







该篇文章发表于SIGGRAPH2018,作者HE ZHANG † , University of Edinburgh、SEBASTIAN STARKE , University of Edinburgh
TAKU KOMURA, University of Edinburgh、JUN SAITO, Adobe Research (话说SEBASTIAN STARKE似乎长的很帅 - - 。咳)
本篇博客是理解的上部分,重点在翻译(人翻非机翻)。下会给出更多个人理解。
四足动物运动控制中的模态自适应神经网络
四足动物运动包括不同的步态,比如行走,一步(踱步?)(pace),快跑(trot),慢跑(canter)和类似于跳,坐,转弯,停顿(idling)等姿态。对这些运动数据使用现存的数据驱动的角色控制框架需要大量的数据预处理工作,比如标记动作和校准(alignment)。在这篇论文中,我们提出了一个崭新的网络结构,这个结构被称为MANN---四足动物运动控制的模态自适应神经网络。这个系统由动作预测网络motion prediction network和门网络gating network组成。在每一帧画面中,动作预测网络负责计算角色在给定上一帧状态和用户提供的控制信号情况下的当前帧的状态。而门网络,通过选择和混合所谓的针对每一个特定动作的专家权重expert weights,动态地更新动作预测网络的权重。由于灵活性的不断增长,这个系统可以以端对端的形式,通过无结构的动作捕获的数据,持续学习一系列周期性和非周期性的动作的专家权重(amazing!)。除此以外,用户无需对不同的步态进行相位标记。我们证明了这种架构适合于编码多模态的四足动物运动,事实生成鲜活地运动。
CCS概念:计算方法->动作捕获;神经网络;
关键词:运动;动作;人类运动;角色动画;角色控制;深度学习
1 介绍
四足动物动画是计算机动画中一个未解决的关键问题。它不仅同计算机游戏和电影的实现有关,也是机器人学中一个具有挑战性的主题。当动画化四足动物时,动画制作者必须通过针对性的训练来设计出不同的复杂动作。由于四足运动的多模态性,这种复杂性是与生俱来的。比如说,躯干和四肢在不同的动作(走,踱,快跑,慢跑,飞奔)中都会展现出不同的运动和相位样式。如下图Fig2
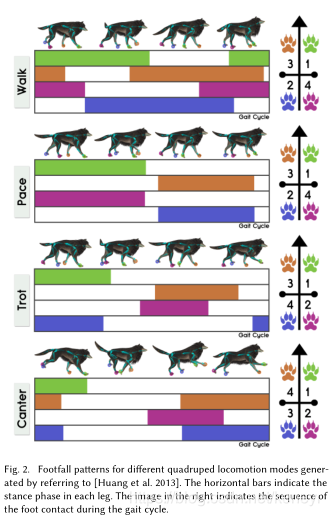
目前还没有在数据驱动方式下的系统性构建四足动物动作控制器的工作。在控制数据获取中,四足动物不能像人类一样被引导,这也是一大难题。因此,被捕获的数据经常是无序的(less structured),连续动作也通常是随机的。在使用这些数据设计角色控制器时,操作者需要从这些数据中手动或者半自动的提出步态循环(gait cycles)和过渡(transitions),把它们联系(stitch)在一起,并且调整动作树和有限状态机的参数。
在为拥有明确循环规律的两足运动生成高质量的动画的工作中,基于神经网络的动作控制最近取得了成功(也就是2017年的人的PFNN)。然而,单纯地将同样的框架应用于四足动物模型并没有取得较好效果,因为对于具有明显不同的脚步模式的步态,同时为四只腿在步态过渡时定义单一的相位是几乎不可能的(because defining single phase for all four legs is not possible in the transition between gaits with very distinct footfall patterns)。这也使得对具有复杂的步态转换的无组织的四足动物运动数据手动标记相位变得不具有实践性。
在这篇论文中,我们提出了一个新的网络结构MANN,它可以从大量的无组织四足动物动作捕获数据中学习动作控制。这个系统由动作预测网络和门网络组成。在每一帧画面中,动作预测网络负责计算角色在给定上一帧状态和用户提供的控制信号情况下的当前帧的状态。而门网络,通过选择和混合所谓的针对每一个特定动作的专家权重,动态地更新动作预测网络的权重。这个框架使得系统变得很灵活,系统可以在非周期性动作和周期性的无标记步态类型动作中学习连续特征。这个框架可以使用户从单调乏味且苦难的相位标记(phase labeling)阶段(无序的四足动物动作捕获数据需要按照时间线排列)中释放出来。特别的是,我们的模型不需要对不同的(对人类来说难以区分的)步态进行单一标记分类,因此可以避免数据处理过程中的错误标记。
这篇文章的贡献被概括为以下几个方面:
- 第一个系统性的方法-----构造数据驱动的能生成高质量的拥有复杂动作模式和转换的动画的四足角色控制器。
- 一个新的端对端的神经网络结构-----能从无序四足动物动作捕获数据中学习并且不需要相位和步态的标记。
