






【编者按】Apache Mesos作为一个非常优秀的分布式资源管理和调度系统,如何高效的管理和分配资源,必然成为它研究和努力的主要方向之一。本文是基于IBM Platform DCOS Team在资源调度领域的优秀经验,以及他们在Mesos社区为提升Mesos资源利用率而正在进行的实践活动,深度剖析了Mesos资源的收集和调度原理,以及如何在Mesos中提供Revocable资源来提高Mesos数据中心的资源利用率。最后,作者结合自己在Docker Swarm社区的贡献经验,重点讲解了在Docker Swarm如何支持Mesos的Revocable资源。来自IBM Platform软件工程师王勇桥将带来“Swarm和Mesos集成指南”系列文章,带大家了解Swarm和Mesos集成的架构和原理,Swarm基于Mesos集群的实战部署和配置,以及基于IBM Platform自身在资源调度、分布式计算领域方面的实践经验,向大家介绍IBM Platform对Mesos在资源调度方面的策略优化,以及以Swarm为例向大家介绍这些优化将对Mesos上层的framework和企业级用户带来哪些增强性的体验。本文为第三篇:资源利用率优化实践。
Mesos集群资源收集
Apache Mesos是一种分布式的资源管理和调度框架,它被称为是分布式系统的内核。那么Mesos是怎么在这个分布式的异质的环境中收集资源的呢?官方给出的架构图如下所示:
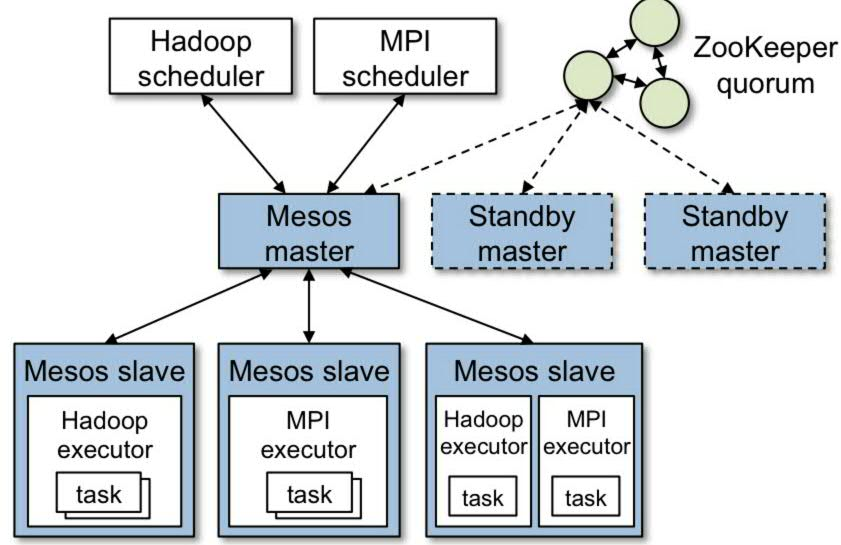
默认情况下每一个Mesos Slave会主动采集它所在机器上的实际资源量, 现在默认情况下主要收集以下四种资源:
- CPU: 默认调用系统函数os::cpus()来获取系统CPU的个数,如果在某些特殊的平台或者系统上获取失败,将采用默认值1。
- Memory:默认调用系统函数os::memory()来获取系统内存的大小,如果在某些特殊的平台或者系统上获取失败,将采用默认值1GB。
- Disk:注意,每一个Slave它不是获取整个机器的硬盘的大小,它默认调用系统函数fs::size(flags.work_dir)来获取Mesos Slave指定的工作目录(Mesos Slave默认的工作目录为/tmp/mesos,你可以通过在启动Mesos slave的时候指定–work_dir参数来修改这个值)的文件系统的硬盘的大小。如果在某些特殊的平台或者系统上获取失败,将采用默认值10GB;在获取成功的情况下,如果获取的值大于默认值10GB,则预留5GB留给Mesos slave本身使用,剩下的当作此计算节点的存储资源交给其他framework使用,如果小于默认值10GB,则将获取值的一半预留,剩下的一半下的当作此计算节点的存储资源交给其他framework使用。
- Ports:默认使用默认值”[31000-32000]”。
当然了你可以通过以下两种方式改变默认的行为:
1.通过在启动Mesos Slave时指定–resources参数来定义每个计算节点上可以消费的资源量。它的值有两种格式:
第一种是分号分割的键值对字符串列表:“name(role):value;name:value…”。name表示资源的名称,例如可以是cpus,mem,disk和ports以及用户自定义资源类型名称等,role表示资源预留的角色(就是Mesos中的static reservation),如果不指定,则表示此资源预留给默认的role(通过—default-role参数指定,如果不指定,则表示Mesos默认的role(*)),value表示此资源的值,现在支持的类型有主要有三种SCALAR数字类型,RANGES范围类型,比如端口,SET离散枚举值。
第二种是一个文件的路径,如(file:///path/to/file or /path/to/file),这个文件的格式是一个JSON 文件,例如:
[
{
"name": "cpus",
"type": "SCALAR",
"scalar": {
"value": 24
}
},
{
"name": "mem",
"type": "SCALAR",
"scalar": {
"value": 24576
}
}
] 注意:如果你指定–resources这个参数它不会完全覆盖默认的行为,也就是说只有你指定了某种具体的资源,它才会覆盖这种具体资源的收集方式。例如你指定:–resources=”cpus(role1):1;cpus(*):2”,则表示,此计算节点总共有三个CPU,一个预留给role1,另两个预留给默认的role(*),其他的三种资源memory,disk,ports仍然按照默认的方式收集。
