









代码地址:
https://github.com/gzhcv/ThreeLayerNet
1 目的
把推导的过程自己走一遍,以便觉察到自己存在的理解缺口。写三层神经网络是一是为了清楚每层梯度与哪些量有关,二是为了需要的时候能够在框架上添加新层。
2 公式推导
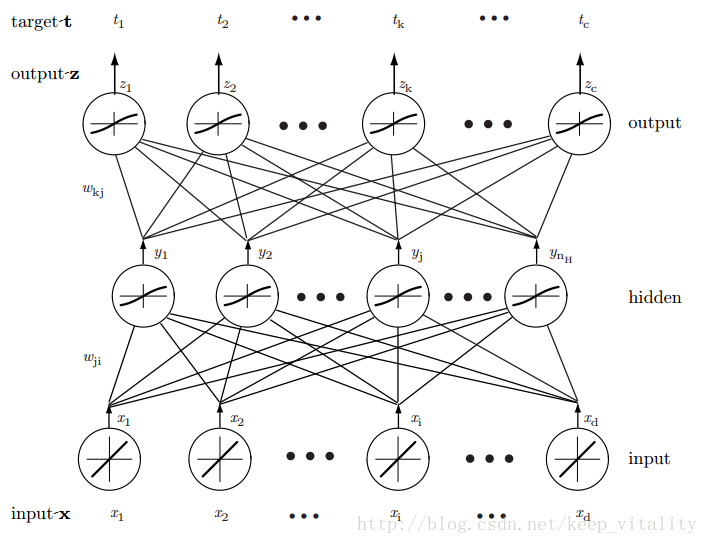
一个的三层全连接神经网络(这里把输入层也算作一层)。注意这里省略了偏置b,以下推导也不考虑偏置b。
符号约定
i, j, k 分别表示输入层单元,隐含层单元,输出层单元的索引。
x, y, z 分别表示输入层单元,隐含层,输出层单元的激活值。
net 表示每层单元未激活的值。
t 表示期望输出值
w 权重,有两个下标,左边的下标表示前一层单元的索引,右边的下标表示后一层(靠近输入层)单元的索引 以隐含层为例,写出该层单元的未激活值和激活值(向量默认为列向量)。
上式中 f 是激活函数。同样的写出输出层单元的未激活值和激活值。
注意,隐含层的激活函数与输出层的激活函数不一定相同,这里图示以sigmoid函数为例。然后目标函数以平方误差准则函数为例。
上式中 w 表示网络中的所有权值。权值的优化采用反向传播算法。
以上迭代更新参数过程大家都很熟悉了。现在进入重点,求目标函数对权重的梯度。先看对“隐层到输出层权重”的偏导。
这里 wkj 只用于计算 netk 的值,所以链式求导只有这一项,而常用的卷积神经网络是权值共享,那里会涉及到多个单元的求和。然后 δk 表示单元k的敏感度,度量了目标函数值对单元k值变化的敏感程度(也就是导数的含义啦)。为什么要加这么个中间值来表示?后面我们会看到,用这个 δk 让我们表示后面层的梯度变得相当简洁。 δk 定义如下:
由式
(5)
,进一步表示为:
由式 (8) 和式 (3) ,得到对“隐层到输出层权重”偏导的最终形式
就是说, J 对 wkj 的偏导等于 k 单元的敏感度乘以
隐层单元的敏感度是它连接的全部单元所传回来的敏感度之和,每一项都是前一层单元的敏感度乘以连接权值乘以激活函数的导数。可以看出,如果权值初始化为0,那么隐层后面的所有梯度为0,便无法更新参数。下面继续写 J 对
3 代码
这里用python实现,模仿在cs231n课程里写的神经网络代码。通过定义一个三层全连接神经网络的类来实现;类的属性当然是权值和偏置了,模型的参数就这些;方法包括train(迭代n次更新参数)、loss(计算损失及相应的梯度)、predict(对输入进行预测)。
重点部分是计算梯度,值得说一下算梯度的代码实现。
W1, b1 = self.params['W1'], self.params['b1']
W2, b2 = self.params['W2'], self.params['b2']
N, D = X.shape
net_j = X.dot(W1) + b1
y_j = 1 / (1+np.exp(-net_j))
net_k = np.dot(y_j, W2) + b2
z_k = 1 / (1+np.exp(-net_k))
# Compute the loss
y_trueClass = np.zeros_like(z_k)
y_trueClass[np.arange(N), y] = 1.0
loss = np.sum( np.power(y_trueClass - z_k,2) ) / N
# Backward pass: compute gradients
grads = {}
dz_dnetk = z_k*(1-z_k)
dL_dnetk = (z_k-y_trueClass) * dz_dnetk
grads['W2'] = np.dot(y_j.T, dL_dnetk ) / N
grads['b2'] = np.sum(dL_dnetk, axis=0) / N
dy_dnetj = y_j*(1-y_j)
dL_dnetj = np.dot(dL_dnetk, W2.T) * dy_dnetj
grads['W1'] = np.dot(X.T, dL_dnetj) / N
grads['b1'] = np.sum(dL_dnetj, axis=0) / N每层单元用的符号和上面推导是一样的。W2对应的是连接隐层和输出层的权值,
dL_dnetk对应的就是输出层单元的敏感度。代码里算的是一批样本的平均梯度,有疑惑的可以下载代码看详细介绍。写的时候要回想每个变量的size比较麻烦,其实记住一行对应一个样本就行了,所以对
wkj
的偏导就等于向量dL_dnetk[:,k]与向量y_j[:,j]的内积除N(样本数)。注意,代码里权值W2[m,n]连接的是隐层的第m个单元和输出层的第n个单元(不好意思,这里符号不能和之前推导契合,也就是说第一个索引对应隐层,第二个索引对应输出层),所以W2[m,n] = y_j[:,m].T * dL_dnetk[:,n] / N,扩展到W2就得到以上代码。 然后再说一下dL_dnetj,dL_dnetj[m,n]对应的是第m个样本,隐层第n个单元的敏感度,W2[n,:]表示隐层第n个单元相关的所有权值,dL_dnetk[m,:]表示第m个样本对应的输出层单元的敏感度,所以dL_dnetj[m,n]是向量W2[n,:]与向量dL_dnetk[m,:]的内积,所以dL_dnetj[m,n]= dL_dnetk[m,:] * W2[n,:].T
4 分析
我们看一下,如果w都初始化为1,会产生什么后果。首先前向过程,由于是全连接网络,所以隐层单元的值都相等,输出层单元的值也都相等。然后反向过程,我们知道隐层与输出层连接的权值的偏导是输出层单元的敏感度乘隐层单元的激活值,所以连接了同一输出单元的权值的偏导是相等的(隐层单元的激活值都相等);再看隐层单元的敏感度,由式 (12) 可看出隐层单元的敏感度都相等;最后看连接输入层与隐层的权值的偏导,由式 (13) 可看出,连接了同一输入单元的权值的偏导是相等的,由式 (1) 可知隐层单元的值在权值更新的过程中一直都相等,这等价于隐层只有一个神经元。所以,大量权值重复和隐层等价于单个神经元的事实,严重削弱了网络的表达能力,对代码里生成的数据做实验也可看出效果很差。
5 小结
以前看到反向传播算法的推导一大堆符号,都没心思看了。但现在仔细推一遍发现还是很好理解的,每个公式的含义都很直观,能清晰的看到权值与哪些量有关。














 7178
7178











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