- 自己的方法和现存的其他方法进行详细的比较和分析。
2 相关工作
四足动物动作生成经常通过程序化建模和基于物理的控制来完成。程序化动画在动画化有腿的虚拟生物时相当有用。Kry实用模型分析方法来动画化四足动物。虽然这些方法能够生成有趣的稳定的步态循环,在对用户输入进行快速回应并生成细微和真实的动作时仍有一些困难,因为一些物理规则比如动量守恒和地面反作用力会对动作有较大影响。模拟这些动作需要使用基于物理的动作或者数据驱动的技术。
在接下来的部分,我们会先回顾基于物理的四足控制,然后是数据驱动技术,后者也能被应用到四足动作生成中。最后,我们会简单回顾多专家模型(mixture of experts),也正是该概念激发了我们的方法。
2.1基于物理的四足控制器
基于物理的控制器在生成动态的行为(动物遵循能量最小化和动量守恒时)效果很好。这种策略能被分为基于轨迹的方法(在满足物理特性时达到最优化)和基于扭转力的方法。
基于轨迹的方法:大量轨迹优化技术被用在人类动作生成中,其中一些方法也被用在四足动物动作生成中。W和P通过最优化扭转力和步态循环中约束条件的组合的方式计算不同类型的的动物的动作(WandP compute the motion of various types of animals including quadrupeds by optimizing an objective function composed of the torques and constraint terms over cyclic gaits)。W扩展了这一方法,并用来预测外表已知而动作未知的动物的行动。这些方法不能应用到在线应用上。L和P以类似物理的方式让狗的运动适应动态改变的地形。这种方法对于使小数量的典型动作适应不同环境很有用,但需要一系列动作作为先导,这个方法发展出了由数据驱动的方法。
基于扭转力的方法:基于扭转力的控制器一直被应用于人类角色和四足动物角色。考虑到角色需要在保持平衡的同时表现出理想的动作状态,设计这样的控制器并不容易。R和H设计出了小跑,反射和飞奔步态的控制策略。V和P使用速度作为矩阵最优化控制图的参数来控制一个猫的模型(VP optimizes the parameters of a control graph to control a cat model using speed as the primary metric)。C为四足动物设计出一个细节控制器,通过最优化PD控制器在满足约束的同时来模仿视频中的动作,从而模拟出大量的动作包括走,小跑,慢跑,飞奔【2011】。P在控制四足动物模型时应用了强化学习以适应不同的2d地面状态【2015】。在高维状态空间设计一个稳定的控制器是一个很难的问题,因此低维空间特征需要被手动调控来保持控制器的稳定。P通过对自动计算出的特征空间应用深度强化学习解决了这一问题。这个方法又被提升于3d环境和应用到二足动物角色上【2016】。
基于物理的控制器在设计动力学可行的动作时非常有用,虽然一些使得动作更真实的小细节可能会被忽略,因为从简单的反馈中描述它们太过困难了。对抗训练是一个可能会克服这一难题的方向。
2.2数据驱动的角色控制
与基于物理的动画相对的是数据驱动的动画技术,使用捕获的运动数据来进行交互式的角色控制。数据结构比如动作图(motion graphs),被用来在无序的动作捕获数据中生成连续角色动作。动作图的连通性影响了被控制的角色的反应度,计算机游戏和其他交互应用经常使用更简单的结构,比如有限状态机(finite state machine)它的连通性更加明显,并且序列性动作可以预测。
在本节剩余的部分,我们回顾早期的应用到动作合成的机器学习策略,从动态角度模拟动作的时间序列模型和基于深度学习策略的近期方法。
基于传统机器学习技术的动作合成:为了改善不同动作的过渡并且提升输出运动的普适性,这个系统最好是生成全新的动作而不是简单的模仿已有的数据。基于深度学习的不同技术,比如说K-Nearnest Neighbours(KNN),主成分分析(PCA),径向基数函数(RBF),强化学习,高斯处理(GP)都被用来实现这个目标。
大部分基于传统机器学习技术的方法都存在扩展性问题(scalability issues):它们首先需要大量的数据预处理,比如说动作的分类与排列(classification and alignment)。KNN要求保留所有的动作数据,基于核的方法比如径向基数函数(RBF)和高斯处理(GP)要求大量的存储空间和立方级计算时间,基于PCA的方法在高维度问题表现很好,但是需要局部结构来应对时间序列模型,这也意味着需要大量的预处理。
