







强烈推荐: 鸟窝 https://colobu.com/
百万 Go TCP 连接的思考: epoll方式减少资源占用
前几天 Eran Yanay 在 Gophercon Israel 分享了一个讲座:Going Infinite, handling 1M websockets connections in Go, 介绍了使用Go实现支持百万连接的websocket服务器,引起了很大的反响。事实上,相关的技术在2017年的一篇技术中已经介绍: A Million WebSockets and Go, 这篇2017年文章的作者Sergey Kamardin也就是 Eran Yanay 项目中使用的ws库的作者。
第一篇 百万 Go TCP 连接的思考: epoll方式减少资源占用
第二篇 百万 Go TCP 连接的思考2: 百万连接的吞吐率和延迟
第三篇 百万 Go TCP 连接的思考: 正常连接下的吞吐率和延迟
相关代码已发布到github上: 1m-go-tcp-server。
Sergey Kamardin 在 A Million WebSockets and Go 一文中介绍了epoll的使用(mailru/easygo,支持epoll on linux, kqueue onbsd, darwin), ws的zero copy的upgrade等技术。
Eran Yanay的分享中对epoll的处理做了简化,而且提供了docker测试的脚本,很方便的在单机上进行百万连接的测试。
2015年的时候我也曾作为百万连接的websocket的服务器的比较:使用四种框架分别实现百万websocket常连接的服务器 、七种WebSocket框架的性能比较。应该说,只要服务器硬件资源足够(内存和CPU), 实现百万连接的服务器并不是很难的事情,
操作系统会为每一个连接分配一定的内存空间外(主要是内部网络数据结构sk_buff的大小、连接的读写缓存,sof),虽然这些可以进行调优,但是如果想使用正常的操作系统的TCP/IP栈的话,这些是硬性的需求。刨去这些,不同的编程语言不同的框架的设计,甚至是不同的需求场景,都会极大的影响TCP服务器内存的占用和处理。
一般Go语言的TCP(和HTTP)的处理都是每一个连接启动一个goroutine去处理,因为我们被教导goroutine的不像thread, 它是很便宜的,可以在服务器上启动成千上万的goroutine。但是对于一百万的连接,这种goroutine-per-connection的模式就至少要启动一百万个goroutine,这对资源的消耗也是极大的。针对不同的操作系统和不同的Go版本,一个goroutine锁使用的最小的栈大小是2KB ~ 8 KB (go stack),如果在每个goroutine中在分配byte buffer用以从连接中读写数据,几十G的内存轻轻松松就分配出去了。
所以Eran Yanay使用epoll的方式代替goroutine-per-connection的模式,使用一个goroutine代码一百万的goroutine, 另外使用ws减少buffer的分配,极大的减少了内存的占用,这也是大家热议的一个话题。
当然诚如作者所言,他并不是要提供一个更好的优化的websocket框架,而是演示了采用一些技术进行的优化,通过阅读他的slide和代码,我们至少有以下疑问?
- 虽然支持百万连接,但是并发的吞吐率和延迟是怎样的?
- 服务器实现的是单goroutine的处理,如果业务代码耗时较长会怎么样
- 主要适合什么场景?
吞吐率和延迟需要数据来支撑,但是显然这个单goroutine处理的模式不适合耗时较长的业务处理,"hello world"或者直接的简单的memory操作应该没有问题。对于百万连接但是并发量很小的场景,比如消息推送、页游等场景,这种实现应该是没有问题的。但是对于并发量很大,延迟要求比较低的场景,这种实现可能会存在问题。
这篇文章和后续的两篇文章,将测试巨量连接/高并发/低延迟场景的几种服务器模式的性能,通过比较相应的连接、吞吐率、延迟,给读者一个有价值的选型参考。
作为一个更通用的测试,我们实现的是TCP服务器,而不是websocket服务器。
在实现一个TCP服务器的时候,首先你要问自己,到底你需要的是哪一个类型的服务器?



当然你可能会回答,我都想要啊。但是对于一个单机服务器,资源是有限的,鱼与熊掌不可兼得,我们只能尽力挖掘单个服务器的能力,有些情况下必须通过堆服务器的方式解决,尤其在双十一、春节等时候,很大程度上都是通过扩容来解决的,这是因为单个服务器确确实实能力有限。
尽管单个服务器能力有限,不同的设计取得的性能也是不一样的,这个系列的文章测试不同的场景、不同的设计对性能的影响以及总结,主要包括:
- 百万连接情况下的goroutine-per-connection模式服务器的资源占用
- 百万连接情况下的epoller模式服务器的资源占用
- 百万连接情况下epoller模式服务器的吞吐率和延迟
- 客户端为单goroutine和多goroutine情况下epoller方式测试
- 服务器为多epoller情况下的吞吐率和延迟 (百万连接)
- prefork模式的epoller服务器 (百万连接)
- Reactor模式的epoller服务器 (百万连接)
- 正常连接下高吞吐服务器的性能(连接数<=5000)
- I/O密集型epoll服务器
- I/O密集型goroutine-per-connection服务器
- CPU密集型epoll服务器
- CPU密集型goroutine-per-connection服务器
零、 测试环境的搭建
我们在同一台机器上测试服务器和客户端。首先就是服务器参数的设置,主要是可以打开的文件数量。
file-max是设置系统所有进程一共可以打开的文件数量。同时程序也可以通过setrlimit调用设置每个进程的限制。
echo 2000500 > /proc/sys/fs/file-max或者 sysctl -w "fs.file-max=2000500"可以实时更改这个参数,但是重启之后会恢复为默认值。
也可以修改/etc/sysctl.conf, 加入fs.file-max = 2000500重启或者sysctl -w生效。
设置资源限制。首先修改/proc/sys/fs/nr_open,然后再用ulimit进行修改:
| 1 2 | echo 2000500 > /proc/sys/fs/nr_open ulimit -n 2000500 |
ulimit设置当前shell以及由它启动的进程的资源限制,所以你如果打开多个shell窗口,应该都要进行设置。
当然如果你想重启以后也会使用这些参数,你需要修改/etc/sysctl.conf中的fs.nr_open参数和/etc/security/limits.conf的参数:
| 1 2 3 | # vi /etc/security/limits.conf * soft nofile 2000500 * hard nofile 2000500 |
如果你开启了iptables,iptalbes会使用nf_conntrack模块跟踪连接,而这个连接跟踪的数量是有最大值的,当跟踪的连接超过这个最大值,就会导致连接失败。 通过命令查看
| 1 2 | # wc -l /proc/net/nf_conntrack 1024000 |
查看最大值
| 1 2 | # cat /proc/sys/net/nf_conntrack_max 1024000 |
可以通过修改这个最大值来解决这个问题
在/etc/sysctl.conf添加内核参数 net.nf_conntrack_max = 2000500
对于我们的测试来说,为了我们的测试方便,可能需要一些网络协议栈的调优,可以根据个人的情况进行设置。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | sysctl -w fs.file-max=2000500 sysctl -w fs.nr_open=2000500 sysctl -w net.nf_conntrack_max=2000500 ulimit -n 2000500 sysctl -w net.ipv4.tcp_mem='131072 262144 524288' sysctl -w net.ipv4.tcp_rmem='8760 256960 4088000' sysctl -w net.ipv4.tcp_wmem='8760 256960 4088000' sysctl -w net.core.rmem_max=16384 sysctl -w net.core.wmem_max=16384 sysctl -w net.core.somaxconn=2048 sysctl -w net.ipv4.tcp_max_syn_backlog=2048 sysctl -w /proc/sys/net/core/netdev_max_backlog=2048 sysctl -w net.ipv4.tcp_tw_recycle=1 sysctl -w net.ipv4.tcp_tw_reuse=1 |
