









分布式
由分布在不同主机上的进程(程序)协同子啊一起才能构成整个应用。
Browser/web server:瘦客户端程序.
大数据4V特征
1.Volumn : 体量大
2.Velocity : 速度快
3.Variaty : 样式多
4.Value : 价值密度低
Hadoop
可靠的、可伸缩的、分布式计算的开源软件.
是一个框架、允许跨越计算机集群的大数据集处理,使用简单的编程模型(MapReduce)。
可从单个服务器扩展到几千台主机,每个节点提供了计算和存储的功能。而不是依赖高可用性的机器
依赖于应用层面上的实现,
Hadoop 模块
1.hadoop common 公共类库
2.HDFS hadoop 分布式文件系统
3.Hadoop Yarn 作业调度和资源管理框架
4.Hadoop MapReduce 基于yarn系统的大数据集并行处理技术
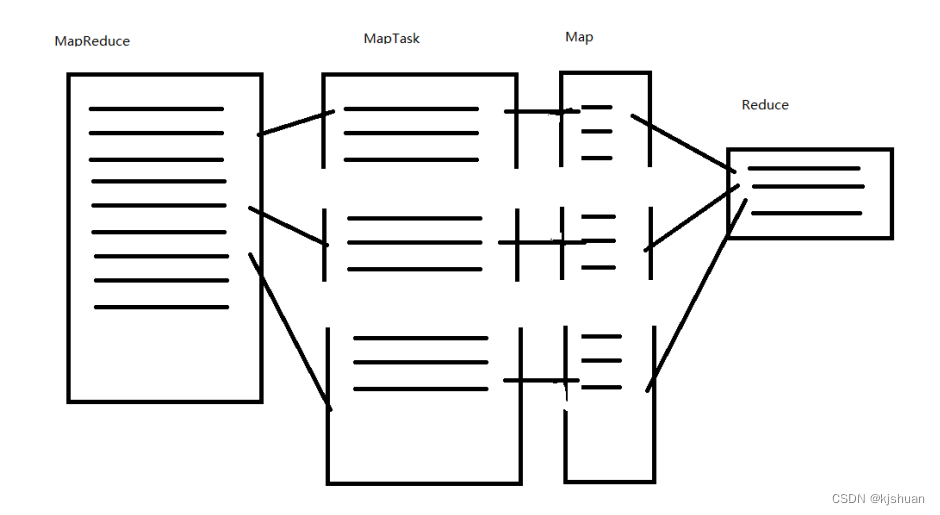
MapReduce 工作原理
Hadoop安装
- Jdk(建议使用JDK 1.8.11)