时间序列模型:时间序列模型根据前一帧的动作来预测当前帧,这样的模型对实时应用比如计算机游戏很有用。和运动插值类似,基于线性回归和基于核的方法被提了出来。线性模型很简单,但在处理非线性时存在问题。X通过使用专家门(expert gates)解决了这个问题,虽然他们的方法需要预定义不同种类的专家(though their method requires predefining the classes of each experts)而我们在研究中解决了这个问题。基于核的方法能够在模拟非线性动作,但是训练好的模型只能表达特定的动作。动作域需要预存原始数据,并且在运行时用KNN搜索,这也限制了它的可扩展性(which limits the scalability)。
通过神经网络学习角色动作:神经网络由于其可扩展性和高效表现获得了关注。神经网络能够从大量的数据中学习,并压缩数据大小。T表示人类动作捕获数据可以在cRBM中学习,虽然由于帧取样它存在一些噪声。对学习人类动作等时间序列来说,能预测未来姿态的递归神经网络RNN很是吸引人,但是也存在收敛问题(but are known to suffer from converging to an average pose)。L通过连接网络预测和未来的输入,使得生成的动作回归到原始的数据,从而解决了这个问题【2017 】。这些工作的重心在于重建时间系列数据,而且它们不接收多余的控制信号。它们如何根据用户指令插入不同的动作间仍然有待检测。
H使用卷积神经网络和学习时间滤波器来表达动作。他们描述CNN的能力来绘制高级用户对角色动作的指令。H提出一个实时框架,相位神经网络PFNN,将手柄的输入表现为角色的动作。相同技术在四足动物的应用遭遇了由四足动物动作复杂度和步态类型,阶段标记引起的难关。最重要的是,他们把阶段作为参数用来按时间线排列动作,这样他们就不会在错误的时间组合动作,这种解决方法只有当脚和地面持续接触的时候才有用。对四足动物来说,这种模式会在不同方式间剧烈变化,因此造成失真,我们将会在第8节进行展示。(Most importantly,they introduce the phase as a parameter to align the locomotion along the timeline,such that they do not blend motion at the wrong timing.This is only possible if the way the feet contact the ground is consistent. For quadrupeds, this pattern can drastically change between modes, and thus can result in artifacts.)
2.3混合专家(Mixture of Experts)
混合专家模式是一个传统的机器学习方法,大量的experts被用来处理不同地带的输入。一个门网络决定了对于给定的输入,哪些专家会被使用。训练完成后,这些专家会专用于被门网络分配的下降维度。我们让读者参考Y。它和深度学习结构的组合显示出极好的前景。我们的结构和混合专家模式有相似处,因为我们也使用了门功能,虽然我们的组合发生在特征层,而MOE发生的发现在输出层。
3 系统总览
我们的系统是一个时间系列模型,可以在给定x---前一帧的角色状态和控制信号的情况下预测y---当前帧的角色的状态。为了在四足动物这一角色上实现这个目标,我们提出了一个新的神经网络结构MANN,模态适应性神经网络(第6节)。当前帧的动作由动作预测网络计算,该网络的权重由门网络进行动态计算(6.1,6.2)。这个门网络接收动作的特征![]() ,这是x的子集,然后计算专家权重的混合系数,每个专家权重都针对特定动作进行过训练(The gating network receives a motion feature
,这是x的子集,然后计算专家权重的混合系数,每个专家权重都针对特定动作进行过训练(The gating network receives a motion feature ![]() , which is a subset of x,and computes the blending coefficients of the expert weights)。如下图Fig3
, which is a subset of x,and computes the blending coefficients of the expert weights)。如下图Fig3
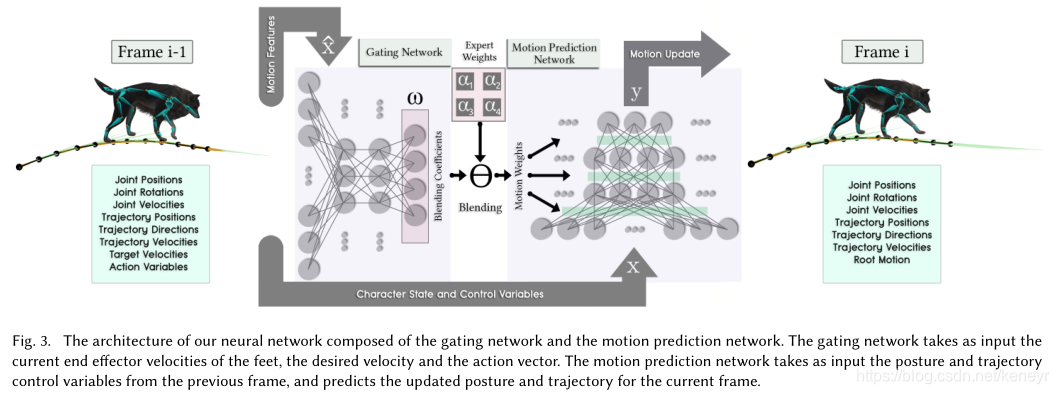