另外,我的测试环境是是两颗 E5-2630 V4的CPU, 一共20个核,打开超线程40个逻辑核, 内存32G。
一、 简单的支持百万连接的TCP服务器
服务器
首先我们实现一个百万连接的服务器,采用每个连接一个goroutine的模式(goroutine-per-conn)。
server.go
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 | func main() { ln, err := net.Listen("tcp", ":8972") if err != nil { panic(err) } go func() { if err := http.ListenAndServe(":6060", nil); err != nil { log.Fatalf("pprof failed: %v", err) } }() var connections []net.Conn defer func() { for _, conn := range connections { conn.Close() } }() for { conn, e := ln.Accept() if e != nil { if ne, ok := e.(net.Error); ok && ne.Temporary() { log.Printf("accept temp err: %v", ne) continue } log.Printf("accept err: %v", e) return } go handleConn(conn) connections = append(connections, conn) if len(connections)%100 == 0 { log.Printf("total number of connections: %v", len(connections)) } } } func handleConn(conn net.Conn) { io.Copy(ioutil.Discard, conn) } |
编译go build -o server server.go,然后运行./server。
客户端
客户端建立好连接后,不断的轮询每个连接,发送一个简单的hello world\n的消息。
client.go
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 | var ( ip = flag.String("ip", "127.0.0.1", "server IP") connections = flag.Int("conn", 1, "number of tcp connections") ) func main() { flag.Parse() addr := *ip + ":8972" log.Printf("连接到 %s", addr) var conns []net.Conn for i := 0; i < *connections; i++ { c, err := net.DialTimeout("tcp", addr, 10*time.Second) if err != nil { fmt.Println("failed to connect", i, err) i-- continue } conns = append(conns, c) time.Sleep(time.Millisecond) } defer func() { for _, c := range conns { c.Close() } }() log.Printf("完成初始化 %d 连接", len(conns)) tts := time.Second if *connections > 100 { tts = time.Millisecond * 5 } for { for i := 0; i < len(conns); i++ { time.Sleep(tts) conn := conns[i] conn.Write([]byte("hello world\r\n")) } } } |
因为从一个IP连接到同一个服务器的某个端口最多也只能建立65535个连接,所以直接运行客户端没办法建立百万的连接。 Eran Yanay采用docker的方法确实让人眼前一亮(我以前都是通过手工设置多个ip的方式实现,采用docker的方式更简单)。
我们使用50个docker容器做客户端,每个建立2万个连接,总共建立一百万的连接。
| 1 | ./setup.sh 20000 50 172.17.0.1 |
setup.sh内容如下,使用几M大小的alpinedocker镜像跑测试:
setup.sh
| 1 2 3 4 5 6 7 8 9 10 11 12 | #!/bin/bash address, 缺省是 172.17.0.1 CONNECTIONS=$1 REPLICAS=$2 IP=$3 #go build --tags "static netgo" -o client client.go for (( c=0; c<${REPLICAS}; c++ )) do docker run -v $(pwd)/client:/client --name 1mclient_$c -d alpine /client \ -conn=${CONNECTIONS} -ip=${IP} done |
数据分析
使用以下工具查看性能:
- dstat:查看机器的资源占用(cpu, memory,中断数和上下文切换次数)
- ss:查看网络连接情况
- pprof:查看服务器的性能
- report.sh: 后续通过脚本查看延迟
 没连接前的服务器
没连接前的服务器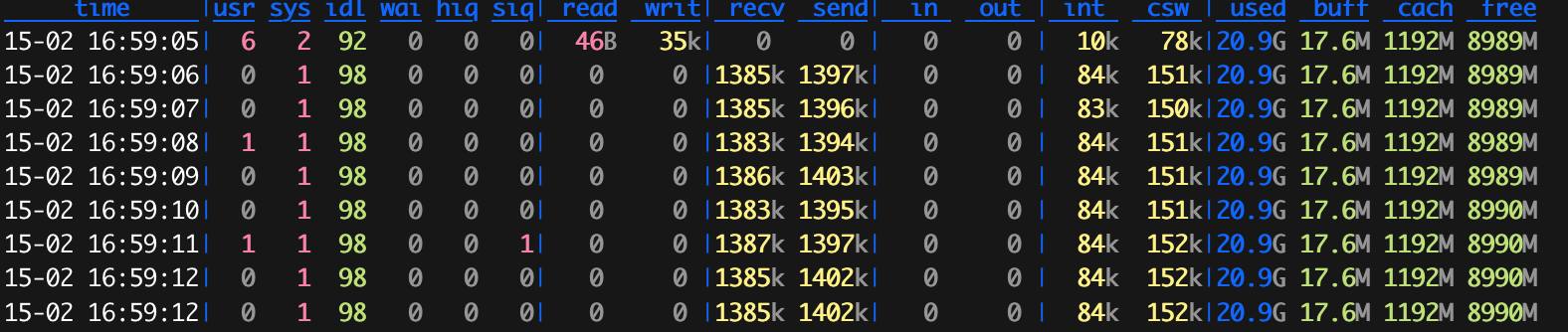 建立百万连接后的服务器
建立百万连接后的服务器
可以看到建立连接后大约占了19G的内存,CPU占用非常小,网络传输1.4MB左右的样子。
二、 服务器epoll方式实现
和Eran Yanay最初指出的一样,上述方案使用了上百万的goroutine,耗费了太多了内存资源和调度,改为epoll模式,大大降低了内存的使用。Eran Yanay的epoll实现只针对Linux的epoll而实现,比mailru的easygo实现和使用起来要简单,我们采用他的这种实现方式。
Go的net方式在Linux也是通过epoll方式实现的,为什么我们还要再使用epoll方式进行封装呢?原因在于Go将epoll方式封装再内部,对外并没有直接提供epoll的方式来使用。好处是降低的开发的难度,保持了Go类似"同步"读写的便利型,但是对于需要大量的连接的情况,我们采用这种每个连接一个goroutine的方式占用资源太多了,所以这一节介绍的就是hack连接的文件描述符,采用epoll的方式自己管理读写。
服务器
服务器需要改造一下:
server.go
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 | var epoller *epoll func main() { setLimit() ln, err := net.Listen("tcp", ":8972") if err != nil { panic(err) } go func() { if err := http.ListenAndServe(":6060", nil); err != nil { log.Fatalf("pprof failed: %v", err) } }() epoller, err = MkEpoll() if err != nil { panic(err) } go start() for { conn, e := ln.Accept() if e != nil { if ne, ok := e.(net.Error); ok && ne.Temporary() { log.Printf("accept temp err: %v", ne) continue } log.Printf("accept err: %v", e) return } if err := epoller.Add(conn); err != nil { log.Printf("failed to add connection %v", err) conn.Close() } } } func start() { var buf = make([]byte, 8) for { connections, err := epoller.Wait() if err != nil { log.Printf("failed to epoll wait %v", err) continue } for _, conn := range connections { if conn == nil { break } if _, err := conn.Read(buf); err != nil { if err := epoller.Remove(conn); err != nil { log.Printf("failed to remove %v", err) } conn.Close() } } } } |