2.由于通过–resources的方式来指定某种资源,它需要你在启动对应的Mesos Salve的时候就知道具体的资源量,但是对于有些集成的系统,它的资源是由某些第三方的资源收集服务获取的,比如Collectd。对于这种需求,Mesos同时提供了一种 hook的机制,来让用户实现自己的Moudle,定制他们收集资源的策略。
综上所述,Mesos集群中的每一个Slave节点,通过以上的资源收集方式,将所有的资源在它注册的时候上报给Master节点,Master将会利用它的资源调度策略,把这些资源以“Offer”的形式动态的分配给上层的framework,framework可以根据自身任务对资源的要求来选择是否接收这个Offer,一旦这个Offer被接受,framework将通过Mesos Master的任务调度机制,将任务运行在数据中心的指定的Slave节点上。
Mesos集群资源调度策略
Apache Mesos能够成为数据中心资源调度的内核,一个非常重要的原因就是它能够支持大多数framework的接入,那么Mesos要考虑的一个主要的问题就是如何为众多的framework分配资源。在mesos中,这个功能是由Master中的一个单独的模块(Allocation module)来实现的,因为Mesos设计用来管理异构环境中的资源,所以它实现了一个可插拔的资源分配模块架构,用户可以根据自己的需求来实现定制化的分配策略和算法。
本章节将主要介绍Mesos默认的资源调度模块DRF Allocator。官方默认给出了一个资源调度的流程图,如下所示:
DRF(Dominant Resource Fairness) Allocator,它的目标是确保每一个上层的Framework能够接收到它最需资源的公平份额。下边我们先简单介绍一下DRF算法。在DRF中一个很重要的概念就是主导资源(dominant resource),例如对于运行计算密集型任务的framework,它的主导资源是CPU,对于运行大量依赖内存的任务的framework,它的主导资源是内存。DRF Allocator在分配资源之前,首先会按照资源类型计算每个framework占有(已经使用的资源+已经以offer的形式发给framework但是还没有使用的资源)份额百分比,占有比最高的为这个framework的主导资源,然后比较每个framework主导资源的百分比,哪个值小,则将这个机器上资源发给对应的framework。你可以参考Benjamin Hindman的这篇论文https://www.cs.berkeley.edu/~alig/papers/drf.pdf 来了解DRF算法的详细说明。
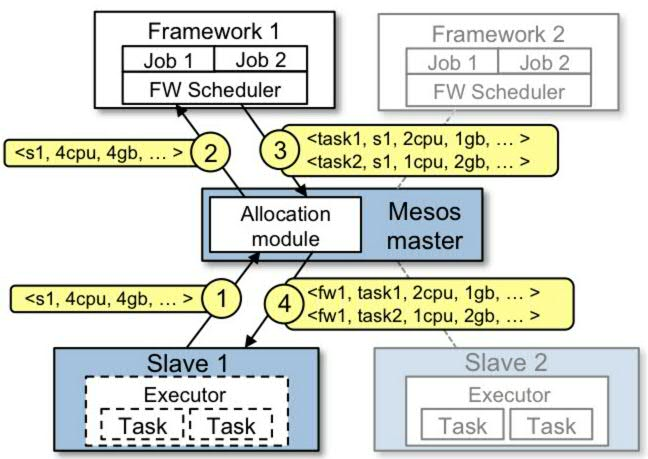
另外,Mesos集群管理员可以通过以下几种方式提供更多的资源分配策略:
- 给某个framework设置权重(weight)来使某个framework获取更多的资源。
- 可以使用static/dynamic reservation指定将某一个Slave节点上的资源发送给特定role下的framework。
- 可以为某个role配置quota来保证这个role下的framework在整个Mesos集群中获取资源的最小份额。
- Framework收到资源之后,可以创建持久化存贮卷,保证这些存储资源不能被其他的framework使用。
使用Revocable资源来提高资源利用率
对于DRF的Allocator,在资源分配方面可能存在以下几个方面的问题:
1.资源碎片的问题。由于DRF总是追求公平,它会把剩余资源公平的分配给所有的framework,但是这种公平分配可能会导致所有的framework在一个分配的周期中都没有足够的资源来运行它的任务。
2.本性贪婪的framework为了提高它自身的性能,有时候总试图去hold offer,即便是它当时没有需要执行的任务,那么这个时候,这些resource也不能分配给另外的framework使用。
3.对于gang-scheduing(同时申请一组资源)类型的应用,由于Mesos在一个时刻只能提供集群的部分资源,那么这种类型的应用可能需要等待比较长的时间才可以运行。
为了适当的提高Mesos的资源利用率,Mesos社区现在引入了Revocable类型的资源。这种资源是一种可以被Mesos自行回收的资源,也就是说如果上层的framework使用这种资源来运行的它们的任务,那么这些任务就有随时被杀掉的可能。它被设计主要用来运行一些可靠性要求比较低,无状态的的任务。也就是说现在Mesos主要为上层的framework提供两种资源:
• Non-revocable resources: Mesos提供的最常见的资源类型,一旦这种资源offer发给某个framework,那么这些资源永远可以保证对这个framework可用,Framework一旦用这种资源运行它的任务,那么这个任务所占用的资源不能被Mesos收回,除非framework主动杀掉任务或者任务结束。