前提准备linux环境
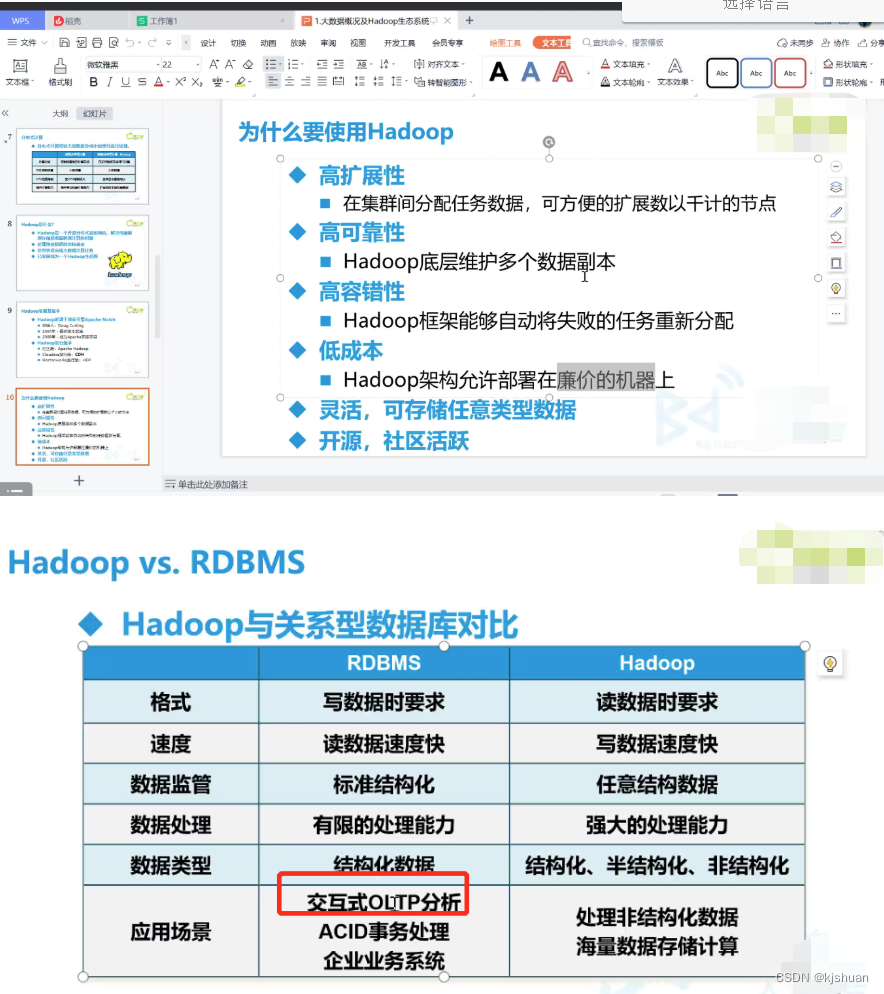
大数据hbase
1 文件系统
linux Exts XFS windons HTFS hbase先安装 HDFS
2.图标
hbase 虎鲸 hive 大象头蜜蜂尾巴 hadoop 大象
3大数据生态圈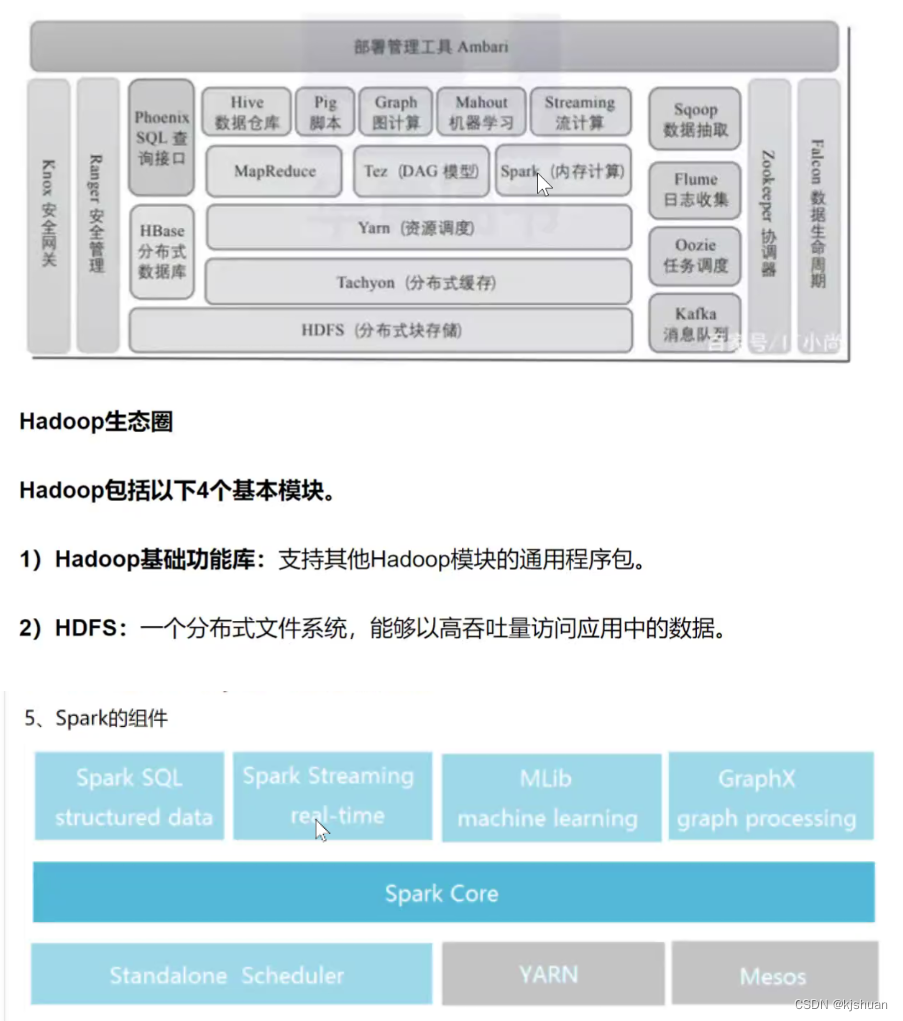
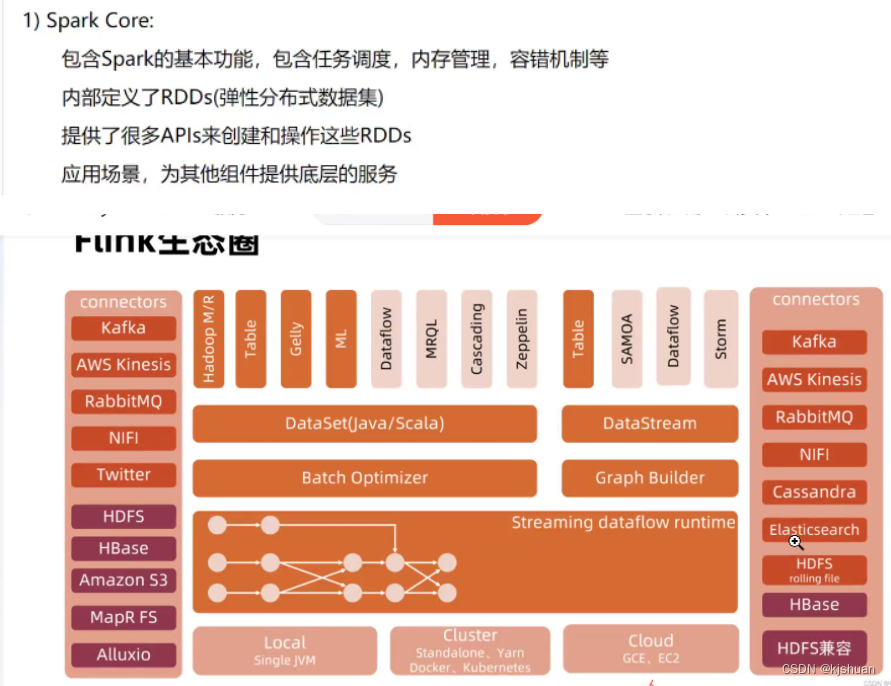
Elasticsearch 搜索引擎 使用语言 (Java/Scala)
Hadoop3个版本 1 社区版 Apache Hadoop(免费 功能不行) 2 发行版 CDH(目前使用) 3 发行版 HDP(收费 功能牛逼)
OLAP 数据库 OLTA 大数据
HDFS MapReduce YARN
单机Hadoop 运行环境搭建
1复制base 为hadoop01
hostnamectl set-hostname hadoop01vim /etc/systemconfig/network-scripts/ifcfg-ens33
