






点击上方“五分钟学算法”,选择“星标”公众号
重磅干货,第一时间送达

这世上为什么要有乱码这个东西...
先给大家出个思考题吧,一个汉字占多少字节?是不是网上搜出的答案五花八门,那么读完本篇文章,我希望你至少可以准确知道这个问题的答案,我觉得就算是收获。
什么是编码
字符集与字符编码
字符编码的起源 ASCII
字符编码开始初步发展(欧洲等国)
字符编码继续发展(来中国了!)
字符编码终极发展(遍布全世界了)
字符编码的总结
为什么会产生乱码
如何解决乱码
附录 ASCII、ISO-8859-1 码表
文末小惊喜
计算机是用 0 和 1 这种二进制形式,来表示一切信息的。所以它需要对所有的信息进行编码,对整数、浮点数进行编码,对字符串进行编码,对声音、图片、视频进行编码。每一种编码都可以深入研究来品味,比如人们发明出补码来使计算机的减法变成加法,还有各种将声音、图片等看似不可能的媒体信息编码成 0 和 1。一切都很美妙,唯独字符编码很讨人厌,往往程序员们都不愿意碰,因为它实在是太乱了。
那今天就由我来帮你理一理。
一、什么是编码
这个问题很重要
编码是把数据从一种形式转换为另外一种形式的过程,而解码则是编码的你过程。
注意,这里可没有说计算机哟,所以编码是一个更大的概念,比如我们每个人都有名字,那你的名字就是你这个人的一种编码。你还有身份证号,那你的身份证号又是你的一种编码。别小看这个简单的例子,它能解释你经常混淆的两个概念。
二、字符集与字符编码
字符集是一个系统支持的所有抽象字符的集合,它是各种文字和符号的总称,比如 ASCII 字符集、GBK 字符集,这就好比刚刚说的所有人这个集合。
字符编码则是怎么把字符集里的这些字符一一用二进制表示的一个字典,或者说一个函数,比如 ASCll 字符编码、GBK 字符编码,这就好比刚刚说的名字表示法、身份证号表示法。
咦?ASCII 字符集对应的编码方式是 ASCII 字符编码,GBK 字符集对应的编码方式是 GBK 字符编码?没错,通常来说,字符集同时定义了一套同名的字符编码规则。有人就有疑问了,那人这个字符集,不是可以用名字和身份证号两种字符编码么?是的,字符也可以,比如 Unicode 字符集,就可以用 UTF-8、UTF-16 等多种字符编码来表示。
还需要注意的一点是,在计算机的世界里,不会有像名字表示法这样,一个名字可能对应好多人的情况,所以名字表示法在字符编码这里,就不是一个好的字符编码方式,自然也不会有人广泛采用了。
三、字符编码的起源 ASCII
世界上第一份字符集和编码标准,显然是由美国人起草的,就是大名鼎鼎的 ASCII,一共包含了 128 个字符以及对应的二进制,比如小写字母 a 对应 01100001。这 128 个字符包括了可显示的 26 个字母(大小写)、10 个数字、标点符号以及特殊的控制符,也就是英语与西欧语言中常见的字符,这 128 个字符用一个字节(可表示 256 个字符)来表示绰绰有余,所以当时只用了 7 位,还留了一个最高位当做奇偶校验。不奇怪,英语国家的人觉得这真的足够了,假如世界上所有人都用英语,那字符编码真的超级简洁,也就不会有什么乱码问题和这篇文章了。
每一种字符编码最好的描述方式就是简单粗暴的一个字典,或者说一张表,比如 ASCII,没什么可解释的,它就是一张表。编码就从右往左看,解码就从左往右看。详见附录 ASCII。
四、字符编码开始初步发展(欧洲)
