









一、 solr简介
Solr是基于Lucene的全文搜索服务器,它对外提供类似于Web-service的API接口。用户可以通过http请求,向搜索引擎服务器提交一定格式的XML文件,生成索引;也可以通过Http Get操作提出查找请求,并得到XML格式的返回结果。
简而言之,Sorl是一个搜索引擎,我们可以发送文档给它,让它建立倒排索引(建立搜索源);也可以发送查找请求,让它以某种形式(JSON,XML等)返回结果(文档列表)给你。
二、 Solr的配置
最近在本机配置了Solr4.6.1,主要参考了apache的API文档。
配置方法如下:
本机环境 win7 tomcat6.0 jdk6u27
1. 下载Solr
http://mirror.bit.edu.cn/apache/lucene/solr/4.6.1
2. 部署进tomcat
先将将solr-4.6.1\example\webapps下的solr.war拷到tomcat下的webapps中,并将solr-4.6.1\example\lib中的jar包补充到tomcat的lib中。
3. 引入Core
在webapps\solr\下新建conf文件夹,并把solr-4.6.1\example\multicore目录拷到conf下。
4. 编辑solr.xml
%TOMCAT_HOME%\conf\Catalina\localhost下新建solr.xml
内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<!-- 这里配置的是 Solr 运行的 Home 目录 -->
<Context docBase="${catalina.home}/webapps/solr.war" debug="0" crossContext="true" >
<!-- 这里配置的是core 的目录 -->
<Environment name="solr/home" type="java.lang.String" value="${catalina.home}/webapps/solr/conf/multicore" override="true" />
</Context>
5. 这时启动tomcat,应当可以正常访问solr。
三、配置分词算法
1. 下载你喜欢的分词器
我下载的是:jcseg-1.9.2-src-jar-dict,下载之前需了解它是否支持solr相应的版本
2. 解压并将目录下的 jcseg-core-1.9.2.jar, jcseg-solr-1.9.2.jar, jcseg.properties,lexicon/ 复制到Solr的WEB-INF/lib下。
3.在solr\conf\multicore\core0\conf中的schema.xml添加如下配置(参考jcseg的文档):
<?xml version="1.0" ?>
<schema name="example core zero" version="1.1">
<types>
<fieldtype name="string" class="solr.StrField" sortMissingLast="true" omitNorms="true"/>
<fieldType name="long" class="solr.TrieLongField" precisionStep="0" positionIncrementGap="0"/> <!--kxm begin-->
<fieldtype name="textComplex" class="solr.TextField">
<analyzer>
<tokenizer class="org.lionsoul.jcseg.solr.JcsegTokenizerFactory" mode="complex"/>
</analyzer>
</fieldtype>
<fieldtype name="textSimple" class="solr.TextField">
<analyzer>
<tokenizer class="org.lionsoul.jcseg.solr.JcsegTokenizerFactory" mode="simple"/>
</analyzer>
</fieldtype> <!--kxm end-->
</types>