为了准备训练集,我们对狗动作捕获的数据集进行预处理,并且增加标签,设置输入和输出矩阵(5)。在训练时,整个网络使用准备好的训练集进行端对端训练(7)。运行时,这个系统实时得使用先前状态和用户提供的动作信号来动画角色(8)。
4 数据预处理
在这一部分我们描述动作捕获和动作分类阶段,并且展示如何分解数据。
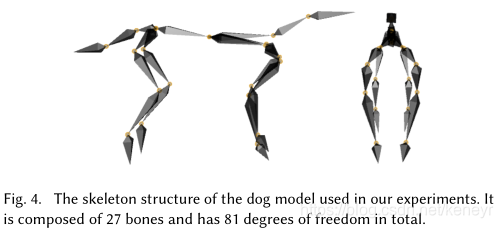
狗动作捕获。我们的动作捕获数据包括30分钟的由不同的动作模态(various locomotion modes)比如走,踱步,快跑,慢跑等组成的无序狗动作捕获数据,也包含其他动作类型(other types of motions),包括坐,站,停,躺,跳。数据的大小由镜像加倍。由于捕获场所和设备的限制,所有的动作数据均捕获在一个平坦的地带。符合捕获数据的骨骼模型由27根骨头组成,身体有81自由度。如下Fig4
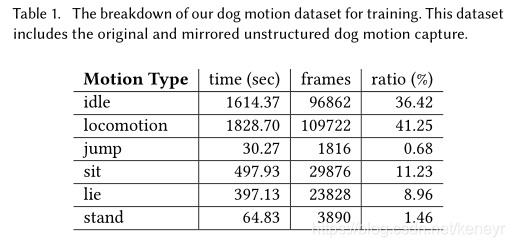
狗动作分类。这些动作最初被分为坐,站,停,躺,跳等所以用户可以在运行时根据这些标签来控制角色。这个过程是手动进行的,虽然自动分类也不困难。运动数据的分解率如下Table1
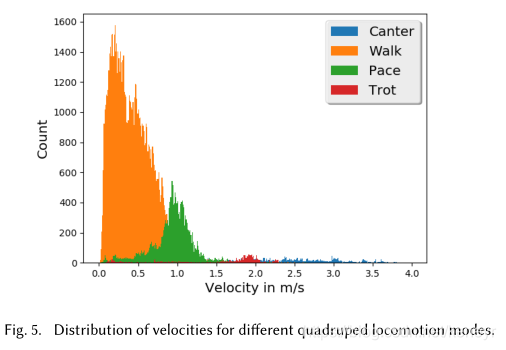
运动模式(模态)。在我们的文章中,我们主要研究四种不同类型的运动模式:走,踱步,小跑和慢跑。虽然我们的系统不需要在运行时为了控制角色而对运动模式进行标记,我们分析了数据中模式的分布情况。由于复杂的过渡和有歧义的动作,数据的分类是一个困难的过程。我们首先基于速度分布对动作进行了粗略的分类,然后将它们进行手动分类。最终速度和模式种类的分解/组合如图Fig5。相关性同C提出的模型吻合。
5 输入和输出格式
系统的输入数据与输出数据的格式采用PFNN和MOTION MATCHING中使用的格式。数据由地面轨迹转换和过去状态以及未来状态的速度,在这些帧中的运动类型的标签,身体关节的转换和目前状态的速度组成(The data is composed of the ground trajectory transformations and velocities in the past and future states, the labels of the action type at those frames, and the body joint transformations and velocities of the current state)。更特别地是,对于每一帧,我们统一地取包含了1s前和1s后的另外11帧为样本。在动作的12帧画面中,我们提取了特征---包括角色(相对于身体局部转换)的位置、旋转、和速度。所谓身体局部转换,在我们的系统中被叫做根变换,是投影到地面上并且旋转是面向角色的朝向,根变换也代表了当前帧的轨迹变换。我们把十二帧的动作标签作为状态矢量的一部分。最终,所有的轨迹和身体关节变化都根据根轨迹转换计算了出来,每一帧的速度由当前特定状态的未来轨迹长度计算出(we extract features including the character positions, rotations and velocities relative to the body's local transformation, which is projected onto the ground with its rotation facing in the character's forward direction.We call this the root transformation of our system, which also represents the trajectory transformation for the current frame.We then include the action labels at those 12 frames to be part of the state vector.Finally, all trajectory and body joint transformations are computed relative to the root trajectory transformation. The desired velocity of each frame is simply calculated by the length of the future trajectory at this particular state.)