listener还是保持原来的样子,Accept一个新的客户端请求后,就把它加入到epoll的管理中。单独起一个 gorouting监听数据到来的事件,每次只最多读取100个事件。
epoll的实现如下:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 | type epoll struct { fd int connections map[int]net.Conn lock *sync.RWMutex } func MkEpoll() (*epoll, error) { fd, err := unix.EpollCreate1(0) if err != nil { return nil, err } return &epoll{ fd: fd, lock: &sync.RWMutex{}, connections: make(map[int]net.Conn), }, nil } func (e *epoll) Add(conn net.Conn) error { // Extract file descriptor associated with the connection fd := socketFD(conn) err := unix.EpollCtl(e.fd, syscall.EPOLL_CTL_ADD, fd, &unix.EpollEvent{Events: unix.POLLIN | unix.POLLHUP, Fd: int32(fd)}) if err != nil { return err } e.lock.Lock() defer e.lock.Unlock() e.connections[fd] = conn if len(e.connections)%100 == 0 { log.Printf("total number of connections: %v", len(e.connections)) } return nil } func (e *epoll) Remove(conn net.Conn) error { fd := socketFD(conn) err := unix.EpollCtl(e.fd, syscall.EPOLL_CTL_DEL, fd, nil) if err != nil { return err } e.lock.Lock() defer e.lock.Unlock() delete(e.connections, fd) if len(e.connections)%100 == 0 { log.Printf("total number of connections: %v", len(e.connections)) } return nil } func (e *epoll) Wait() ([]net.Conn, error) { events := make([]unix.EpollEvent, 100) n, err := unix.EpollWait(e.fd, events, 100) if err != nil { return nil, err } e.lock.RLock() defer e.lock.RUnlock() var connections []net.Conn for i := 0; i < n; i++ { conn := e.connections[int(events[i].Fd)] connections = append(connections, conn) } return connections, nil } func socketFD(conn net.Conn) int { //tls := reflect.TypeOf(conn.UnderlyingConn()) == reflect.TypeOf(&tls.Conn{}) // Extract the file descriptor associated with the connection //connVal := reflect.Indirect(reflect.ValueOf(conn)).FieldByName("conn").Elem() tcpConn := reflect.Indirect(reflect.ValueOf(conn)).FieldByName("conn") //if tls { // tcpConn = reflect.Indirect(tcpConn.Elem()) //} fdVal := tcpConn.FieldByName("fd") pfdVal := reflect.Indirect(fdVal).FieldByName("pfd") return int(pfdVal.FieldByName("Sysfd").Int()) } |
客户端
还是运行上面的客户端,因为刚才已经建立了50个客户端的容器,我们需要先把他们删除:
| 1 | docker rm -vf $(docker ps -a --format '{ {.ID} } { {.Names} }'|grep '1mclient_' |awk '{print $1}') |
然后再启动50个客户端,每个客户端2万个连接进行进行测试
| 1 | ./setup.sh 20000 50 172.17.0.1 |
数据分析
使用以下工具查看性能:
- dstat:查看机器的资源占用(cpu, memory,中断数和上下文切换次数)
- ss:查看网络连接情况
- pprof:查看服务器的性能
- report.sh: 后续通过脚本查看延迟
没连接前的服务器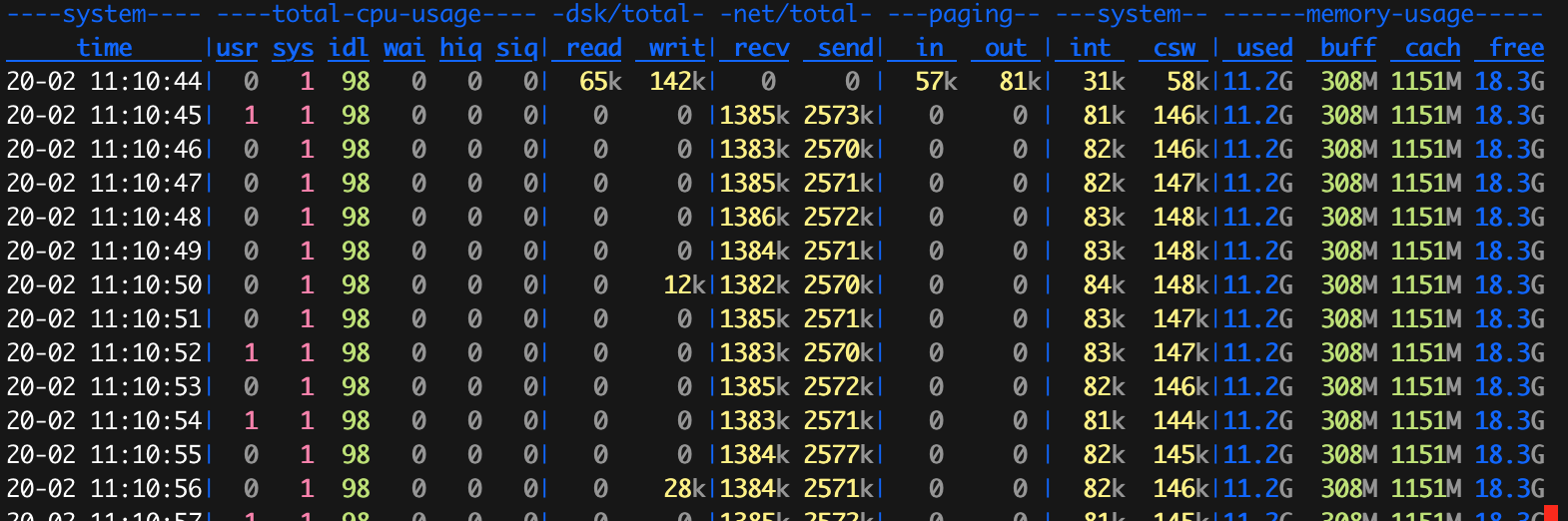 建立百万连接后的服务器
建立百万连接后的服务器
可以看到建立连接后大约占了10G的内存,CPU占用非常小。
有一个专门使用epoll实现的网络库tidwall/evio,可以专门开发epoll方式的网络程序。去年阿里中间件大赛,美团的王亚普使用evio库杀入到排行榜第五名,也是前五中唯一一个使用Go实现的代码,其它使用Go标准库实现的代码并没有达到6983 tps/s 的程序,这也说明了再一些场景下采用epoll方式也能带来性能的提升。(天池中间件大赛Golang版Service Mesh思路分享)
但是也正如evio作者所说,evio并不能提到Go标准net库,它只使用特定的场景, 实现redis/haproxy等proxy。因为它是单goroutine处理处理的,或者你可以实现多goroutine的event-loop,但是针对一些I/O或者计算耗时的场景,未必能展现出它的优势出来。
我们知道Redis的实现是单线程的,正如作者Clarifications about Redis and Memcached介绍的,Redis主要是内存中的数据操作,单线程根本不是瓶颈(持久化是独立线程)我们后续的测试也会印证这一点。所以epoll I/O dispatcher之后是采用单线程还是Reactor模式(多线程事件处理)还是看具体的业务。
下一篇文章我们会继续测试百万连接情况下的吞吐率和延迟,这是上面的两篇文章所没有提到的。
参考
- https://mrotaru.wordpress.com/2013/10/10/scaling-to-12-million-concurrent-connections-how-migratorydata-did-it/
- https://stackoverflow.com/questions/22090229/how-did-whatsapp-achieve-2-million-connections-per-server
- https://github.com/eranyanay/1m-go-websockets
- https://medium.freecodecamp.org/million-websockets-and-go-cc58418460bb