EASCII:扩展的 ASCII
我们说 ASCII 发生于美国,因为一开始只有美国有计算机,所以 ASCII 足够了。可是随着计算机的普及,西欧等国家首先开始使用(注意这时候还没有中国)。西欧语言的字符虽然没有中文这么多,但有很多字符是 ASCII 表示不了的。于是他们就把 ASCII 扩充变成了 EASCII,这扩充的包括希腊字母、特殊的拉丁符号等。由于 ASCII 只占了 7 位,所以 EASCII 把第 8 位利用起来,仍然是一个字节来表示,这时表示的字符个数是 256。
但 EASCII 并没有成功,西欧国家以及各个 PC 厂商各自定义出了好多不同的编码字符集,这时候你自然就能想到,一定有一个组织站出来统一这个混乱的局面,制定一个标准,这个组织就是国际标准化组织 ISO 及国际电工委员会 IEC。
ISO-8859
这两个组织制定了一系列的 8 位字符集标准,叫做 ISO-8859。请注意,这叫一系列,我们常说的 ISO-8859-1 才是一个字符集标准,只是 ISO-8859 系列中的一个。之所以定一个系列,因为那时候还想着用单字节来编码,但除去 ASCII 占有的 0x00~0x7F,就只剩下 0x80~0xFF 可以使用了,比如将ISO-8859-1,就是向下兼容 ASCII 的字符集标准,其编码范围是 0x00~0xFF,0x00~0x7F 之间完全和 ASCII 一致,0x80~0x9F 之间是控制字符,0xA0~0xFF 之间是文字符号。
各个国家的符号都容纳进来显然是不够的,于是就分成了好多个版本,你是哪个国家的就用哪个。我们之所以经常提到 ISO-8859-1,是因为它适用于西欧国家,而英国就是西欧国家。
以下是全部的 ISO-8859 系列:
| 标准名称 | 别名 | 适用范围 |
|---|---|---|
| ISO/IEC 8859-1 | Latin-1 | 西欧语言 |
| ISO/IEC 8859-2 | Latin-2 | 中欧语言 |
| ISO/IEC 8859-3 | Latin-3 | 南欧语言。世界语也可用此字符集显示。 |
| ISO/IEC 8859-4 | Latin-4 | 北欧语言 |
| ISO/IEC 8859-5 | Cyrillic | 斯拉夫语言 |
| ISO/IEC 8859-6 | Arabic | 阿拉伯语 |
| ISO/IEC 8859-7 | Greek | 希腊语 |
| ISO/IEC 8859-8 | Hebrew | 希伯来语(视觉顺序) |
| ISO/IEC 8859-8-I | Hebrew-I | 希伯来语(逻辑顺序) |
| ISO/IEC 8859-9 | Latin-5 或 Turkish | 它把 Latin-1 的冰岛语字母换走,加入土耳其语字母 |
| ISO/IEC 8859-10 | Latin-6 或 Nordic | 北日耳曼语支,用来代替 Latin-4 |
| ISO/IEC 8859-11 | Thai | 泰语,从泰国的 TIS620 标准字集演化而来。 |
| ISO/IEC 8859-13 | Latin-7 或 Baltic Rim | 波罗的语族 |
| ISO/IEC 8859-14 | Latin-8 或 Celtic | 凯尔特语族 |