帧i的输入矢量![]()
![]() 中包括了:
中包括了:![]() 当前状态i下t采样点(本文中是12个采样点)的用户预测的在2D水平板上的轨迹位置,
当前状态i下t采样点(本文中是12个采样点)的用户预测的在2D水平板上的轨迹位置,![]() 当前状态i下轨迹朝向,
当前状态i下轨迹朝向,![]() 当前状态i下轨迹速度,
当前状态i下轨迹速度,![]() 理想的当前状态i下的轨迹速度,
理想的当前状态i下的轨迹速度,![]() 轨迹上采样点的one-hot角色运动类型向量,
轨迹上采样点的one-hot角色运动类型向量,![]()
![]() 前一状态关节的位置角度和速度,j表示关节个数,本文中是27。除了PFNN中使用的变量,这篇文章也使用了关节旋转作为网络的输入,而不是仅用来输出层,故可以快速生成更敏锐的动作。
前一状态关节的位置角度和速度,j表示关节个数,本文中是27。除了PFNN中使用的变量,这篇文章也使用了关节旋转作为网络的输入,而不是仅用来输出层,故可以快速生成更敏锐的动作。
相似的,输出![]()
![]() 包括了:
包括了:![]() 对下一个状态预测的轨迹位置,方向,速度,
对下一个状态预测的轨迹位置,方向,速度,![]() 当前状态的关节的位置角度和速度,
当前状态的关节的位置角度和速度,![]()
![]() are the root translational x and z velocities relative to the previous frame which define the local transformation into the currentframe,
are the root translational x and z velocities relative to the previous frame which define the local transformation into the currentframe,![]() is the corresponding root angular velocity in the 2D-horizontal plane。这和PFNN的数据预准备相似,虽然我们的系统不输出脚接触和相位变化,但是包括了轨迹速度来获得更好的控制性。
is the corresponding root angular velocity in the 2D-horizontal plane。这和PFNN的数据预准备相似,虽然我们的系统不输出脚接触和相位变化,但是包括了轨迹速度来获得更好的控制性。还有,我们用相对的forward和upward向量来代表关节旋转,为了防止神经网络训练中出现四元数插值问题。这些都会从运动数据的原始四元数中提取,在运行的时候为了生成运动会变回来的。(Also,we represent the joint rotations by the relative forward and upward vectors in orde rto avoid quaternion interpolation issues by the neural network during training. Those are obtained from the original quaternions in the motion capture, and transformed back for generating the motion during runtime.)
6 四足控制的模态自适应神经网络
在这一部分,我们将介绍我们的网络结构。我们先描述动作预测网络后描述门网络。
6.1动作预测网络
动作预测网络是一个三层的神经网络,它可以接收角色的上一状态然后输出的数据是y的格式。
![]()
![]()
![]()
![]()
h是隐藏神经元数量,本文中是512.
神经网络的权重![]() 通过组合K个专家权重
通过组合K个专家权重![]() 得出
得出![]() 。K是一个能够根据复杂度和训练集的大小调整的参数,
。K是一个能够根据复杂度和训练集的大小调整的参数,![]() 是由门网络计算出的组合系数(6.2)。我们发现K=4时足够生成高质量的动作。
是由门网络计算出的组合系数(6.2)。我们发现K=4时足够生成高质量的动作。
6.2门网络
门网络是一个三层神经网络,用来在给定输入数据x的情况下计算组合系数![]() 。
。
![]()
![]() 是x的子集,is a subset of x that are the foot end effector velocities, the current action variables and the desired velocity of the character.
是x的子集,is a subset of x that are the foot end effector velocities, the current action variables and the desired velocity of the character.
![]()
![]()
h ′是隐藏层单元的数量,这里设置为32。σ(·)是一个softmax操作器,能够均一化输入让输入的总和是1,这个在将来的线性融合有用。
我们测试了不同的输入,并且发现这些特征都单独能产生最好的结果。理想的情况下,这个网络可以学习输入的有用信息特征,由于我们的训练集很小这可能会变得很困难。同时,我们观察得出使用动作变量和理想的速度能帮助提高控制度和角色的反应(We have tested various other inputs including the full x , the end effectorpositions,andthecombinationoftheirpositionandvelocity,as well as the rotations, and found those features alone to clearly produce the best results. This could be due to the strong correlation of the feet velocity with the locomotion phase, resulting in an effect similar to the phase function in [Holden et al . 2017], which helps to avoid blending between motions of different phases. Ideally, the network could learn the informative features from the input, though this could be difficult due to our relatively small amount of training data as listed in our experiments in Section 8. Meanwhile, we observed that the using the action variables and the desired velocity helps to improve the controllability and responsiveness of the character.)
