







在分布式系统领域,有一个理论,对于分布式系统的设计影响非常大,那就是 CAP 理论,即对于一个分布式系统而言,它是无法同时满足 Consistency(强一致性)、Availability(可用性) 和 Partition tolerance(分区容忍性) 这三个条件的,最多只能满足其中两个。但在实际中,由于网络环境是不可信的,所以分区容忍性几乎是必不可选的,设计者基本就是在一致性和可用性之间做选择,当然大部分情况下,大家都会选择牺牲一部分的一致性来保证可用性(可用性较差的系统非常影响用户体验的,但是对另一些场景,比如支付场景,强一致性是必须要满足)。但是分布式系统又无法彻底放弃一致性(Consistency),如果真的放弃一致性,那么就说明这个系统中的数据根本不可信,数据也就没有意义,那么这个系统也就没有任何价值可言。
CAP 理论
CAP 理论三个特性的详细含义如下:
- 一致性(Consistency):每次读取要么是最新的数据,要么是一个错误;
- 可用性(Availability):client 在任何时刻的读写操作都能在限定的延迟内完成的,即每次请求都能获得一个响应(非错误),但不保证是最新的数据;
- 分区容忍性(Partition tolerance):在大规模分布式系统中,网络分区现象,即分区间的机器无法进行网络通信的情况是必然会发生的,系统应该能保证在这种情况下可以正常工作。
分区容忍性
很多人可能对分区容忍性不太理解,知乎有一个回答对这个解释的比较清楚(CAP理论中的P到底是个什么意思?),这里引用一下:
- 一个分布式系统里面,节点组成的网络本来应该是连通的。然而可能因为一些故障,使得有些节点之间不连通了,整个网络就分成了几块区域。数据就散布在了这些不连通的区域中。这就叫分区。
- 当你一个数据项只在一个节点中保存,那么分区出现后,和这个节点不连通的部分就访问不到这个数据了。这时分区就是无法容忍的。