百万 Go TCP 连接的思考2: 百万连接的吞吐率和延迟
上一篇epoll方式减少资源占用 介绍了测试环境以及epoll方式实现百万连接的TCP服务器。这篇文章介绍百万连接服务器的几种实现方式,以及它们的吞吐率和延迟。
这几种服务器的实现包括:epoll、multiple epoller、prefork 和 workerpool。
第一篇 百万 Go TCP 连接的思考: epoll方式减少资源占用
第二篇 百万 Go TCP 连接的思考2: 百万连接的吞吐率和延迟
第三篇 百万 Go TCP 连接的思考: 正常连接下的吞吐率和延迟
相关代码已发布到github上: 1m-go-tcp-server。
三、 epoll服务器加上吞吐率指标
上一篇已经介绍了epoll方式的实现,为了测试吞吐率,我们需要通过传递特殊的数据来计算。
客户端将它发送数据时的时间戳传给服务器,这个时间戳只需要8个字节,服务器不需要任何改动,只需要原封不动的将数据回传给客户端:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | ...... var ( opsRate = metrics.NewRegisteredMeter("ops", nil) ) func start() { for { connections, err := epoller.Wait() if err != nil { log.Printf("failed to epoll wait %v", err) continue } for _, conn := range connections { if conn == nil { break } // 将消息(时间戳)原封不动的写回 _, err = io.CopyN(conn, conn, 8) if err != nil { if err := epoller.Remove(conn); err != nil { log.Printf("failed to remove %v", err) } conn.Close() } opsRate.Mark(1) } } } |
这里epoll我们并没有注册为边缘触发的方式,默认是水平触发的方式。
每次读取8个字节(时间戳),然后返回给客户端。同时metric记录一次。
metric库使用的是rcrowley/go-metrics。
四、客户端也修改为epoll方式
客户端不再发送hello world数据,而是当前的时间戳,收到服务器的返回后,就可以计算出一次请求的总共的花费(延迟,latency),然后发送下一个请求。
所以客户端的测试并不是pipeline的方式,以下所有的测试都不是pipeline的方式,而是收到返回再发下一个请求。
客户端也需要改成epoll的方式,原先一个goroutine轮训所有的连接的方式性能比较底下,所以改成epoll的方式:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 | package main import ( "encoding/binary" "flag" "fmt" "log" "net" "os" "syscall" "time" "github.com/rcrowley/go-metrics" ) var ( ip = flag.String("ip", "127.0.0.1", "server IP") connections = flag.Int("conn", 1, "number of tcp connections") startMetric = flag.String("sm", time.Now().Format("2006-01-02T15:04:05 -0700"), "start time point of all clients") ) var ( opsRate = metrics.NewRegisteredTimer("ops", nil) ) var epoller *epoll // client改造成epoll方式, 处理epoll消息是单线程的 func main() { flag.Parse() go func() { startPoint, err := time.Parse("2006-01-02T15:04:05 -0700", *startMetric) if err != nil { panic(err) } time.Sleep(startPoint.Sub(time.Now())) metrics.Log(metrics.DefaultRegistry, 5*time.Second, log.New(os.Stderr, "metrics: ", log.Lmicroseconds)) }() var err error epoller, err = MkEpoll() if err != nil { panic(err) } addr := *ip + ":8972" log.Printf("连接到 %s", addr) var conns []net.Conn for i := 0; i < *connections; i++ { c, err := net.DialTimeout("tcp", addr, 10*time.Second) if err != nil { fmt.Println("failed to connect", i, err) i-- continue } if err := epoller.Add(c); err != nil { log.Printf("failed to add connection %v", err) c.Close() } conns = append(conns, c) } log.Printf("完成初始化 %d 连接", len(conns)) tts := time.Second if *connections > 100 { tts = time.Millisecond * 5 } go start() for i := 0; i < len(conns); i++ { time.Sleep(tts) conn := conns[i] err = binary.Write(conn, binary.BigEndian, time.Now().UnixNano()) if err != nil { log.Printf("failed to write timestamp %v", err) if err := epoller.Remove(conn); err != nil { if err := epoller.Remove(conn); err != nil { log.Printf("failed to remove %v", err) } } } } select {} } func start() { var nano int64 for { connections, err := epoller.Wait() if err != nil { log.Printf("failed to epoll wait %v", err) continue } for _, conn := range connections { if conn == nil { break } if err := binary.Read(conn, binary.BigEndian, &nano); err != nil { log.Printf("failed to read %v", err) if err := epoller.Remove(conn); err != nil { log.Printf("failed to remove %v", err) } conn.Close() continue } else { opsRate.Update(time.Duration(time.Now().UnixNano() - nano)) } err = binary.Write(conn, binary.BigEndian, time.Now().UnixNano()) if err != nil { log.Printf("failed to write %v", err) if err := epoller.Remove(conn); err != nil { log.Printf("failed to remove %v", err) } conn.Close() } } } } |
使用的epoll实现代码和服务器端是一样的。