vim /etc/hosts
拖入hadoop相关jar包到 /opt
cd /opt
tar -zxf hadoop-2.6.0-cdh5.14.2.tar.gz
mv hadoop soft/hadoop260
cd soft/hadoop260
cd etc/hadoop
pwd
vim hadoop-env.sh
1=============================
export JAVA_HOME=/opt/soft/jdk180
:wq
1=============================
vim core-site.xml
2============================
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.64.210:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/soft/hadoop260/tmp</value>
</property>
</configuration>
:wq
2============================
vim hdfs-site.xml
3============================
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
:wq
3============================
cp mapred-site.xml.template mapred-site.xml
vim mapred-site.xml
4============================
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
:wq
4============================
vim yarn-site.xml
5============================
<configuration>
<property>
<name>yarn.resourcemanager.localhost</name>
<value>localhost</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
:wq
5============================
#配置hadoop环境变量 注意用自己的 hadoop260
vim /etc/profile
6============================
# Hadoop ENV
export HADOOP_HOME=/opt/soft/hadoop260
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_INSTALL=$HADOOP_HOME
:wq
6============================
#激活上面的配置
source /etc/profile
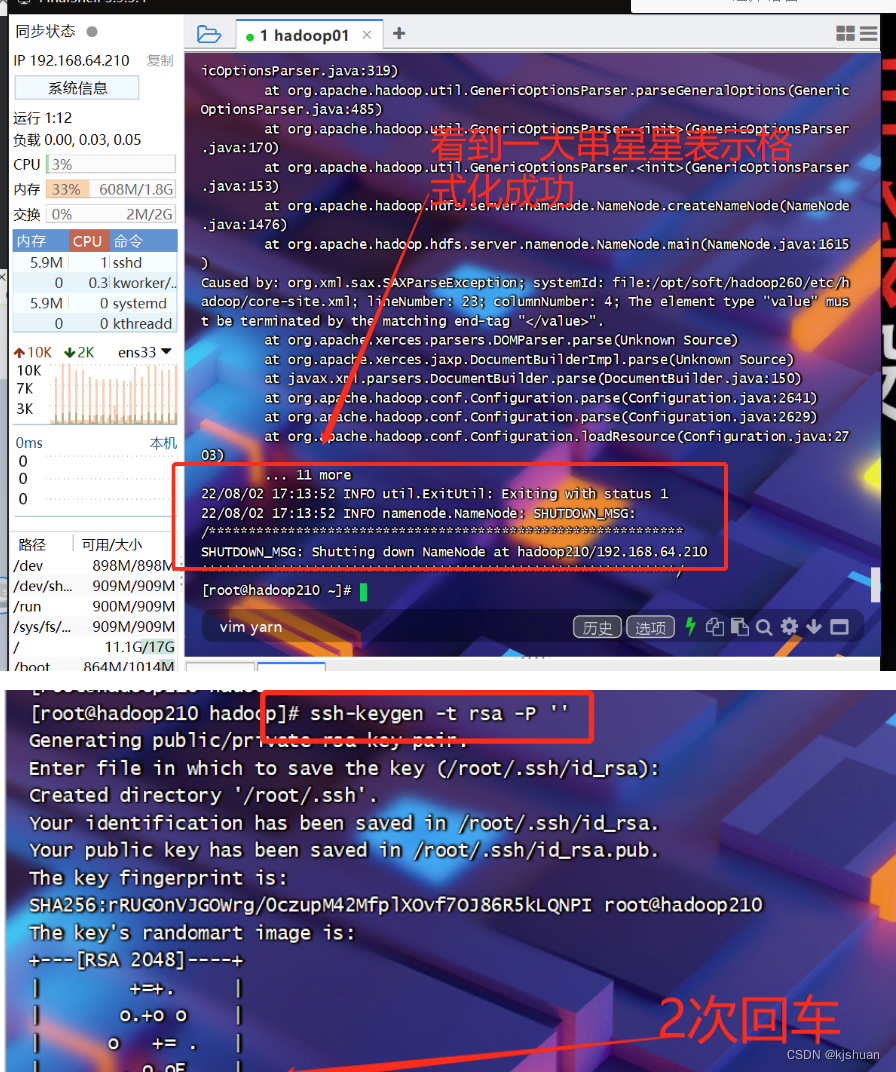
#无密码登录
ssh-keygen -t rsa -P ''
cd /root/.ssh/
ls
