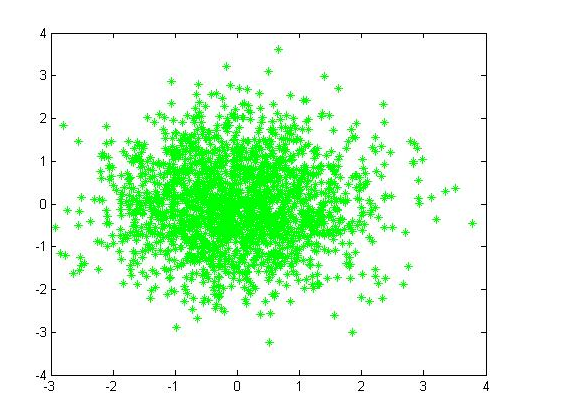
从图中我们可以看出,这个数据集我们可以用高斯模型进行匹配(二维),直观来看,效果应该是比较好的(当然你肯定可以用k-means等等)。
2.高斯混合模型
为什么要提出这个概念呢?先上个图片瞅瞅,从图中我们明显看出来,如果用单高斯模型去fit这些数据,肯定是不合理的。但是看着这个图我们可以得到一点启发,我们能不能用多高斯模型匹配呢?你看这幅图长得像不像很多个高斯模型(椭圆)混在一起的样子?这就是我们要研究这个模型的动机。

这里我们先上一个公式,现有一点认识,后面我们慢慢讲这个公式是怎么来的
GMM模型:
这里有个问题,为什么我们要假设数据是由若干个高斯分布组合而成的,而不假设是其他分布呢?实际上不管是什么分布,只K取得足够大,这个XX Mixture Model就会变得足够复杂,就可以用来逼近任意连续的概率密度分布。只是因为高斯函数具有良好的计算性能,所GMM被广泛地应用[1]。
下面言归正传,我们通过一个简单的例子来大概理解一下混合高斯模型和EM算法[3]
混合模型:
f(x)=(1−π)g1(x)+πg2x
高斯混合:
gj(x)=ϕθj(x),θj=(μj,σ2j)
继续盗个图[3]
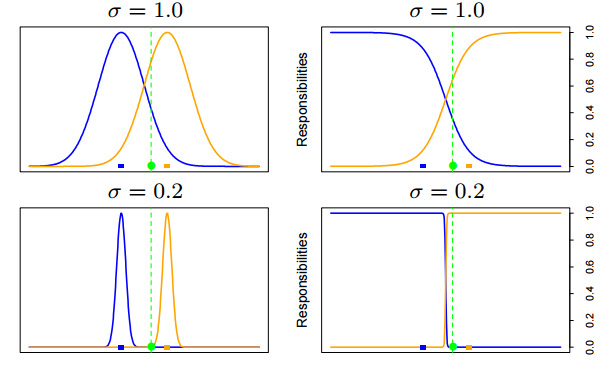
左边的两个图表示两个高斯模型,右边的图表示的是相对密度,也叫每个类的responsibilities,他被定义为:
g1(x)/(g1(x)+g2(x))
和
g2(x)/(g1(x)+g2(x))
,这个概念对我们使用EM非常重要,EM就是通过这个responsibilities来将两个类平滑的分开。
接着我们讲一个更为具体的例子:

我们有一堆数据,画在图中是上图红色的那个样子,显然他像极了两个连在一起的山峰,也就是两个高斯分布的叠加。
假设在这个例子中,我们有:
这里的 Δ={0,1}而Pr(Δ=1)=π
定义 ϕθ(x)为变量是θ=(μ,σ2) ,则上式的密度函数为:
那么对于我们所有的N个测试数据集,对数极大似然函数为:
因为我们是一个双函数高斯函数,我们让我们的隐式变量(就是刚才式子里面的 Δ )从0或1中取值(刚好两类么),是0就是第一种高斯分布,是1 就是第二种,如果我们知道 Δi 的值,也就是我们知道第i个高斯分布的参量我们知道怎么对应,那么上面那个公式可以改写成:
l(θ;z,Δ)=ΣNi=1log[(1−Δi)ϕθ1(yi)+Δiϕθ2(yi)]+ΣNi=1[(1−Δi)logπ+Δilog(1−π)]
(此公式的推导思路,概率再乘上对应的 Δ ,然后利用log 函数的性质求解)
下面就是推导过程中的重头戏了,我们刚才是假设我们知道每个高斯分布的权重,即 Δ ,所以EM就是用来获得 Δ ,从而我们可以用上式进行。定义:
上式被称作我们刚才提到的“responsibility”,因为这里我们讨论的是 Δi=1 ,所以是第二个高斯模型的“responsibility”。

【1】http://www.cnblogs.com/CBDoctor/archive/2011/11/06/2236286.html
【2】http://www.cnblogs.com/mindpuzzle/archive/2013/04/24/3036447.html
【3】http://statweb.stanford.edu/~tibs/stat315a/LECTURES/em.pdf















 31万+
31万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









