







作为深度学习的初学者,之前对图像处理的了解也几乎为零,看论文的时候有很多不懂的地方,有理解错误的地方欢迎指正~~红色标注笔者阅读文献时觉得重要的部分,蓝色主要标注注解和作为初学者对本文的一些理解。
摘要
本文主要研究:探究 卷积深度(convolutional network depth )在大规模图像识别中对预测性能的影响。
主要贡献在于:使用3x3的卷积核(convolution filters)来增加网络深度,当深度推进到16-19层时,网络性能显著提升。
1.引言
卷积神经网络(ConvNets)在大规模图像/视频识别中取得了显著成效,这主要归功于:大型公共图像存储库、高性能的计算系统和深度视觉识别框架的应用。本文着眼于网络深度,固定网络参数,只增加卷积层数从而缓慢增加网络深度,以此实现网络结构的改进。
2.卷积神经网络配置
2.1 架构
训练过程中,网络输入为 224x224 RGB图像,唯一的预处理为:对每个像素减去在训练集上计算得到的平均RGB值(使得像素点 零均值分布)。图像通过一系列卷积层,卷积核大小设定为3x3(3x3是捕获上下左右、中心概念的最小核尺寸),本文还使用了1x1的卷积核,这可被视为:对输入的线性变换。另外本文还涉及spatial padding(空间填充)和spatial pooling(空间池化),空间填充目的在于在卷积后的图像保持原图像的空间分辨率,而池化则使用max-pooling,采样窗口大小设定为2x2,步长为2。共有5个max-pooling层(并非所有卷积层后都接pooling层)。
padding可理解为:在图像边缘补0,使得卷积后的图像与原图像大小相等,这也就是为什么后续A-E网络模型中,虽然卷积层数不同,但却可以连接相同的全连接层。但也有部分论文中,卷积会改变图像的大小。
所有隐层都使用ReLU,只有一种结构使用了本地响应归一化(Local Response Normalisation,LRN),但该种归一化在ILSVRC数据集上并未提高性能,且增加了内存消耗和计算时间,所以仅在A网络中添加了LRN,B-E网络结构中舍弃。
2.2 配置
文章所用到的所有结构如下表,A-E仅在深度有所区别。卷积层通道数很小,第一层为64,而后在每个max-pooling层后增加一倍,直到达到512后不再增加。这里想要理解层与层间的关系及每层的大小,关键在于理解padding和pooling操作。
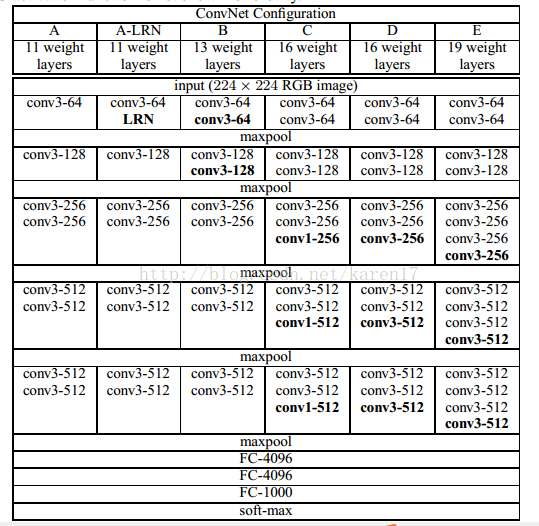
下表展示了每种网络结构的参数数目。