| ISO/IEC 8859-15 | Latin-9 | 西欧语言,加入 Latin-1 欠缺的芬兰语字母和大写法语重音字母,以及欧元(€)符号。 |
| ISO/IEC 8859-16 | Latin-10 | 东南欧语言。主要供罗马尼亚语使用,并加入欧元符号。 |
我们看到,ISO-8859-1 又叫做 Latin-1,所以现在你应该知道,有的地方比如 MySQL 里的字符集显示 Latin-1,不要陌生,他只是 ISO-8859-1 的别名。
还是那句话,字符编码就是一个字典或者对照表,说什么都不如列个表实在,ISO-8859-1 的对照表(只列出扩展了 ASCII 的部分)详见附录 ISO-8859-1。
五、字符编码继续发展(来中国了)
GB2312
计算机开水普及到了中国,于是一切就不一样了。原本用一个字节就解决所有的符号编码,在中国是行不通的。于是 1981 年国家标准化管理委员会定了一套字符集叫 GB2312,每个汉字符号由两个字节组成,注意!这里变成了两个字节。理论上它可以表示 65536 个字符,不过它只收录了 7445 个字符,6763 个汉字和 682 个其他字符,同时它能够兼容 ASCII。
GBK
GB2312 所收录的汉字已经覆盖中国大陆 99.75% 的使用频率,但是对一些罕见的字和繁体字还有很多少数民族使用的字符都没法处理,于是后来就在 GB2312 的基础上创建了一种叫 GBK 的字符编码,GBK 不仅收录了 27484 个汉字,同时还收录了藏文、蒙文、维吾尔文等主要的少数民族文字。GBK 是利用了 GB2312 中未被使用的编码空间上进行扩充,所以它能完全兼容 GB2312 和 ASCII。
BIG5
台湾地区繁体中文标准字符集,采用双字节编码,共收录 13053 个中文字,1984 年实施。
GB18030 编码
2000 年 3 月 17 日发布的汉字编码国家标准,是对 GBK 编码的扩充,覆盖中文、日文、朝鲜语和中国少数民族文字,其中收录 27484 个汉字。GB18030 字符集采用单字节、双字节和四字节三种方式对字符编码。兼容 GBK 和 GB2312 字符集。
中文字符集总结
简单总结下上面的就是,ASCII < GB2312 < GBK < GB18030,后者是前者的扩充,也即兼容了前者。然后 BIG5 是台湾字符集,单独的一套。
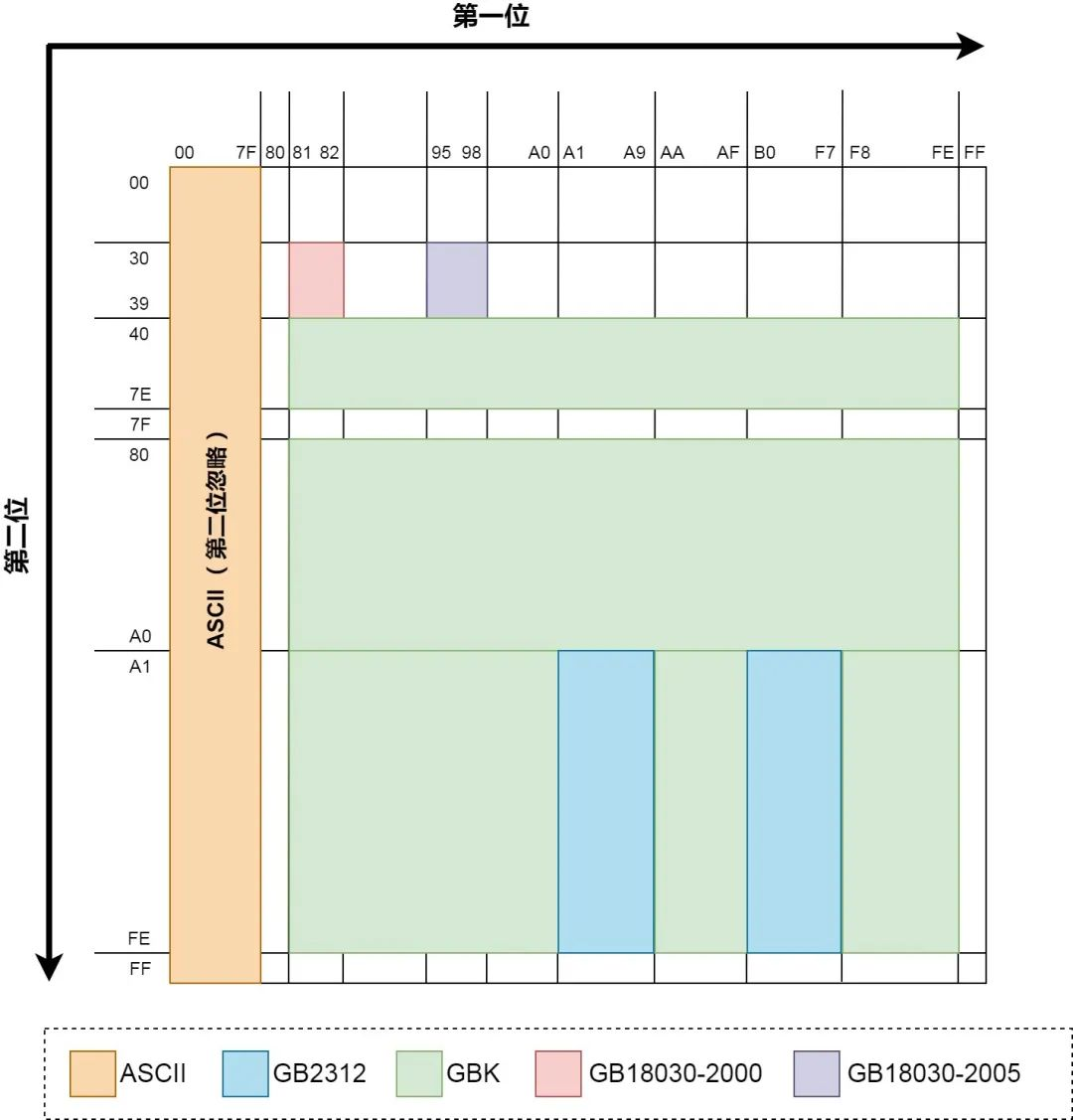
这里拿最常用的 GBK 编码举例,GBK 的中文编码是双字节来表示的,英文编码是用 ASCII 码表示的,既用单字节表示。但 GBK 编码表中也有英文字符的双字节表示形式,所以英文字母可以有 2 种 GBK 表示方式。为区分中文,将其最高位都定成 1。英文单字节最高位都为 0。当用 GBK 解码时,若高字节最高位为 0,则用 ASCII 码表解码;若高字节最高位为 1,则用 GBK 编码表解码。你可以看到上图中第一个字节在 00~7F(二进制 00000000~01111111,所以第一位是 0) 之间的都是 ASCII。
理论上说,中文字符编码也应该列一个对照表,无奈它实在是太多了,不但汉字数量多,而且编码方式也多。所以这里只列一下数量最少的 GB2312 ,而且用链接的形式给你。
GB2312 简体中文编码表
六、字符编码终极发展(遍布全球)
Unicode