客户端的统计会遇到一个问题,因为我们会启动50个docker容器,计算客户端的吞吐率的时候我们需要统计同一个时间段内这50个容器所有的请求和延迟。这里我们用了一个小小的技巧,让metrics库再同一个时间打印出它们的统计数据,基本可以保证统计的是这50个容器的同一个时间段内的指标。
数据分析
这里我们对50个容器的日志进行统计, 汇总吞吐率进行相加,可以得到吞吐率(TPS)为 42495, 延迟(latency)为 23秒。
五、客户端改为多个epoller
在上面的实现中,我们的客户端使用一个epoller处理所有的请求, 在事件监听的处理中,使用一个goroutine处理接收的所有的事件,如果处理事件比较慢,这个单一的goroutine将会是严重的瓶颈。
所以我们要把它改成多goroutine的方式去处理。一种方式是启动一个线程池,采用多event loop的方式处理事件,另外一种方式是使用多个epoller, 每个epoller处理一批连接,每个epoller独自占用一个goroutine。 我们的客户端采用第二种方式,实现起来比较简单。
Linux的Accept和epoller都曾有惊群的现象,也就是一个一个事件到来后会唤醒所有的监听的线程,目前这个问题应该已经不存在了。
client.go
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 | func main() { flag.Parse() setLimit() go func() { startPoint, _ := time.Parse("2006-01-02T15:04:05 -0700", *startMetric) time.Sleep(startPoint.Sub(time.Now())) metrics.Log(metrics.DefaultRegistry, 5*time.Second, log.New(os.Stderr, "metrics: ", log.Lmicroseconds)) }() addr := *ip + ":8972" log.Printf("连接到 %s", addr) for i := 0; i < *c; i++ { go mkClient(addr, *connections/(*c)) } select {} } func mkClient(addr string, connections int) { epoller, err := MkEpoll() if err != nil { panic(err) } var conns []net.Conn for i := 0; i < connections; i++ { c, err := net.DialTimeout("tcp", addr, 10*time.Second) if err != nil { fmt.Println("failed to connect", i, err) i-- continue } if err := epoller.Add(c); err != nil { log.Printf("failed to add connection %v", err) c.Close() } conns = append(conns, c) } log.Printf("完成初始化 %d 连接", len(conns)) go start(epoller) tts := time.Second if *c > 100 { tts = time.Millisecond * 5 } for i := 0; i < len(conns); i++ { time.Sleep(tts) conn := conns[i] err = binary.Write(conn, binary.BigEndian, time.Now().UnixNano()) if err != nil { log.Printf("failed to write timestamp %v", err) if err := epoller.Remove(conn); err != nil { if err := epoller.Remove(conn); err != nil { log.Printf("failed to remove %v", err) } } } } select {} } func start(epoller *epoll) { ...... //同上 } |
测试脚本稍微一下,增加一个epoller数量的控制:
| 1 2 3 4 5 6 7 8 9 10 11 12 | CONNECTIONS=$1 REPLICAS=$2 IP=$3 CONCURRENCY=$4 DATE=`date -d "+2 minutes" +"%FT%T %z"` for (( c=0; c<${REPLICAS}; c++ )) do docker run -v $(pwd)/mclient:/client --name 1mclient_$c -d alpine /client \ -conn=${CONNECTIONS} -ip=${IP} -c=${CONCURRENCY} -sm "${DATE}" done |
数据分析
这里我们对50个容器的日志进行统计, 汇总吞吐率进行相加,可以得到吞吐率(TPS)为 42402, 延迟(latency)为 0.8秒。
吞吐率并没有增加,但是得益于我们客户端可以并发的处理消息,可以大大减小事务的延迟,将相关的延迟可以降低到一秒以下。
六、服务器改为多个epoller
基于我们上面客户端使用多个epoller的启发,我们可以修改服务器端也采用多个epoller的方式,看看是否能增加吞吐率或者降低延迟。
server.go
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 | package main import ( "flag" "io" "log" "net" "net/http" _ "net/http/pprof" "os" "syscall" "time" "github.com/libp2p/go-reuseport" "github.com/rcrowley/go-metrics" ) var ( c = flag.Int("c", 10, "concurrency") ) var ( opsRate = metrics.NewRegisteredMeter("ops", nil) ) func main() { flag.Parse() go metrics.Log(metrics.DefaultRegistry, 5*time.Second, log.New(os.Stderr, "metrics: ", log.Lmicroseconds)) go func() { if err := http.ListenAndServe(":6060", nil); err != nil { log.Fatalf("pprof failed: %v", err) } }() for i := 0; i < *c; i++ { go startEpoll() } select {} } func startEpoll() { ln, err := reuseport.Listen("tcp", ":8972") if err != nil { panic(err) } epoller, err := MkEpoll() if err != nil { panic(err) } go start(epoller) for { conn, e := ln.Accept() if e != nil { if ne, ok := e.(net.Error); ok && ne.Temporary() { log.Printf("accept temp err: %v", ne) continue } log.Printf("accept err: %v", e) return } if err := epoller.Add(conn); err != nil { log.Printf("failed to add connection %v", err) conn.Close() } } } func start(epoller *epoll) { for { connections, err := epoller.Wait() if err != nil { log.Printf("failed to epoll wait %v", err) continue } for _, conn := range connections { if conn == nil { break } io.CopyN(conn, conn, 8) if err != nil { if err := epoller.Remove(conn); err != nil { log.Printf("failed to remove %v", err) } conn.Close() } opsRate.Mark(1) } } } |