ssh-copy-id -i ~/.ssh/id_rsa.pub root@192.168.64.210
yes
ok
ls
ll
ssh 192.168.64.210
exit
#远程登录 hadoop210为自己的主机名 /ect/hosts 或者systemctl sethostname hadoop210#
ssh hadoop210
yes
exit
#直接登录 免密
ssh hadoop210
exit
#格式化NameNode
hdfs namenode -format
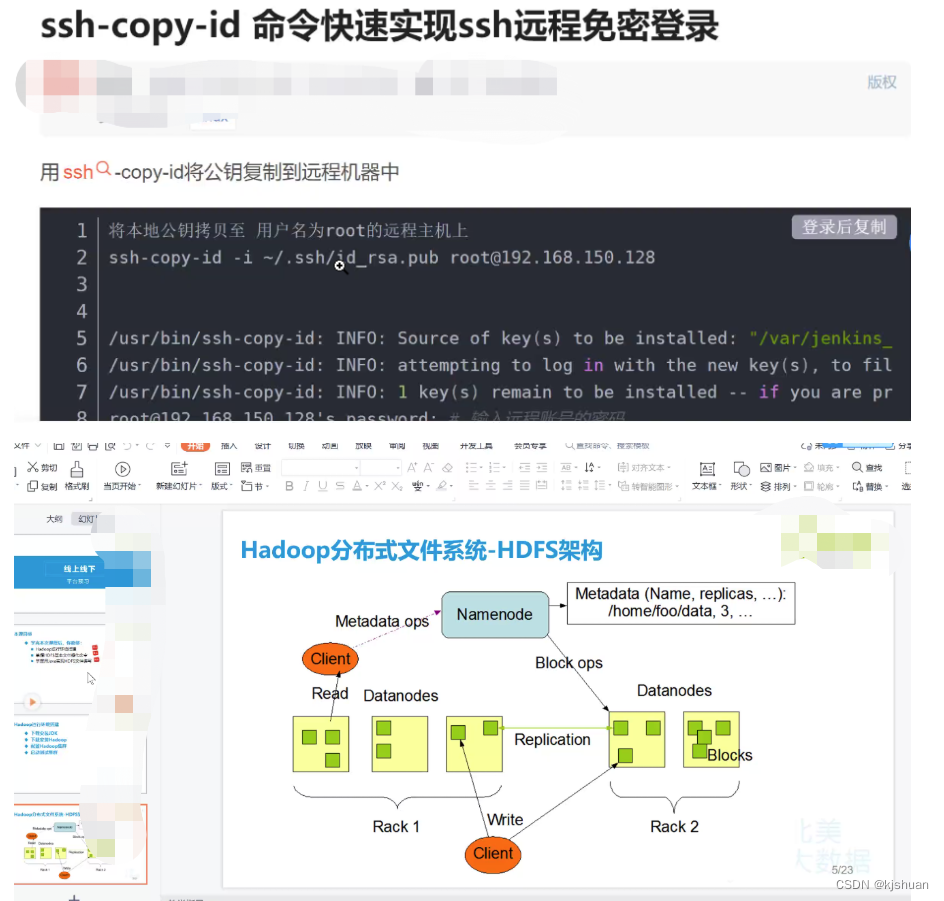
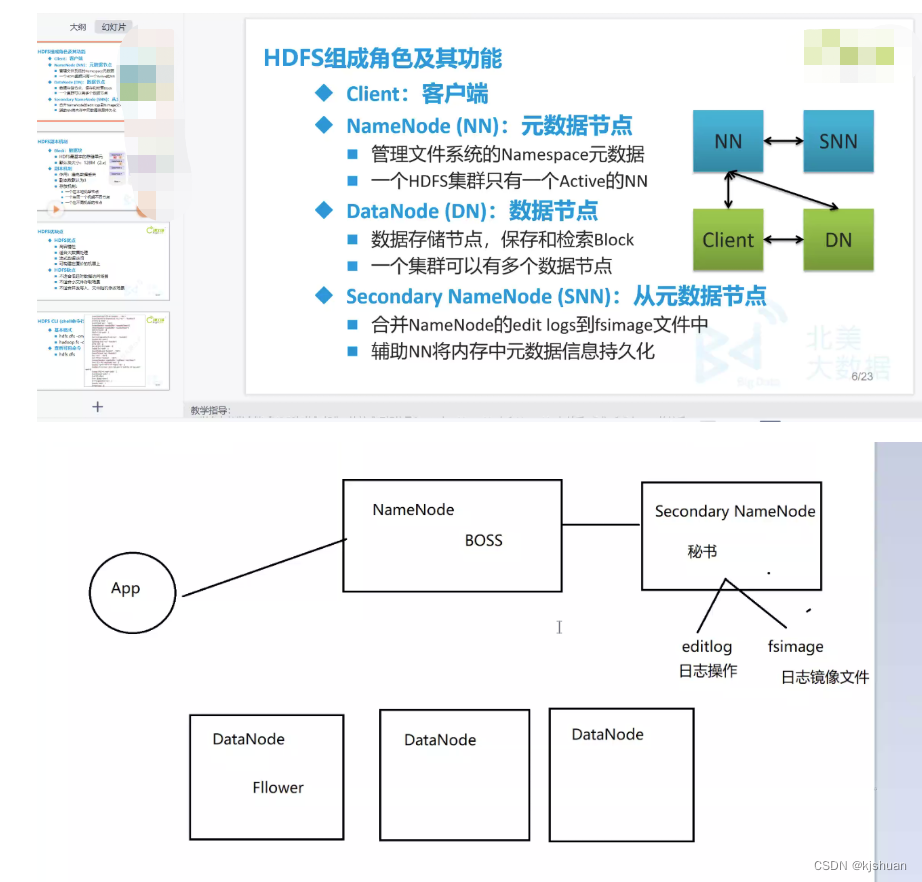
读
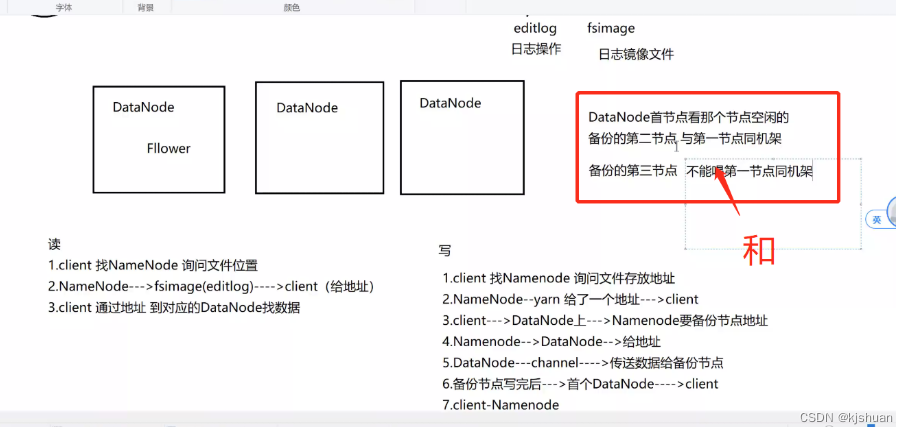
1 client 找NameNode 询问文件位置 2 NameNode--->fsimage(editlog)--->client(给地址) 3 client 通过地址 到对应的DataNode找数据
写