• Revocable resources:这种资源是framework没有充分利用的资源,Mesos会把这部分资源再发送给其他的framework使用,如果其他framework用这种resource运行任务,那么这个任务有可能在某个时候被Mesos杀掉来回收对应的资源。这种资源主要运来执行best-effort任务,例如后台分析,视频图像处理,芯片模拟等一些低优先级的任务。
首先Mesos在MESOS-354项目中初次引入了Revocable类型的资源,它是我们所说的其中一种Revocable类型的资源,它主要考虑的应用场景是:在Mesos集群中,Mesos对资源的分配率一般可以达到80%以上,但实际的资源利用率却低于20%。在这个项目中,它提供了一种资源的再分配机制,就是把临时没有使用的资源(这些资源已经在之前分配给了某些任务,而且这些任务正在运行,但是它们没有完全使用已经分配给它们的资源)再分配给其他的任务。这种类型的revocable资源被称为Usage Slack的资源,下边我们来主要分析一下这种资源的生命周期:
- 第一步首先要确定哪些资源是Usage slack的revocable resource。每个Mesos Salve节点上的Resource estimator会定期和Resource Monitor模块交互来计算Usage slack,如果前后两次计算的值不同,则它会把这些revocable的资源上报给Mesos master。
- Mesos allocator会收到每个Slave上报的Usage slack的revocable resource,然后把这些revocable resource 发送给上层的framework。注:默认情况下framework是不接收revocable resource的,如果framework在注册时候指定REVOCABLE_RESOURCES capability,那么它将可以收到revocable resource。
- Framework可以选择使用这些revocable resource运行任务,这些revocable任务会像正常的任务一样被运行在对应的节点上。
- 每个Slave上的Monitor会监视原来task的运行状况,如果它的运行负载提高,则Qos controller模块会杀掉对应的revocable task来释放资源。
另外的一种Revocable资源则在MESOS-4967项目中引入,它主要由IBM Platform DCOS Team的工程师主导设计开发,目前基本的设计和编码已经完成,正在review阶段,很快会在最近的Mesos版本中支持。它主要是考虑到在Mesos中有些资源某些role reserve,但是没有被使用的情况(Allocation Slack),我们在后续的文章中会对其详细介绍。
对于Revocable类型的资源,需要注意以下几点:
- Revocable资源不能动态的reserve;
- Revocable资源不能用来创建存储卷;
- 运行任务的时候,对同一种资源,revocable资源和non-revocable资源不能混用,但是不同类型的资源可以混用。比如CPU用revocable resource,Memory可以使用non-revocable资源。
- 如果一个task使用了revocable资源或者它对应的executor使用了revocable资源,则整个container都被视为revocable task,可以被Qos controller杀掉。
在Swarm中使用Mesos的Revocable资源
在Docker Swarm目前的版本(v1.1.3)中,它不支持接收Mesos的revocable resource。IBM Platform DCOS Team对Swarm做了改进,使Swarm可以接收revocable resource,并且Swarm 的终端用户可以选择使用revocable 资源来运行他们低优先级的任务,或者使用non-revocable 资源来运行他们的高优先级任务。这样的话,如果Swarm和其他的framework共享Mesos集群资源的时候,其他framework的未充分利用的资源将可以被Swarm使用,这样的话Mesos集群整体的资源利用率将得到提升。注:这个新的改进可能会在Swarm的v1.1.3之后的某个版本release,如果哪位读者需要尝试这个新的特性,可以关注这个https://github.com/docker/swarm/pull/1946 pull request。
这个特性主要支持以下几种使用场景:
- Swarm集群的管理员可以配置Swarm集群来接收Mesos的revocable resource。
- Swarm的终端用户可以只选择非revocable资源来运行他们的高优先级任务。