和客户端的类似,我们启动了多个epoller。这里我们使用reuseport库启动多个goroutine监听同一个端口,这个特性应该在较新的Linux内核上已经支持, 内核会负责负载均衡。
当然我们也可以启动一个goroutine进行监听,接收到客户端的请求后在交给某个epoller进行处理(随机或者轮询),我们就负责连接的负载均衡。
再或者,多个goroutine可以同时调用同一个listener.Accept方法,对Accept进行竞争。
后面的处理逻辑和单个的epoller的方式是一样的,只不过我们使用多个goroutine进行处理。
数据分析
这里我们对50个容器的日志进行统计, 汇总吞吐率进行相加,可以得到吞吐率(TPS)为 197814, 延迟(latency)为 0.9秒。
以下所有的测试都使用多epoller的客户端,下面的比较也是针对多epoller的客户端的测试:
和单poller的服务器实现相比较,多epoller的服务器客户端吞吐率大幅增加,而延迟略微增加。
七、 prefork实现服务器
Prefork 是Apache实现的一种服务方式。一个单一的控制进程启动的时候负责启动多个子进程,每个子进程都是独立的,使用单一的goroutine处理消息事件。
这是一个有趣的实现方式,子进程可以共享父进程打开的文件,这样我们就可以把net.Listener传给子进程,让所有的子进程共同监听这个端口。
传递给子进程的文件是通过exec.Cmd.ExtraFiles字段进行传递的:
| 1 2 3 4 5 6 7 8 9 10 | type Cmd struct { ...... // ExtraFiles specifies additional open files to be inherited by the // new process. It does not include standard input, standard output, or // standard error. If non-nil, entry i becomes file descriptor 3+i. // // ExtraFiles is not supported on Windows. ExtraFiles []*os.File ...... } |
正如注释中所指出的,传递的第i个文件在子进程中的文件描述符为 3+i,所以如果父进程中启动子进程的命令如下的话:
| 1 2 3 4 5 6 | a_file_descriptor, _ := tcplistener.File() children[i] = exec.Command(os.Args[0], "-prefork", "-child") children[i].Stdout = os.Stdout children[i].Stderr = os.Stderr children[i].ExtraFiles = []*os.File{a_file_descriptor} |
子进程你可以这样得到这个父进程的文件:
| 1 | listener, err = net.FileListener(os.NewFile(3, "")) |
我们实现的是父进程和子进程共享同一个listener的方式, 如果你使用reuseport在每个子进程打开同一个端口应该也是可以的,这样就父子之间不需要共享同一个文件了。
完整的服务器实现如下:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 | package main import ( "flag" "io" "log" "net" "os" "os/exec" "syscall" ) var ( c = flag.Int("c", 10, "concurrency") prefork = flag.Bool("prefork", false, "use prefork") child = flag.Bool("child", false, "is child proc") ) func main() { flag.Parse() var ln net.Listener var err error if *prefork { ln = doPrefork(*c) } else { ln, err = net.Listen("tcp", ":8972") if err != nil { panic(err) } } startEpoll(ln) select {} } func startEpoll(ln net.Listener) { epoller, err := MkEpoll() if err != nil { panic(err) } go start(epoller) for { conn, e := ln.Accept() if e != nil { if ne, ok := e.(net.Error); ok && ne.Temporary() { log.Printf("accept temp err: %v", ne) continue } log.Printf("accept err: %v", e) return } if err := epoller.Add(conn); err != nil { log.Printf("failed to add connection %v", err) conn.Close() } } } func doPrefork(c int) net.Listener { var listener net.Listener if !*child { addr, err := net.ResolveTCPAddr("tcp", ":8972") if err != nil { log.Fatal(err) } tcplistener, err := net.ListenTCP("tcp", addr) if err != nil { log.Fatal(err) } fl, err := tcplistener.File() if err != nil { log.Fatal(err) } children := make([]*exec.Cmd, c) for i := range children { children[i] = exec.Command(os.Args[0], "-prefork", "-child") children[i].Stdout = os.Stdout children[i].Stderr = os.Stderr children[i].ExtraFiles = []*os.File{fl} err = children[i].Start() if err != nil { log.Fatalf("failed to start child: %v", err) } } for _, ch := range children { if err := ch.Wait(); err != nil { log.Printf("failed to wait child's starting: %v", err) } } os.Exit(0) } else { var err error listener, err = net.FileListener(os.NewFile(3, "")) if err != nil { log.Fatal(err) } } return listener } func start(epoller *epoll) { for { connections, err := epoller.Wait() if err != nil { log.Printf("failed to epoll wait %v", err) continue } for _, conn := range connections { if conn == nil { break } io.CopyN(conn, conn, 8) if err != nil { if err := epoller.Remove(conn); err != nil { log.Printf("failed to remove %v", err) } conn.Close() } } } } |
数据分析
服务器启动50个子进程: ./server -c 50 -prefork
客户端还是一样: ./setupm.sh 20000 50 172.17.0.1 10。
这里我们对50个容器的日志进行统计, 汇总吞吐率进行相加,可以得到吞吐率(TPS)为 444415, 延迟(latency)为 1.5秒。