7 训练
整个网络端对端的使用处理过的动作捕获数据进行训练。每帧的x和y都表示成矩阵的形式![]() 作为输入数据。这些值进行过平均和方差的变化所以它们是正则化的。由于小跑和慢跑的循环有限,我们复制了这些动作的数据11次,使得他们在运行时表现更好。
作为输入数据。这些值进行过平均和方差的变化所以它们是正则化的。由于小跑和慢跑的循环有限,我们复制了这些动作的数据11次,使得他们在运行时表现更好。
训练我们的网络的目的是为了对于给定的输入X,我们能输出相应的变量Y,这是一个典型的回归任务。损失方程是预测输出和实际情况间的均方误差。
![]()
我们使用随机梯度下降算法with warm restart technique AdamWR,这个算法能够自动计算出损失函数的梯度。这个模型在tensorflow中实现。关于训练参数,这里我直接把这段给摘抄过来。

8 过程和结果
在这个部分,我们首先描述在运行时,角色控制过程,然后展示我们的控制结果。
运行控制:这个系统在U3D平台实现,在Intel Core i7 CPU单线程运行神经网络每帧需要~2ms,并且用了Eigen库。使用8个专家权重时内存占用为~22MB。这个角色能够被离散和连续的控制信号控制。通过按和one hot 向量元素有关的按键,期望的动作,比如说坐,站,停顿,躺下,跳跃和移动就会发生。(By selecting the key that corresponds to the element of the one hot vector, the desired action, which is either of sit,stand,idle,lie,jump and move, is launched.)。角色的速度,也包含在控制参数里面,是用特定的箭头来表示的,可以通过按下相关按键来增加、插值前向,后向,左方,右方的速度。运动的朝向是通过两个按键来控制的,其实就是Q和R,这两个按键也控制左转和右转。目标速度和方向都是通过平滑地插值,最终用来预测用户想要达到的未来轨迹。轨迹的曲线是用指数加权偏差值来推断,该偏差值定义未来轨迹的最大长度,然后以m/s为单位为角色提供理想速度。这也导致了平滑的轨迹,这对于神经网络的输入来讲非常重要,因为可以通过尝试像原始运动捕获数据中那样逼真的轨迹来实现良好的运动.(which is crucial for the input of the neural network to achieve good looking motion by trying to resemble realistic trajectories as in the original motion capture data.)(平滑的轨迹是很重要的)
运行结果:不同的步态包括走路,踱步,跑都通过设置不同的速度0.5m/s(walk),1.1m/s(pace),1.9m/s(trot),3.3m/s(canter)完美的生成。通过逐渐地改变速度也能生成平滑的转换。每一种动作都能快速的对方向和速度输入做出响应,虽然一些步态不包括转向动作。这意味着神经网络可以很好的生成不同步态间的过渡动作。坐,躺。站和跳等动作也成功实现,虽然有一点延迟。这说明网络能够学会特定动作在哪个状态要执行。如图Fig1

最终,我们设置了一个角色需要在不平稳地形移动的环境。如下Fig7。我们没有像2017年那样训练角色走过不同的地形,而是对角色简单地应用了CCD逆向动力学。爪子的位置和效应器的位置被后处理,这样它们除了产生的运动之外还有偏移地形的高度,脊关节也相对周围高度同时更新。这是为了避免在上下行走时四肢出界,从而产生更加自然的动作。

9 评估
我们通过与已有方法在动作质量,滑步真实性,腿的僵硬度和反应等方面进行比较,评估了我们的系统。我们也检测了专家权重,通过在运动的时候不激活分析了它们的实用性。