<fields>
<!-- general -->
<field name="id" type="string" indexed="true" stored="true" multiValued="false" required="true"/>
<field name="type" type="string" indexed="true" stored="true" multiValued="false" />
<field name="name" type="string" indexed="true" stored="true" multiValued="false" />
<field name="core0" type="string" indexed="true" stored="true" multiValued="false" />
<field name="_version_" type="long" indexed="true" stored="true"/> <!--kxm begin-->
<field name="simple" type="textSimple" indexed="true" stored="true" multiValued="true" />
<field name="complex" type="textComplex" indexed="true" stored="true" multiValued="true" />
<!--kxm end--> </fields>
<!-- field to use to determine and enforce document uniqueness. -->
<uniqueKey>id</uniqueKey>
<!-- field for the QueryParser to use when an explicit fieldname is absent -->
<defaultSearchField>name</defaultSearchField>
<!-- SolrQueryParser configuration: defaultOperator="AND|OR" -->
<solrQueryParser defaultOperator="OR"/>
</schema>4. 重启tomcat,此时不应报任何错误。
5. 测试分词效果

四、对数据库中的数据建立倒排索引
1. 启动本机的mysql数据库
我新建test数据库,并在其中新建test表,表有两个字段,ID与Val。ID表示文档编号,Val表示文档内容,这是一个最简单的数据源。
2. 在Solr中配置数据源
在\webapps\solr\conf\multicore\core0\conf\db-data-config.xml中作如下配置:
<dataConfig>
<dataSource type="JdbcDataSource" driver="com.mysql.jdbc.Driver" url="jdbc:mysql://localhost:3306/test" user="root" password="XXXXXX" />
<document name="messages">
<entity name="message" transformer="ClobTransformer" query="select * from test1">
<field column="ID" name="id" />
<field column="Val" name="complex" />
</entity>
</document>
</dataConfig>此处的complex应与schema中的field name相对应。
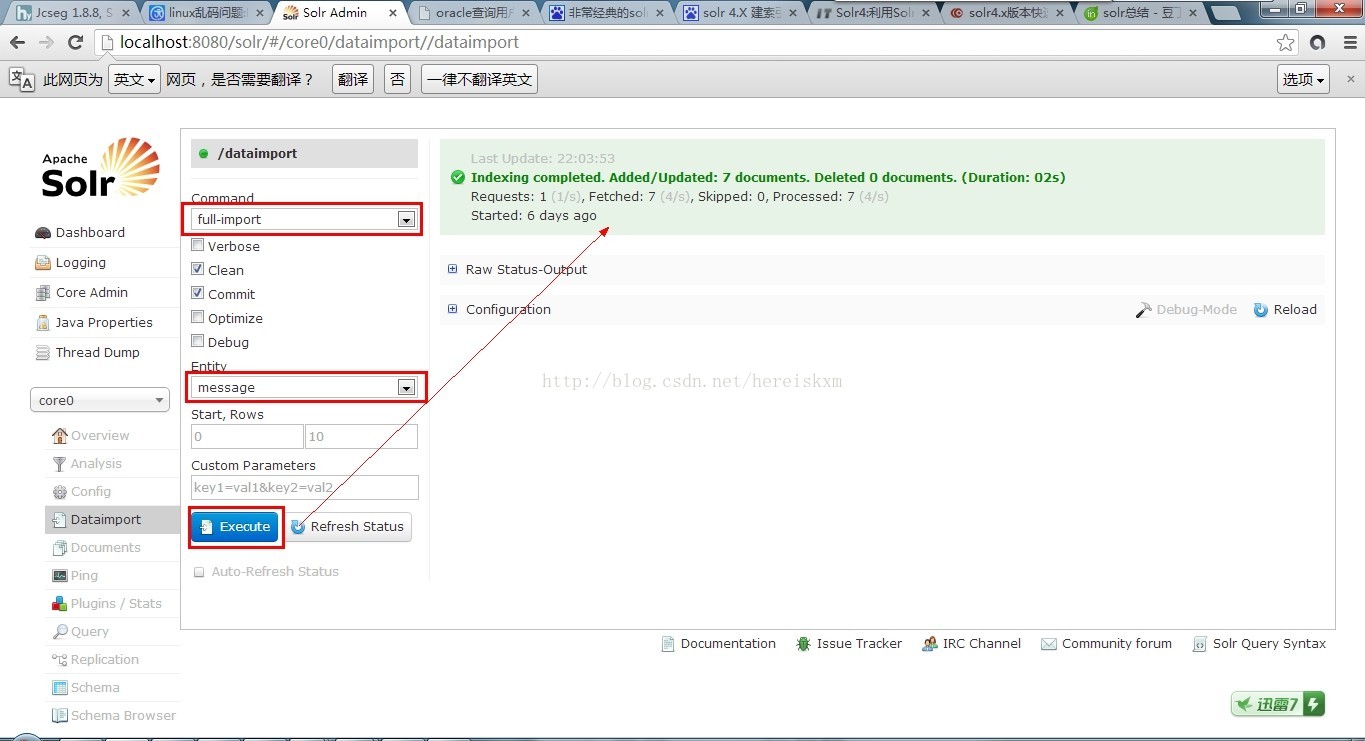
3. 重启tomcat,建索引:
4. 测试查询:
我们此处选择返回查询结果列表的形式是JSON
至此,solr的最简单的一次配置完成了。我们可以看出其中的数据源是怎么变为倒排索引,实现快速查询。企业或网站在数据量极大时,可以使用这种方式建立自己的搜索引擎。接下来我们可以让Nutch和Solr配合,做自己的搜索引擎。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