- Swarm的终端用户可以优先考虑选择非revocable资源来运行他们的中优先级任务,如果没有非revocable资源可用,那么这些任务也可以选择revocable资源来运行。
- Swarm的终端用户可以只选择revocable资源来运行他们的低优先级任务。
- Swarm的终端用户可以优先考虑选择revocable资源来运行他们的低优先级任务。如果没有revocable资源可用,那么这些任务也可以选择非revocable资源来运行。
- Swarm的终端用户可以查看他们的container使用什么资源来运行的。
Swarm支持Revocable resource主要做了以下几个方面的改进:
- 在Swarm manage命令中新增一个cluster参数选项mesos.enablerevocable,通过将这个参数设置为true来使Swarm可以接收Mesos发送的revocable资源。当然按照Swarm之前的设计原则,你可以export SWARM_MESOS_ENABLE_REVOCABLE环境变量来替代那个参数选项。
- Mesos会定期的发送offer给Swarm,当Swarm接收到这些offer之后,需要修改对应Docker engine的资源类型,现在支持的有三种类型:Regular(表示这个节点上只有非revocable资源),Revocable(表示这个节点上只有revocable资源),Any(表示这个节点上即有非revocable资源,也有revocable资源),Unknown(表示这个节点的资源类型不确定,也就是这个节点上暂时没有可用的资源,这类节点如果没有正在运行的任务,它默认会被Swarm很快地删除)。
- 根据Swarm所提供的constraint来使用revocable或者非revocable资源来创建任务。最常见的constraint写法有四种:
- constraint:res-type==regular: 表示只使用非revocable资源来运行任务,如果没有非revocable资源,那么这个任务将会被放到任务队列中等待更多的非revocable资源,直到超时。
- constraint:res-type==~regular: 表示优先使用非revocable资源来运行任务,如果没有非revocable资源,那么选择使用revocable资源来执行。如果这两种资源都不够,这个任务将会被放到任务队列中等待Mesos发送更多的offer,直到超时。
- constraint:res-type==revocable: 表示只使用revocable资源来运行任务,如果没有revocable资源,那么这个任务将会被放到任务队列中等待更多的revocable资源,直到超时。
- constraint:res-type==~revocable: 表示优先使用revocable资源来运行任务,如果没有revocable资源,那么选择使用非revocable资源来执行。如果这两种资源都不够,这个任务将会被放到任务队列中等待Mesos发送更多的offer,直到超时。
- constraint:res-type==*: 表示可以使用任何类型的资源来运行任务,如果revocable资源和非revocable资源都不够,那么这个任务将会被放到任务队列中等待Mesos发送更多的offer,直到超时。
几个细节需要特别注意:
- 由于Swarm的constraint支持正则表达式,所以当指定的正则表达式同时满足使用revocable和非revocable的资源,那么我们默认优先使用非revocable的资源来运行任务,如果非revocable的资源不够用,我们才会使用revocable资源运行任务。
- 在Swarm对使用revocable资源的设计中,同一个任务不支持即使用revocable资源又使用非revocable资源。但是Mesos的这种限制只是局限于同一类型的资源,也就是说在Mesos中,不同类型的资源是可以混用的。个人认为Mesos的这种设计不是很合理,原因是,主要某个任务使用了revocable资源,那么它就会被当作revocable任务,可以被Qos控制器杀掉,根本就不会考虑它所使用的非revocable资源。
- 在Swarm中创建container的时候,同一个constraint是可以指定多次的,Swarm会把它当作各自不同的constraint来对待,一个一个进行过滤。但是在此设计中,我们不允许Swarm用户指定多个res-type,如果指定多个,创建container将会失败。