跟 ISO-8859 的出现原因一样,只不过这次范围扩大到了全世界。当然世界各国都有自己国家的字符编码发展历史,这里就没必要一一展开了。1991 年,国际标准化组织和统一码联盟组织退出了 Unicode 项目,目的就是同一全世界的所有字符。
你可能知道 Unicode 分 UTF-8、UTF-16、UCS-2 等,而 ISO-8859 也分 ISO-8859-1、ISO-8859-2……你会不会觉得它们是一样的道理呢?错!
ISO-8859 是一个字符集的系列,分成 ISO-8859-1、ISO-8859-2 等好多字符集,而每个字符集对应的编码方式就是 ISO-8859-1 编码、ISO-8859-2 编码,是一对一的关系。
Unicode 本身就是一个字符集,是全世界所有字符的合集,它并不是字符集系列。而 Unicode 这个字符集特殊的地方在于,他的编码方式不叫 Unicode 编码,它的编码方式有很多种,分别是 UTF-8 编码、UTF-16 编码等。
所以字符集系列和字符集的区别,最好的例子就是 ISO-8859;而字符集和字符编码的区别,最好的例子就是 Unicode。
捋清了这个关系,下面我们就可以详细说说大家心心念念的 Unicode 了。Unicode 本身并没有规定一个字符究竟是怎么编码,甚至都没有规定用几个字节表示,所以也叫可变长度字符编码。Unicode 只规定了每个字符对应到唯一的代码值(code point),代码值从 0000~10FFFF 共 1114112 个值,你曾经看到的很讨人厌的 \u0300 这种,就是 Unicode 的代码值,这种代码值要想变成真正存储在机器里的字符串,一定要进行某种编码,如下。
ustr = \u0030;
str = ustr.encode("utf-8")
真正存储的时候需要多少个字节是由具体的编码格式决定的。比如:字符 「A」用 UTF-8 的格式编码来存储就只占用 1 个字节,用 UTF-16 就占用 2 个字节,而用 UTF-32 存储就占用 4 个字节。而 UTF-8 本身,又不是固定长度的,也是可变长度的。
| Unicode | UTF-8 | byte 数 | 备注 |
|---|---|---|---|
| 0000~007F | 0XXX XXXX | 1 | |
| 0080~07FF | 110X XXXX 10XX XXXX | 2 | |
| 0800~FFFF | 1110 XXXX 10XX XXXX 10XX XXXX | 3 | 基本定义范围:0~FFFF |
| 1 0000~1F FFFF | 1111 0XXX 10XX XXXX 10XX XXXX 10XX XXXX | 4 | Unicode6.1 定义范围:0~10 FFFF |
所以从这里你可以看出,一般一种编码方式是如何兼容其他编码的,又是如何可变长度的。UTF-8 编码的第一位如果是 0,则只有一个字节,跟 ASCII 编码完全一样,所以兼容了。如果是 110 开头,则是两个字节,以此类推如上表所示。所以开头几位的值,是编码本身,同时又是判断是几个字节数的推码,可谓是一箭双雕。这种设计颇有点像 CPU 中的相联存储器的概念。
所以如果再有人问你这个问题:UTF-8 占几个字节?汉字到底占几个字节?你就可以这样专业而又不装逼的回答:
首先汉字占几个字节这个问题本身就不明确,应该问 Unicode 字符集中的汉字用 UTF-8 编码方式编码,占几个字节?