- 提高分区容忍性的办法就是一个数据项复制到多个节点上,那么出现分区之后,这一数据项就可能分布到各个区里,容忍性就提高了。
- 然而,要把数据复制到多个节点,就会带来一致性的问题,就是多个节点上面的数据可能是不一致的。
- 要保证一致,每次写操作就都要等待全部节点写成功,而这等待又会带来可用性的问题。
- 总的来说就是,数据存在的节点越多,分区容忍性越高,但要复制更新的数据就越多,一致性就越难保证。为了保证一致性,更新所有节点数据所需要的时间就越长,可用性就会降低。
CAP 如何选择
CAP 理论一个经典原理如下所示:
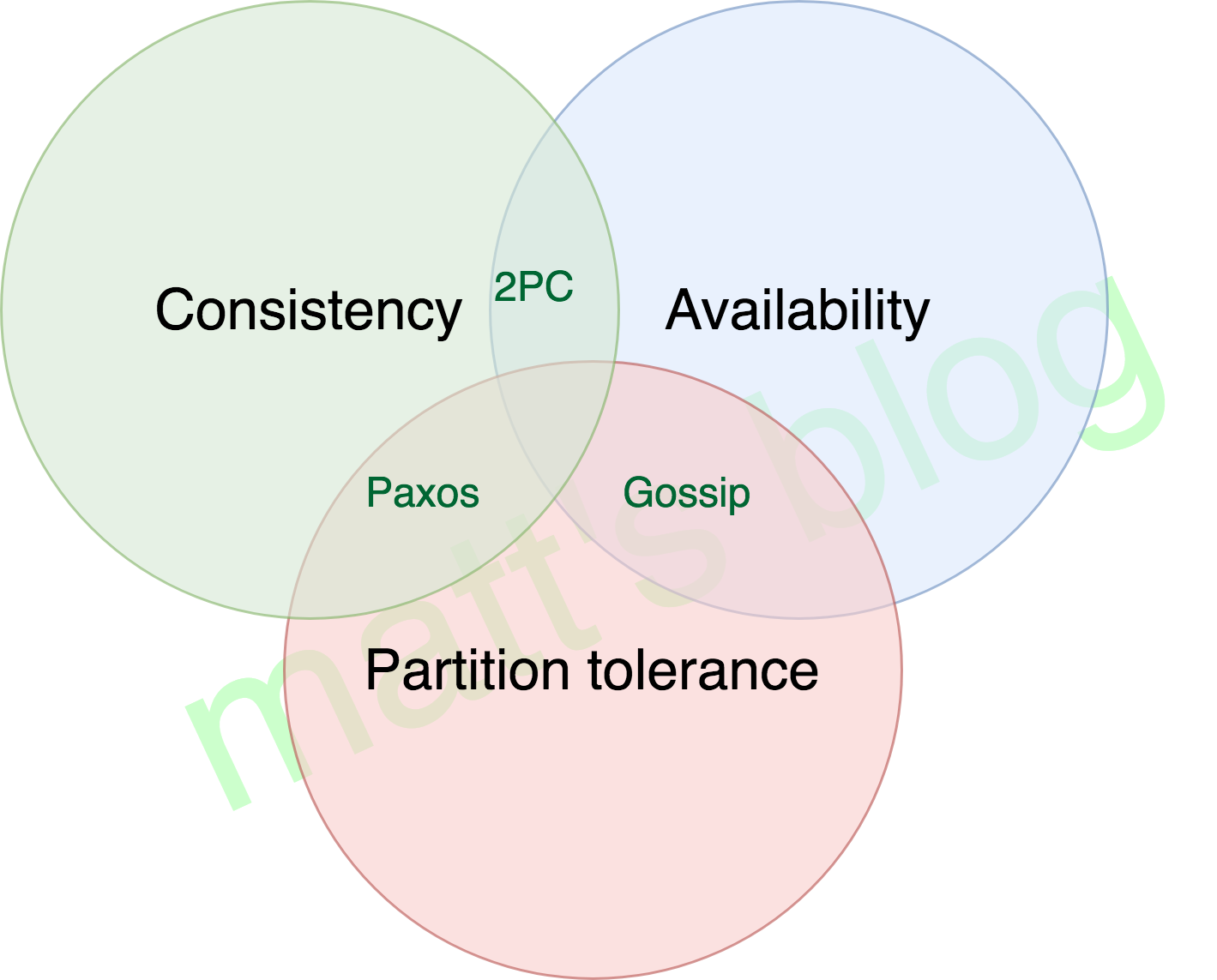
CAP 定理表明,在存在网络分区的情况下,一致性和可用性必须二选一。而在没有发生网络故障时,即分布式系统正常运行时,一致性和可用性是可以同时被满足的。但是,对于大多数互联网应用来说,因为规模比较大,部署节点分散,网络故障是常态,可用性是必须要保证的,所以只有舍弃一致性来保证服务的 AP。但是对于一些金融相关行业,它有很多场景需要确保一致性,这种情况通常会权衡 CA 和 CP 模型,CA 模型网络故障时完全不可用,CP 模型具备部分可用性。
在一个分布式系统中,对于这三个特性,我们只能三选二,无法同时满足这三个特性,三选二的组合以及这样系统的特点总结如下(来自左耳朵耗子推荐:分布式系统架构经典资料):
- CA (Consistency + Availability):关注一致性和可用性,它需要非常严格的全体一致的协议,比如“两阶段提交”(2PC)。CA 系统不能容忍网络错误或节点错误,一旦出现这样的问题,整个系统就会拒绝写请求,因为它并不知道对面的那个结点是否挂掉了,还是只是网络问题。唯一安全的做法就是把自己变成只读的。