- Mesos现在的设计是将非revocable资源和revocable资源放在了同一个offer中发给上层framework的,也就是说当Swarm收到offer之后,需要遍历offer中的每个资源来查看它的类型,来更新对应Docker engine的资源类型。在创建容器的时候,需要遍历某个节点上的所有的offer来计算所需要的资源,这可能会带来性能上的问题。比较庆幸的是,Mesos正在考虑对这个行为作出改进,也就是把revocable资源和非revocable资源用不同的offer来发送,也就说到时候framework收到的offer要么全是revocable资源,要么全是非revocable资源,这样的话就可以提高Swarm计算资源的性能。顺便说一下,Mesos做这个改进的出发点是考虑到rescind offer的机制,因为rescind offer是以整个offer为单位回收资源的,如果我们把revocable资源和非revocable资源放到一个offer进行发送,那么回收revocable资源的时候,不可避免的会同时回收非revocable资源。
下边我将带领大家进行实战,用Swarm使用Mesos的revocable资源。在进行之前,我建议读者先看看和这篇文章相关的前两篇《Swarm和Mesos集成指南-原理剖析》和 《Swarm和Mesos集成指南-实战部署》。
为了简化环境部署的复杂度,使读者可以轻松地在自己的环境上体验以下这个新的特性,我提供了三个Docker Image,读者可以很轻松的使用这三个Image 搭建起体验环境。
1.准备三台机器,配置好网络和DNS服务,如果没有DNS服务,可以直接配置/etc/hosts,使这三台机器可以使用机器名相互访问。我使用的是三台Ubuntu 14.04的机器:
wangyongqiao-master.grady.com
wangyongqiao-slave1.grady.com
wangyongqiao-slave2.grady.com
2.在wangyongqiao-master.grady.com上执行以下Docker Run命令启动Zookeeper节点,用作Mesos集群的服务发现,在这里我们直接使用mesoscloud提供的zookeeper镜像。
# docker run –privileged –net=host -d mesoscloud/zookeeper
其实这一步不是必须的,但是如果你的Mesos集群不使用Zookeeper,在Swarm使用的依赖库mesos-go有一个问题会导致Mesos Master重启或者failover之后,Swarm manage不会向Mesos重新注册(re-register),需要用户重新启动swarm manage节点,这会导致它之前运行的所有任务都变成了孤儿任务。我在Swarm社区已经创建了一个issue来跟踪这个问题,具体的情况和重现步骤你可以参考:https://github.com/docker/swarm/issues/1730。
3.在wangyongqiao-master.grady.com上执行以下Docker Run命令启动Mesos Master服务。这里使用我提供了一个Mesos Master的Image:
# docker run -d \
-v /opt/mesosinstall:/opt/mesosinstall \
--privileged \
--name mesos-master --net host gradywang/mesos-master \
--zk=zk://wangyongqiao-master.grady.com:2181/mesos因为对于从事Mesos开发的人来说,经常性的修改Mesos的代码是不可避免的事情,所以为了避免每次改完代码都要重新build Docker镜像,在我提供的镜像中,其实并不包含Mesos的bin包,你在使用这个镜像之前必须先在本地build你的Mesos,然后执行make install把你的Mesos按照到某个空的目录,然后把这个目录mount到你的Mesos master容器中的/opt/mesosinstall目录。 具体的步骤你可以参考网上的这篇文章《Swarm和Mesos集成指南-实战部署》。
本例中,我把Mesos build完成之后安装在了本地的/opt/mesosinstall目录:
# make install DESTDIR=/opt/mesosinstall
# ll /opt/mesosinstall/usr/local/
total 36
drwxr-xr-x 9 root root 4096 Jan 15 20:02 ./
drwxr-xr-x 3 root root 4096 Jan 15 19:44 ../
drwxr-xr-x 2 root root 4096 Mar 18 13:30 bin/
drwxr-xr-x 3 root root 4096 Jan 15 20:02 etc/
drwxr-xr-x 5 root root 4096 Mar 18 13:30 include/
drwxr-xr-x 5 root root 4096 Mar 18 13:31 lib/