同其余框架的比较:我们比较了我们的系统和其余神经网络的表现,比如说和vanilla feed forward 神经网络还有PFNN进行比较(半自动相位标记)。需要注意的是,所有其余的框架输入输出都保持和我们的方法相同,并且每个方法的状态向量里都不包含足的接触信息。为了公平的比较,我们让vanilla 神经网络和PFNN和用了4个专家权重的MANN一样,层的数量和参数都一致。因此,vanilla网络在隐藏层中有2048个单元,PFNN有4个控制点,每个控制点的隐藏层里都有512个单元,总共是(4*512个)。同时,我们也展示出了拥有8个专家权重的MANN,并且列出了原始捕获数据的ground truth 值。
vanilla正反总是存在不合理的组合,导致模糊的运动和高频成分的丢失。甚至在连续行走和踱步循环中这种失真都表现的很明显,而数据本身已经很充足。在进行转弯动作或跳跃后降落时,这种滑步和僵硬腿的失真尤为明显。
同PFNN相比较,我们的系统表现得更好,并且我们不需要任何阶段标签(相位标签)。为了测试PFNN,阶段标签被添加到狗运动数据中。这些阶段根据前两条腿的速度表来定义,并通过优化技术计算和排列。PFNN一般情况下表现很好,虽然后腿经常表现的很僵硬和不自然,并且也有滑步现象存在。这可能是由于很难定义一个可以很好的校准不同步态类型的连续相位函数。由于我们根据前腿的速度定义不同阶段,失真在后退表现得更明显。
在双腿运动中,以足关联模式为基础更容易校准动作,比如说走和跑。然而,这样一个简单的规则是很难应用到四腿动物中,另一方面,为了组合这些特征来最小化损失函数,门网络将有更高度的自由度。
滑步现象:我们也比较了滑步的现象。如下Table2。如果位置的高度h在域H=2.5cm内,那么足的速度就会被加上。水平面板上的速度v将会通过指数插值公式![]() 来评估运动期间的滑行量,其中指数在0~1之间。
来评估运动期间的滑行量,其中指数在0~1之间。
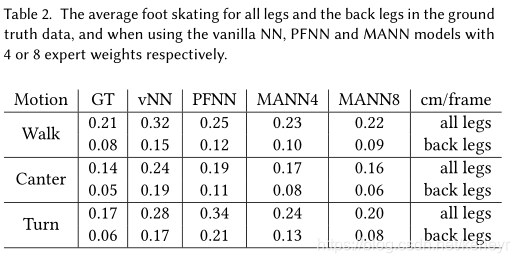
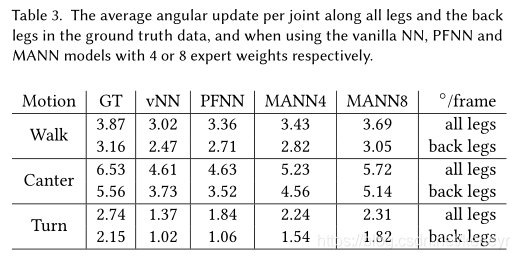
腿的僵硬程度:在PFNN中,滑步是由后退的僵硬导致的,由于前腿运动后计算出来的相位下后退运动的融合造成。为了定量评估这种将硬度,我们计算平均每次所有腿和后腿的关节角度,如下Table3。可以看到,与MANN相比,vanilla和PFNN腿的运动要小得多,尤其是后腿。
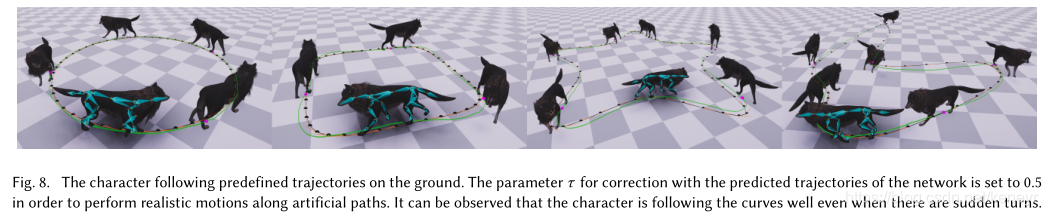
反应灵敏度:我们最终评估了我们方法的相应能力和路径跟踪精度。 我们创建了几个预定义路径,并指示角色在不同模式下follow它们。 为了使角色沿着轨迹运动,我们使用混合参数![]() ,其在期望轨迹
,其在期望轨迹![]() 的未来点以及我们网络输出的矫正轨迹
的未来点以及我们网络输出的矫正轨迹![]() 之间插值,以获得用于该轨迹的输入轨迹
之间插值,以获得用于该轨迹的输入轨迹![]() 动作更新。 该混合的公式为:
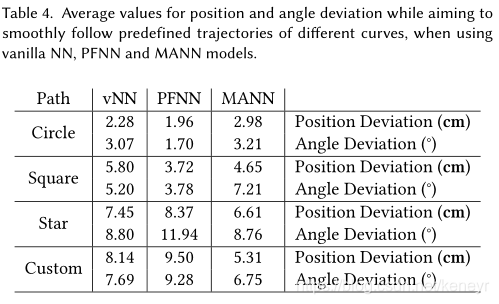
动作更新。 该混合的公式为:![]() 由角色产生的轨迹如Fig8所示。然后,考虑到它们的根变换,我们测量了期望轨迹与角色的实际轨迹之间的差异。(见Table4)。 可以观察到角色很好地跟随路径并且平均距离很低。
由角色产生的轨迹如Fig8所示。然后,考虑到它们的根变换,我们测量了期望轨迹与角色的实际轨迹之间的差异。(见Table4)。 可以观察到角色很好地跟随路径并且平均距离很低。
网络到底学了什么?为了检验这种情况,我们绘制了混合系数ω的轮廓---当角色在Fig9中执行不同类型的动作和运动模式时,K = 4和8的专家权重。可以观察到权重值是相同的循环低速运动(参见Fig9,第二个底部,底部,上部行),使得门控网络的功能与PFNN中的相位功能相同。专家权重对应紫线的时期随着运动速度的增加,它变得活跃,变得更长和恒定,而其他的在这种情况下往往变得不活跃。这意味着这些专家权重训练负责快速运动,跳跃运动,而其他可能负责合成比较慢的运动。特别是,通过选择性地禁用混合系数的单个维度,我们观察到角色不再能够执行某些动作,例如单一类型的运动模式,转动或跳跃。Table5列出了我们对具有8个训练混合系数的学习网络的观察结果。虽然它们中的大多数明显有助于整体运动质量,但有些对特定的动作或模式负有全部责任。特别是对于向左或向右转动,可以观察到转向相反方向仍然大部分或甚至完全不受影响。