和多poller的服务器实现相比较,prefork的服务器客户端吞吐率又大大幅增加,而延迟相对长一些了,比多poller的实现延迟翻倍。
八、 服务器实现workerpool
从单个poller的代码分析可知,单goroutine处理消息到来的事件可能会有瓶颈,尤其是并发量比较大的情况下,无法使用多核的优势,因为我们采用多poller、prefork的方式可以并发地处理到来的消息,这里还有一种Reactor的方式,将I/O goroutine和业务goroutine分离, I/O goroutine采用单goroutine的方式,监听的消息交给一个goroutine池 (workerpool)去处理,这样可以并行的处理业务消息,而不会阻塞I/O goroutine。
这里实现的消息读取也是在 workerpool 中实现的, 一般更通用的方式是I/O goroutine解析出消息, 将解析好的消息再交给workerpool去处理。我们这里的例子比较简单,所以读取消息也在workerpool中实现。
worker pool的实现如下:
workerpool.go
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 | package main import ( "io" "log" "net" "sync" ) type pool struct { workers int maxTasks int taskQueue chan net.Conn mu sync.Mutex closed bool done chan struct{} } func newPool(w int, t int) *pool { return &pool{ workers: w, maxTasks: t, taskQueue: make(chan net.Conn, t), done: make(chan struct{}), } } func (p *pool) Close() { p.mu.Lock() p.closed = true close(p.done) close(p.taskQueue) p.mu.Unlock() } func (p *pool) addTask(conn net.Conn) { p.mu.Lock() if p.closed { p.mu.Unlock() return } p.mu.Unlock() p.taskQueue <- conn } func (p *pool) start() { for i := 0; i < p.workers; i++ { go p.startWorker() } } func (p *pool) startWorker() { for { select { case <-p.done: return case conn := <-p.taskQueue: if conn != nil { handleConn(conn) } } } } func handleConn(conn net.Conn) { _, err := io.CopyN(conn, conn, 8) if err != nil { if err := epoller.Remove(conn); err != nil { log.Printf("failed to remove %v", err) } conn.Close() } opsRate.Mark(1) } |
服务器端代码改造:
server.go
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 | var epoller *epoll var workerPool *pool func main() { flag.Parse() go metrics.Log(metrics.DefaultRegistry, 5*time.Second, log.New(os.Stderr, "metrics: ", log.Lmicroseconds)) ln, err := net.Listen("tcp", ":8972") if err != nil { panic(err) } go func() { if err := http.ListenAndServe(":6060", nil); err != nil { log.Fatalf("pprof failed: %v", err) } }() workerPool = newPool(*c, 1000000) workerPool.start() epoller, err = MkEpoll() if err != nil { panic(err) } go start() for { conn, e := ln.Accept() if e != nil { if ne, ok := e.(net.Error); ok && ne.Temporary() { log.Printf("accept temp err: %v", ne) continue } log.Printf("accept err: %v", e) return } if err := epoller.Add(conn); err != nil { log.Printf("failed to add connection %v", err) conn.Close() } } workerPool.Close() } func start() { for { connections, err := epoller.Wait() if err != nil { log.Printf("failed to epoll wait %v", err) continue } for _, conn := range connections { if conn == nil { break } workerPool.addTask(conn) } } } |
数据分析
服务器启动50个子进程: ./server -c 50 -prefork
客户端还是一样: ./setupm.sh 20000 50 172.17.0.1 10。
这里我们对50个容器的日志进行统计, 汇总吞吐率进行相加,可以得到吞吐率(TPS)为 190022, 延迟(latency)为 0.3秒。
总结
| 吞吐率 (tps) | 延迟 (latency) | |
|---|---|---|
| goroutine-per-conn | 202830 | 4.9s |
| 单epoller(单epoller client) | 42495 | 23s |
| 单epoller | 42402 | 0.8s |
| 多epoller | 197814 | 0.9s |
| prefork | 444415 | 1.5s |
| workerpool | 190022 | 0.3s |
从上表可以看出,客户端的实现对测试结果影响也是巨大的,不过实际我们的客户端分布在不同的节点上,而不像我们的测试不得不使用同一台机器启动百万个节点,所以下面的测试都是通过多epoller client进行测试的,尽量让客户端能并发的处理消息。
从测试结果来看, 在百万并发的情况下, workerpool的实现还是不错的, 既能达到很高的吞吐率(19万), 还能取得 0.3秒的延迟, 而且使用小量的goroutine的worker pool也不会占用太多的系统资源。prefork可以大幅提高吞吐率,但是延迟要稍微长一些。
以上是在巨量连接情况下的各种实现的吞吐率和延迟的测试,这是一类的应用场景, 还有一类很大的应用场景, 比如企业内的服务通讯, 连接数并不会很多,我们将介绍这类场景下几种实现方案的吞吐率和延迟。
百万 Go TCP 连接的思考3: 正常连接下的吞吐率和延迟
这一篇文章介绍了I/O密集型服务器和计算密集型的服务器的两种场景,对多epoller服务器和goroutine-per-connection服务器两种服务器进行测试,连接数分别是5000、2000、1000、500、200和100。
第一篇 百万 Go TCP 连接的思考: epoll方式减少资源占用
第二篇 百万 Go TCP 连接的思考2: 百万连接的吞吐率和延迟
第三篇 百万 Go TCP 连接的思考: 正常连接下的吞吐率和延迟
相关代码已发布到github上: 1m-go-tcp-server。
前两篇的是有巨量连接的情况下服务器的性能,这类服务器可能应用于消息推送、IOT、页游等场景,追求的是大量连接,并发量相对不大的场景。还有一类场景是服务器的连接数不多,几十几百,最多几千的TCP连接,比如公司内的服务之间的调用等,这类服务器在不同的实现下的性能是怎样的?