drwxr-xr-x 3 root root 4096 Jan 15 20:02 libexec/
drwxr-xr-x 2 root root 4096 Mar 18 13:31 sbin/
drwxr-xr-x 3 root root 4096 Jan 15 20:02 share/4.在wangyongqiao-slave1.grady.com和wangyongqiao-slave2.grady.com上执行以下命令,启动Mesos Salve服务。这里使用我提供了一个Mesos Slave的Image:
# docker run -d \
-v /opt/mesosinstall:/opt/mesosinstall \
--privileged \
-v /var/run/docker.sock:/var/run/docker.sock \
--name mesos-slave --net host gradywang/mesos-slave \
--master=zk://wangyongqiao-master.grady.com:2181/mesos \
--resource_estimator="org_apache_mesos_FixedResourceEstimator" \
--modules='{
"libraries": {
"file": "/opt/mesosinstall/usr/local/lib/libfixed_resource_estimator-0.29.0.so",
"modules": {
"name": "org_apache_mesos_FixedResourceEstimator",
"parameters": {
"key": "resources",
"value": "cpus:4"
}
}
}
}'在使用gradywang/mesos-slave这个镜像之前,必须注意以下这几点:
a.像上一步一样,我们假设你已经手动build,并安装了你的Mesos在/opt/mesosinstall目录下,当然你可以只需要在wangyongqiao-master.grady.com这个机器上构建你的Mesos,然后在wangyongqiao-master.grady.com机器上按照NFS服务,把安装目录/opt/mesosinstall挂载到其他的两个计算节点上,具体的步骤你可以参考网上的这片文章《Swarm和Mesos集成指南-实战部署》。
b.因为我们要演示怎么用在Swarm上使用Mesos提供的revocable资源,所以我们使用了Mesos默认提供的Fixed estimator,它是Mesos提供用来模拟计算revocable资源的一个工具,可以配置系统中固定提供的revocable资源。上例中我们默认在每个机器上配置4个CPU作为这个机器的revocable资源。
5.在wangyongqiao-master.grady.com上执行以下Docker Run命令启动Docker Swarm mange服务。这里使用我提供了一个Swarm的Image:
# docker run -d \
--net=host gradywang/swarm-mesos \
--debug manage \
-c mesos-experimental \
--cluster-opt mesos.address=192.168.0.2 \
--cluster-opt mesos.tasktimeout=10s \
--cluster-opt mesos.user=root \
--cluster-opt mesos.offertimeout=10m \
--cluster-opt mesos.port=3375 \
--cluster-opt mesos.enablerevocable=true \
--host=0.0.0.0:4375 zk://wangyongqiao-master.grady.com:2181/mesos注意:
在启动Swarm Manage的时候,我们使用了mesos.enablerevocable=true cluster 选项,这个选项是在这个patch中新增的,设置为true,表示Swarm愿意使用mesos的revocable资源。为了考虑向后的兼容性,如果你不指定这个选项,像往常一样启动Docker Swarm的时候,Swarm将默认不会接收Mesos的revocable资源。当然了,你可以像其他的参数一样,通过export这个变量SWARM_MESOS_ENABLE_REVOCABLE来设置。
192.168.0.2是wangyongqiao-master.grady.com机器的IP地址,Swarm会检查mesos.address是不是一个合法的IP地址,所以不能使用机器名。