那这个问题就演化成了 UTF-8 占几个字节。UTF-8 是可变长度字符编码,所以只能说占 1~4 个字节。
单字节可编码的 Unicode 范围:\u0000~\u007F(0~127)
双字节可编码的 Unicode 范围:\u0080~\u07FF(128~2047)
三字节可编码的 Unicode 范围:\u0800~\uFFFF(2048~65535)
四字节可编码的 Unicode 范围:\u10000~\u1FFFFF(65536~2097151)
那基于各种历史的或者是合理性原因,人们把占用 1 个字节的给了 ASCII;占 2 个字节的给了拉丁文、希腊文、西里尔字母、亚美尼亚语、希伯来文等;占 3 个字节的给了大部分汉字,基本等同于 GBK,含 21000 多个汉字;占 4 个字节的中日韩超大字符集里面的汉字,有 5 万多个。
所以,汉字占三个字节这句话,应该说成
Unicode 字符集中的大部分汉字,如果用 UTF-8 编码的话,是占 3 个字节的。而 UTF-8 编码本身,是 1~4 个字节的可变长度字符编码。
七、字符编码的总结
按时间线
美国线:ASCII --> EASCII --> ISO-8859 --> Unicode
中国线:GB2312 --> GBK --> GB18030 --> Unicode
他国线:... ... --> Unicode
按含义
字符集系列(对应 n 多个字符集):ISO-8859 系列
字符集(对应 n 多个字符编码):ASCII、ISO-8859-1、GBK、Unicode
字符编码:ASCII、ISO-8859-1、GBK、UTF-8、UTF-16
按字节数
单字节:ASCII、ISO-8859 系列
双字节:GB2312、GBK
可变字节:UTF-8、UTF-16
八、为什么会产生乱码
前面说过,编码和解码,就是一个查表的过程,正着查是二进制的值到字符,反着查是字符到二进制的数值。所谓乱码,就是编码和解码查的不是一张表嘛。就好比你叫你丈夫的爹为“公公”,你是查现代汉语词典编码出的“公公”两个字,人家爸爸却拿着古代汉语词典来解码你这个“公公”的含义,这不乱才怪嘛。
自己构造一个乱码很简单,我们用 UTF-8 来编码一个“你好”这两个字,再用 GBK 解码来阅读,看看会怎么样。
首先新建一个 txt 文件,就叫【乱码.txt】吧,然后用二进制方式打开它(我用的是 Notepad++,下载了 Hex-Editor 插件)。
我们查 UTF-8 编码字典,发现你好两个字的编码是“E4BDA0”、“E5A5BD”,我们将编码输入。