- CP (consistency + partition tolerance):关注一致性和分区容忍性。它关注的是系统里大多数人的一致性协议,比如:Paxos 算法 (Quorum 类的算法)。这样的系统只需要保证大多数结点数据一致,而少数的结点会在没有同步到最新版本的数据时变成不可用的状态。这样能够提供一部分的可用性。
- AP (availability + partition tolerance):这样的系统关心可用性和分区容忍性。因此,这样的系统不能达成一致性,需要给出数据冲突,给出数据冲突就需要维护数据版本。Dynamo 就是这样的系统。
对于分布式系统分区容忍性是天然具备的要求,否则一旦出现网络分区,系统就拒绝所有写入只允许可读,这对大部分的场景是不可接收的,因此,在设计分布式系统时,更多的情况下是选举 CP 还是 AP,要么选择强一致性弱可用性,要么选择高可用性容忍弱一致性。
一致性模型
关于分布式系统的一致性模型有以下几种:
强一致性
当更新操作完成之后,任何多个后续进程或者线程的访问都会返回最新的更新过的值,直到这个数据被其他数据更新为止。但是这种实现对性能影响较大,因为这意味着,只要上次的操作没有处理完,就不能让用户读取数据。
弱一致性
系统并不保证进程或者线程的访问都会返回最新更新过的值。系统在数据写入成功之后,不承诺立即可以读到最新写入的值,也不会具体的承诺多久之后可以读到。但会尽可能保证在某个时间级别(比如秒级别)之后,可以让数据达到一致性状态。
最终一致性
最终一致性也是弱一致性的一种,它无法保证数据更新后,所有后续的访问都能看到最新数值,而是需要一个时间,在这个时间之后可以保证这一点,而在这个时间内,数据也许是不一致的,这个系统无法保证强一致性的时间片段被称为「不一致窗口」。不一致窗口的时间长短取决于很多因素,比如备份数据的个数、网络传输延迟速度、系统负载等。
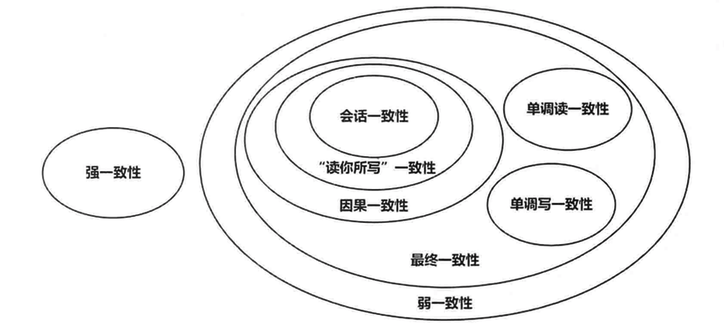
最终一致性在实际应用中又有多种变种:
| 类型 | 说明 |
|---|---|