gradywang/swarm-mesos这个镜像在Docker Swarm v1.1.3版本之上主要包含了四个新的特性:
- 支持了Mesos rescind Offer机制,相关的pull request是:https://github.com/docker/swarm/pull/1866。这个添加的特性有助于,在Mesos集群中的某个计算节点宕机之后,它上边的offer在Swarm中立即会被删除,不会在Swarm info中显示不可用的offer信息。
- 支持Swarm用一个特定的role来注册Mesos。在之前的版本中,Swarm只能使用Mesos默认的role(*)来注册。相关的pull request是:https://github.com/docker/swarm/pull/1890。
- 支持Swarm使用reserved资源来创建容器。在Swarm支持了用特定的role注册之后,我们就可以使用Mesos的static/dynamic reservation来给Swarm提前预定一些资源。这些资源只能给Swarm使用。现在的行为是,当Swarm的用户创建容器的时候,我们会默认的优先使用reserved资源,当reserved资源不够的时候,我们会用部分的unreserved资源弥补。相关的pull request是:https://github.com/docker/swarm/pull/1890。
- 支持Swarm使用revocable资源。这将是本文重点演示的特性。相关的pull request是:https://github.com/docker/swarm/pull/1946。
6.查看Docker Info:
# docker -H wangyongqiao-master.grady.com:4375 info
Containers: 0
Running: 0
Paused: 0
Stopped: 0
Images: 6
Server Version: swarm/1.1.3
Role: primary
Strategy: spread
Filters: health, port, dependency, affinity, constraint
Offers: 2
Offer: eba7f1e4-36ca-4a2f-9e24-e8cffce7393a-S0>>eba7f1e4-36ca-4a2f-9e24-e8cffce7393a-O0
└ cpus: 2
└ mem: 2.851 GiB
└ disk: 29.79 GiB
└ ports: 31000-32000
└ cpus(Revocable): 4
└ Labels: executiondriver=native-0.2, kernelversion=3.13.0-32-generic, operatingsystem=Ubuntu 14.04.1 LTS, res-type=any, storagedriver=aufs
Offer: eba7f1e4-36ca-4a2f-9e24-e8cffce7393a-S1>>eba7f1e4-36ca-4a2f-9e24-e8cffce7393a-O1
└ cpus: 2
└ mem: 2.851 GiB
└ disk: 29.79 GiB
└ ports: 31000-32000
└ cpus(Revocable): 4
└ Labels: executiondriver=native-0.2, kernelversion=3.13.0-32-generic, operatingsystem=Ubuntu 14.04.1 LTS, res-type=any, storagedriver=aufs
Plugins:
Volume:
Network:
Kernel Version: 3.13.0-32-generic
Operating System: linux
Architecture: amd64
CPUs: 12
Total Memory: 5.701 GiB
Name: wangyongqiao-master.grady.com从上边的信息我们可以观察到,每个机器上都收到了四个revocable的CPU,每个机器的res-type都是any,它代表他们上边既有regular资源,又有revocable资源。
7.下边我们演示上边所提到的那几个user casees。
- Swarm的用户可以只选择regular的资源来运行他们的高优先级的任务:
# docker -H wangyongqiao-master.grady.com:4375 run -d -e constraint:res-type==regular –cpu-shares 2 ubuntu:14.04 sleep 100
可以用以上的命令连续创建三个contianer,每个container使用两个regular的CPU,当创建第三个的时候,由于所有的regular CPU资源都被前两个使用,所以第三个会因为缺乏可用的regular资源而失败(执行超时)。