1 client 找NameNode 讯问文件存放地址 2 NameNode--yarn 给了一个地址--->client 3 client--->DataNode上--->NameNode要备份节点地址 4 NameNode--->DataNode-->给地址 5 DataNode--channel-->传送数据给备份节点 6 备份节点写完后--->首个DataNode--->client 7 client-NameNode
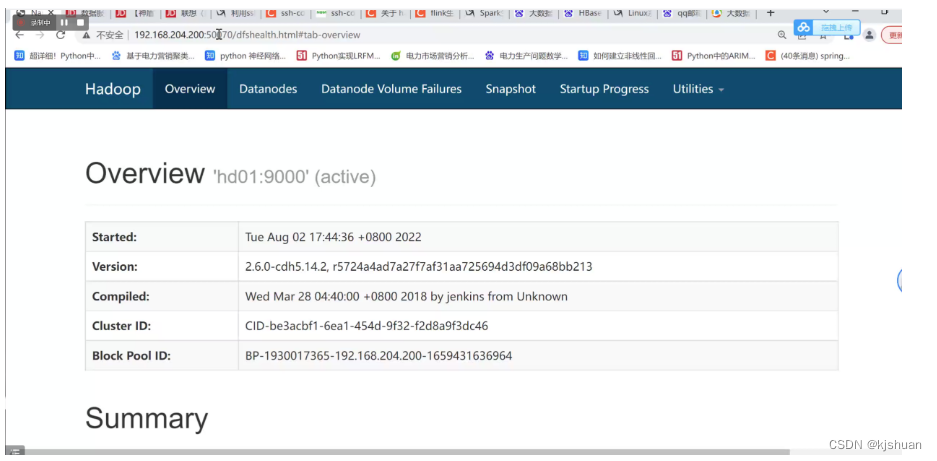
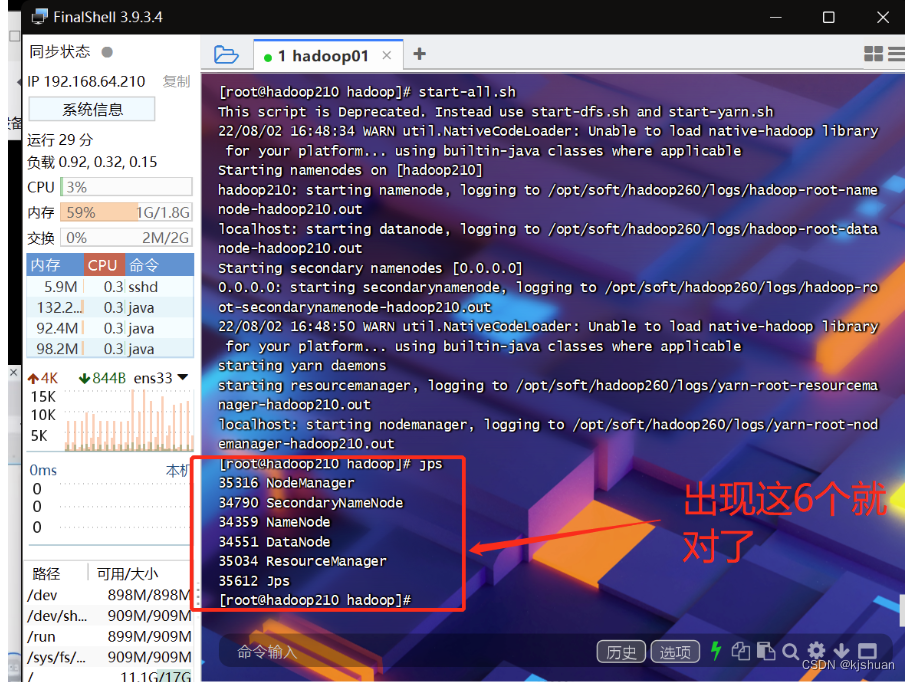
2启动hadoop01
start-all.sh yes yes jps #浏览器查看hadoop单机集群搭建完成 192.168.64.210:50070
3.关闭系统
stop-all.sh
















 2546
2546











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