测试区分两个场景: I/O密集型和计算密集型。I/O密集型的服务比如文件的读取、数据库的访问,远程服务的调用等等,计算密集型的访问比如区块链的挖矿、算法的计算、类似redis这样的基于内存的数据处理服务等等(当然redis还是memory bound类型的服务)。
我们通过time.Sleep让goroutine休眠来模拟I/O密集型的服务,实际goroutine休眠和真正的I/O密集型的服务还是有区别的,虽然它们都有一定的耗时,goroutine在等待的过程中会休眠,但是I/O密集型还有大量的I/O访问,比如磁盘、网络等等。出于方便测试的目的,我们还是使用time.Sleep来模拟,主要测试goroutine在休眠一段时间后对性能的影响。
计算密集型的访问我们采用挖矿算法,通过计算hash值,满足一定的挖矿难度让CPU进行大量的计算动作。
测试分别采用并发连接数为 5000、2000、1000、500、200、100,测试对应的吞吐率和延迟。
测试使用多epoller的方式实现的服务器和goroutine-per-connection实现的服务器。因为连接数少,我们可以采用goroutine-per-connection的方式。
九、 I/O 密集型的服务器(无sleep)
首先测试I/O密集型的服务器,在没有sleep的情况下,两个服务器的数据对比如下:
多epoller服务器
代码: 10_io_intensive_epoll_server
| 5000 | 2000 | 1000 | 500 | 200 | 100 | |
|---|---|---|---|---|---|---|
| tps | 210064 | 203027 | 207097 | 208460 | 200798 | 212587 |
| latency(s) | 23.2 | 9.1 | 4.5 | 2.3 | 0.9 | 0.5 |
吞吐率变化不大,基本都在误差以内,延迟随着连接数的降低而降低,基本成线性关系。
服务器可以达到20万的吞吐率。
goroutine-per-connection 服务器
| 5000 | 2000 | 1000 | 500 | 200 | 100 | |
|---|---|---|---|---|---|---|
| tps | 203038 | 208002 | 209128 | 207990 | 209192 | 212376 |
| latency(s) | 24 | 9.2 | 4.6 | 2.3 | 0.9 | 0.5 |
可以看到,当服务器的业务简单,基本没有耗时的情况下,这两种实现的差别不大,基本一样。
十、 I/O 密集型的服务器 (sleep 10 ms)
我们模拟I/O耗时10毫秒的情况,两个服务器的数据对比如下:
多epoller服务器
| 5000 | 2000 | 1000 | 500 | 200 | 100 | |
|---|---|---|---|---|---|---|
| tps | 6218 | 6256 | 6251 | 6108 | 6027 | 4736 |
| latency(s) | 0.8 | 0.3 | 0.2 | 0.08 | 0.04 | 0.03 |
吞吐率急剧下降。
goroutine-per-connection 服务器
| 5000 | 2000 | 1000 | 500 | 200 | 100 | |
|---|---|---|---|---|---|---|
| tps | 203088 | 194783 | 98895 | 49326 | 19747 | 9886 |
| latency(s) | 0.02 | 0.01 | 0.01 | 0.01 | 0.01 | 0.01 |
可以看懂吞吐率会和连接数相关,但是也不是线性关系,随着连接数的增加,所带来的吞吐率收益也慢慢的变弱,也就是有一个拐点,连接数的增加带来的吞吐率的增加将变得很小。
看它的延迟时间,连接数2000以下延迟就是都是业务所耗费的时间(10毫米)。
这给了我们一个启示,在连接数比较小的情况下,正统的goroutine-per-connection可以取得很好的延迟,并且为了提高吞吐率,我们可以适当增加连接数。
十一、 计算密集型服务器
采用挖矿算法,计算哈希值,如果哈希值的前12bit都是0的话算挖矿成功。
多epoller服务器
代码:12_cpu_intensive_epoll_server
| 5000 | 2000 | 1000 | 500 | 200 | 100 | |
|---|---|---|---|---|---|---|
| tps | 212554 | 227291 | 224509 | 229796 | 226687 | 226147 |
| latency(s) | 0.02 | 0.01 | 0.004 | 0.002 | 0.001 | 0.0005 |
吞吐率基本不变,但是延迟随着连接数的降低而成线性降低。
goroutine-per-connection 服务器
| 5000 | 2000 | 1000 | 500 | 200 | 100 | |
|---|---|---|---|---|---|---|
| tps | 211048 | 212343 | 228978 | 228756 | 228768 | 229425 |
| latency(s) | 0.02 | 0.01 | 0.005 | 0.002 | 0.001 | 0.0005 |
吞吐率和多epoller方式基本一致,延迟也一样。 可以看出对于计算密集型的服务,这两种方式的性能差别不大。














 396
396











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