- Swarm的用户可以优先选择regular的资源来运行他们的中优先级的任务,如果没有足够的regular资源,也可以用revocable资源来运行这个任务:
# docker -H wangyongqiao-master.grady.com:4375 run -d -e constraint:res-type==~regular --cpu-shares 2 ubuntu:14.04 sleep 100可以用以上的命令连续创建三个contianer,每个container使用两个regular的CPU,当创建第三个的时候,由于所有的regular CPU资源都被前两个使用,所以第三个任务会使用revocable资源来创建。
• Swarm的用户可以只选择revocable的资源来运行他们的低优先级的任务,把regular的资源预留来执行后续的高优先级任务:
# docker -H wangyongqiao-master.grady.com:4375 run -d -e constraint:res-type==revocable --cpu-shares 2 ubuntu:14.04 sleep 100可以用以上的命令连续创建五个contianer,每个container使用两个regular的CPU,当创建第五个的时候,由于所有的revocable CPU资源都被前四个使用,所以第五个会因为缺乏可用的revocable资源而失败(执行超时)。
- Swarm的用户可以优先选择revocable的资源来运行他们的中优先级的任务,如果没有足够的revocable资源,也可以用regular资源来运行这个任务:
# docker -H wangyongqiao-master.grady.com:4375 run -d -e constraint:res-type==~revocable --cpu-shares 2 ubuntu:14.04 sleep 100可以用以上的命令连续创建五个contianer,每个container使用两个regular的CPU,当创建第五个的时候,由于所有的revocable CPU资源都被前四个使用,所以第五个会使用regular的资源来创建。
- Swarm的终端用户可以通过docker inspect来查看他们之前运行的contianer使用的是revocable资源还是regular资源:
# docker -H gradyhost1.eng.platformlab.ibm.com:4375 inspect --format "{{json .Config.Labels}}" 22a8a06ccf5e
{"com.docker.swarm.constraints":"[\"res-type==revocable\"]","com.docker.swarm.mesos.detach":"true","com.docker.swarm.mesos.name":"","com.docker.swarm.mesos.resourceType":"Revocable","com.docker.swarm.mesos.task":"e93593367025"}此文出自我个人的见解,非常期待读者的校正和启示。
IBM Platform DCOS作为Mesos社区的主要贡献组织,结合自身在资源调度方面丰富的实践应验,正在对Mesos资源的调度模块(Mesos Allocator)进行不断的优化,而且通过将自己的资源调度组件EGO与Mesos集成,为Mesos上层framework提供了更多的调度策略和更加友好的策略配置界面,同时,结合EGO丰富的资源调度策略,IBM platform DCOS丰富了Mesos的Revocable类型的资源,进一步提高了Mesos的资源利用率,通过Mesos-EGO,上层的framework基本可以看到整个集群的资源全貌,通过EGO界面的配置调度策略,合理高效的解决了资源申请冲突的问题,这些改进会对企业级用户带来新的Mesos体验。
作者简介:王勇桥,80后的IT工程师,供职于IBM多年,主要从事云计算领域相关的工作,Mesos和Swarm社区的贡献者。平时喜欢在业余时间研究DevOps相关的应用, 对容器化技术,自动化部署,持续集成,资源调度有较深的研究。
责编:魏伟,欢迎投稿,邮箱为weiwei@csdn.net,另外,CSDN OpenStack专家群已经建立,欢迎搜索微信“k15751091376”,由群主拉入。
















 642
642

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