| 因果一致性 | 如果 A 进程在更新之后向 B 进程通知更新的完成,那么 B 的访问操作将会返回更新的值。而没有因果关系的 C 进程将会遵循最终一致性的规则(C 在不一致窗口内还是看到是旧值)。 |
| 读你所写一致性 | 因果一致性的特定形式。一个进程进行数据更新后,会给自己发送一条通知,该进程后续的操作都会以最新值作为基础,而其他的进程还是只能在不一致窗口之后才能看到最新值。 |
| 会话一致性 | 读你所写一致性的特定形式。进程在访问存储系统同一个会话内,系统保证该进程可以读取到最新之,但如果会话终止,重新连接后,如果此时还在不一致窗口内,还是可嫩读取到旧值。 |
| 单调读一致性 | 如果一个进程已经读取到一个特定值,那么该进程不会读取到该值以前的任何值。 |
| 单调写一致性 | 系统保证对同一个进程的写操作串行化。 |
它们的关系又如下图所示(图来自 《大数据日知录:架构与算法》):
分布式一致性协议
为了解决分布式系统的一致性问题,在长期的研究探索过程中,业内涌现出了一大批经典的一致性协议和算法,其中比较著名的有二阶段提交协议(2PC),三阶段提交协议(3PC)和 Paxos 算法(本文暂时先不介绍)。
Google 2009年 在Transaction Across DataCenter 的分享中,对一致性协议在业内的实践做了一简单的总结,如下图所示,这是 CAP 理论在工业界应用的实践经验。
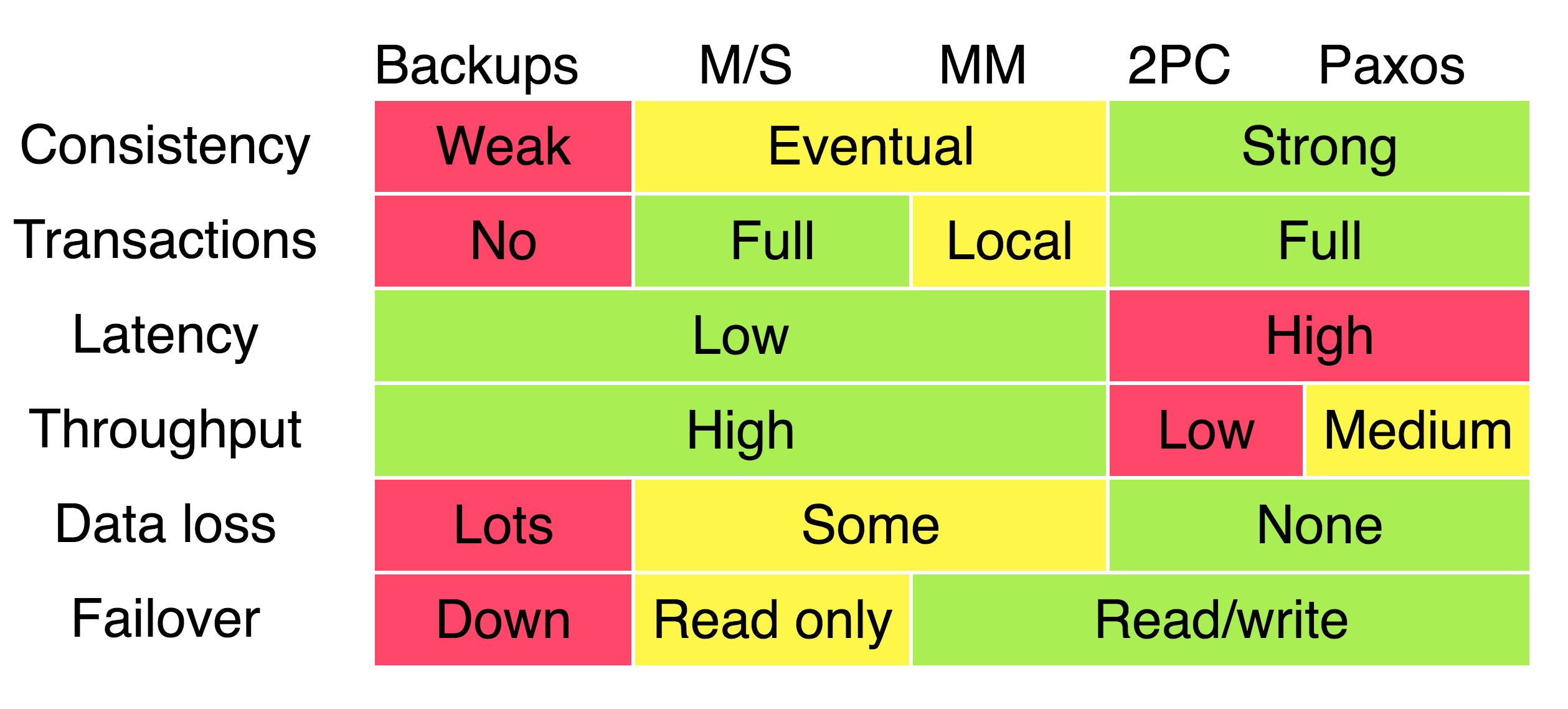
其中,第一行表头代表了分布式系统中通用的一致性方案,包括冷备、Master/Slave、Master/Master、两阶段提交以及基于 Paxos 算法的解决方案,第一列表头代表了分布式系统大家所关心的各项指标,包括一致性、事务支持程度、数据延迟、系统吞吐量、数据丢失可能性、故障自动恢复方式。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