专家不平衡:以前类似架构中报告过一个问题。B和E还有S的论文中,是一小集合experts,倾向于通过门控网络获得更高的权重。随着受欢迎的experts将更加迅速地接受培训,这种失衡将会增加。实际上,我们在应用原始mixture of experts架构时观察到这种现象。在我们的设置中,我们准备了四个experts,并使用门控网络混合输出:只有一个专家训练有素而不削弱其他experts。以前在这方面的工作通过强加限制来应对这个问题,或通过对造成这种不平衡的损失实施额外处罚。对于具有少量控制点的我们的系统来说似乎不需要这样的惩罚,因为它们的使用变得相对平衡,并且系统在动画角色方面表现良好。
10 讨论
我们讨论了模型的优化和局限性。
学习时间序列模型:时间序列数据是很难去学习的,通过在循环运动或者是非周期运动时间线上不同相位融合姿态导致收敛到平均姿态,而且输出动作也容易变得过分平滑(often converging to a average poses by blending posed at different phases in cyclic motions, or timing in acyclic motions. Also, the output motions tend to be smoothed out due to such averaging.)。虽然简单的前馈网络在样本充足的情况下也能完美插入,而在训练集较少的情况下,输出结果也会表现的过分平滑或者出现滑步失真。PFNN被用来在这种情况下生成较好的结果,因为PFNN在相位维度上校准运动数据,并且只在相同相位上融合运动数据。MANN也可以描述成PFNN的衍生物。控制点被训练来针对特定时刻的特定动作,并且激活也能被门网络在无监督状态进行调控。训练完成后,不好的插入情况能减少很多,因为这里几乎没有针对不同阶段的专家权重的组合。
稀疏数据集:深度神经网络在训练集少的情况下可能不能达到目的。具有较少样本的维度很容易被具有密集样本的维度影响。狗动作捕获数据能保持这样的分布直到捕获场所不重要。一个小时的动作捕获数据对人类数据来说并不算多,但对于四足数据来说已经很多了。在这种情况下,我们的结构可以很好的满足这种稀疏数据集。
局限性:我们的数据集局限于平坦地形,因此在高位置的跳跃不能生成。逆向动力学方法对简单的动作合成很有用,但不能生成更加动态的动作,比如跳上跳下一个盒子。因此我们不能像前人一样适应多种地形。扩充数据以生成这些结构的一个可能是应用基于物理的动画到生成训练数据中,其中角色符合动量守恒和弹跳效应,并且扩充这些数据。
11 未来工作
除了将我们的方法和基于物理的动画相结合外,这里还有几个有趣的研究方向。
一个方向是对不同大小和形态的四足动物的动作重定向。四足动物的动作捕捉并不直接,因此数据量通常很小,并且对于理想大小的体型的动作通常不容易得到。W提出了一个关于生成不同大小和骨架结构的四足动物的动作的优化策略,但是运动仅限于平面的正向运动,并且每个运动的重定向将是线下的过程。如果基于分解的神经域转换类型的方法能被应用将会很有趣,这样来从一个动物的丰富运动集和另一个动物的小样本运动集可以产生广泛的步态和运动变化。
另一个有趣的方向是计算生成运动的一半损失,并且使用这种损失来避免模糊问题。这已经在基于物理的环境和动作捕获数据的初步结果中研究过(没太看懂这句),但是交互式角色控制的框架还没有完成。
自动控制非玩家角色来和玩家控制角色进行交互或者和一个复杂环境中的动态障碍进行交互也是一个有趣的研究方向。一个可能是应用强化学习来决定框架的控制信号。
MANN被证明是强大的捕捉四足动物运动的多模型性质的工具。我们可能会探究这种结构对于具有高度多模态数据的其他机器学习任务时,是否普遍有效。
------------------------------------累死我了。。。要狗带了。。。。55555555555---------















 15万+
15万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