2.3 讨论
本文在整个网络中使用3x3卷积核对每个像素进行卷积,部分使用1x1的卷积核,卷积步长为1。
可以发现:两个3x3卷积核的有限感受野(effective receptive filed)为5x5,三个卷积核的有限感知野则为7x7。用三个3x3卷积层而非一个7x7层的目的在于:1)使决策函数更有区分性(more discriminative)2)减少参数量;假设三层3x3卷积层的输入、输出都有C个通道,则参数量为3(32C2)=27C2 ,而7x7的卷积层则需要72C2=49C2 个参数。
可以把三个3x3的卷积核看成是一个7x7卷积核的分解。举个例子:假如输入图像为10x10,通过三层3x3的卷积核则相应计算为:(10-3+1)x(10-3+1)=8x8,(8-3+1)x(8-3+1)=6x6, (6-3+1)x(6-3+1)=4x4。而通过一层7x7的卷积核的计算为:(10-7+1)x(10-7+1)=4x4,两种方式结果相同。
1x1的卷积核用来增加决策函数的非线性,在本实验中1x1卷积本质上是相同维度空间上的线性投影(输入、输出维度都相同)。
3 分类框架
3.1 训练
训练网络A时,随机初始化;而后训练更深的B-E结构时,用A网络训练得到的参数初始化前四个卷积层和最后三个全连接层,中间卷积层随机初始化。
训练图像大小:定义S为训练图像的最小边,图像的裁剪大小固定为224x224,如果S>>224,则会选择图像的一小部分。本文考虑了两种方法来设定S的大小:1)固定S=256,S=384;先在S=256时训练网络,再利用该网络得到的参数初始化S=384时的网络,然后进行训练,初始学习速率设定为10-3 2)设定S的范围[Smin, Smax] ,这里Smin=256, Smax=512,再随机选一个S,然后提取224x224的图像,用固定S=384时的参数对网络预训练。
3.2 测试
首先定义最小图像边界Q,Q不一定要与S相等(对每个S可以使用多个Q能提高性能);接着将全连接层转换为卷积层,第一全连接层转换为7x7卷积层,其他两个全连接层转换为1x1卷积层,然后将所得到的完全卷积网络应用于整个(未裁剪)图像;最后将原始和翻转图像的soft-max分类得分平均,从而得到最终得分。
3.3 实施细节
使用的语言/框架:C++ Caffe
4 分类实验
利用ILSVRC-2012数据集,该数据集包含1000个类别,分为训练集(1.3M)、验证集(50K)和测试集(100K),用top-1 和top-5 error来评价分类性能,前者是多类分类误差,即不正确分类图像的比例; 后者是ILSVRC中使用的主要评估标准。对于大多数实验,本文将验证集当做测试集。
4.1 单一评估
对于固定S,令Q=S进行测试;对于变动S∈[Smin, Smax] ,令Q= 0.5(Smin+Smax) 。实验结果如下表所示。
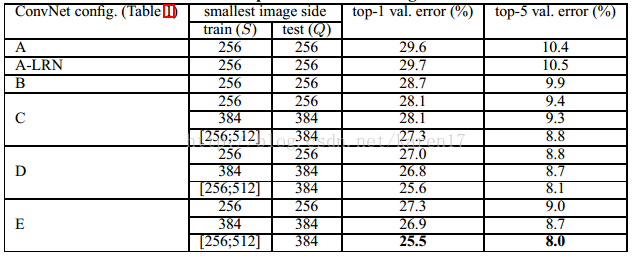
观察结果发现:
1)使用本地响应正则化(A-LRN网络),较普通的A网络结构并未提高性能,所以对B-E的结构不再使用;
2)随着深度增加,预测误差降低;另外结构C比D性能较差,这表明,增加非线性操作(1x1卷积)能提升性能;同时,本文还将B结构中的2层3x3卷积层替换为单层5x5卷积层,但top-1错误率比表格中结果高了7%。
3)S∈[256,512]时的结果比固定S性能较优,这证实了通过缩放抖动进行的训练集增加确实有效。
4.2 多尺度评估
评估S对性能的影响,即在同一S下变换Q值,再平均得分。若S与Q相差较大,则会导致性能下降,因此本文采取两种方式设定S和Q值:
1)对于固定S,Q={S-32, S, S+ 32} ;
2)对于变动S∈[Smin;Smax] ,Q={Smin,0.5(Smin+Smax), Smax} 。测试结果如下表。
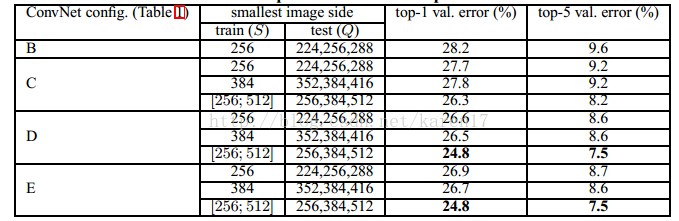
结果表明:在测试过程中使用尺度抖动(scale jittering)能提高性能。
4.3 multi-crop 评估
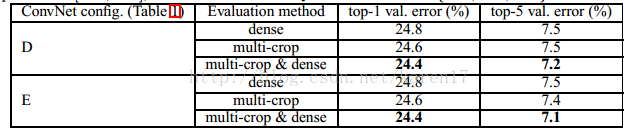
后续即为本文实验结果与当前先进模型所得到结果的对比。
5 总结
本文的结果证明了深度在机器视觉中的重要性。














 11万+
11万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