好吧你说这哪是 2 进制啊,这不是 16 进制么。那我们就直接一点,用纯 2 进制的方式输入,“111001001011110110100000”,“111001011010010110111101”。
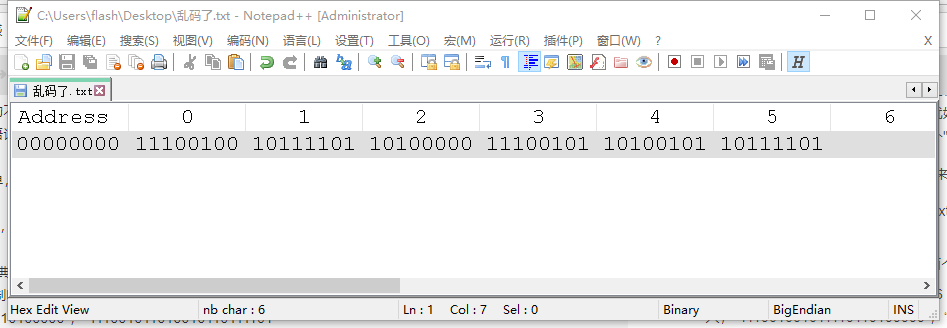
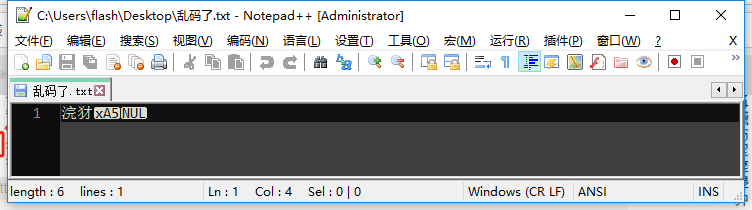
返回正常的文本状态,选择用 UTF-8 编码方式查看,发现是正常的“你好”两个字。但如果切换成 GBK(这里我选择了 GB2312,一样的),就变成了奇怪的文字。
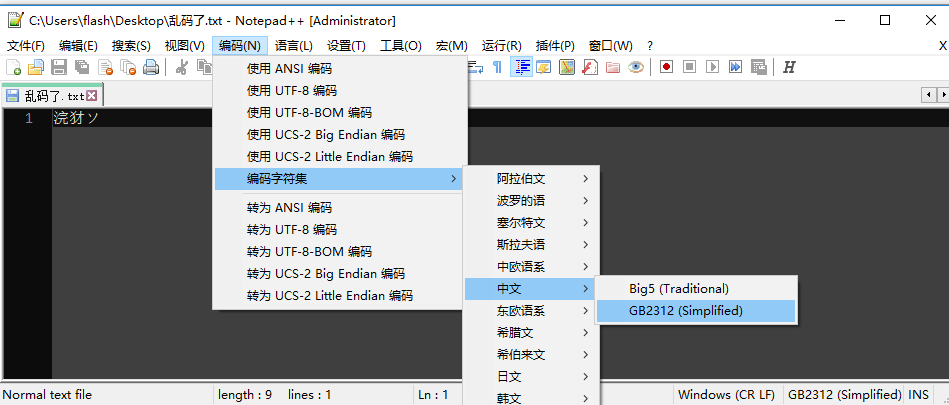
这很好理解,UTF-8 编码汉字是 3 个字节,刚刚我们编码了“你好”,对应的字节序列是 “E4BDA0”、“E5A5BD”,一共 6 个字节。GBK 编码汉字是 2 个字节,于是解读成了 “E4BD“、”A0E5“、”A5BD”,三个汉字。那我们查 GBK 码表:


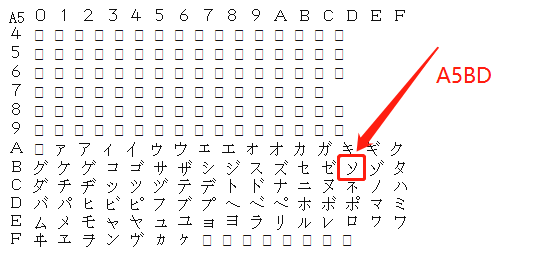
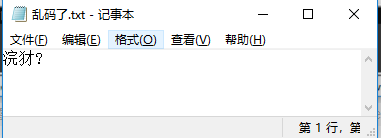
你有没有发现,居然跟我们看到的是一样的!这还是比较有好的乱码,起码还能对应上真正码表中存在的汉字。有的乱码字节数都不对,或者干脆码表中查不到,就难看极了。这就要看各个不同的文本查看软件怎么处理了,比如我 GBK 本来是双字节的,我硬生生把一个字的后一个字节删了,这种情况 Notepad++ 还算友好,可以让你看到是因为少了一个字节出的问题,如果用记事本打开,就是一个大写的 “?”。
编码我们都理解了,就是最终写在计算机内存里的 01010 字节序列。而对于解码,似乎还是有一点迷惑,解码解成了什么呢?要相信自己的判断,没错,解码就是解成了我们眼睛看到的这些东西,他们的本质就是屏幕上显示的光点。比如说汉字,其实解码我们所查的表,最终对应的就是一个 n*n 的矩阵,最终再经过一些列的转换,由串口输出到显示屏上,矩阵中的 1 就代表有,0 就代表无,经过放大缩小等线性变换,最终达到屏幕上的一个个小光点上,就变成了我们看到的字。老一辈的计算机从业者,有很多人力需要去造这张表,就是把每个编码对应的这个矩阵画出来,最终存成字库。如果你听老一辈的计算机从业者讲述,将听到很多关于这里的故事,像“区位码”,这里我就不展开说了,其实也是因为没经历过,不太了解。
九、如何解决乱码
上一环节我给你展示了一个文本文件如何产生了乱码,那如何解决文本文件的编码呢,很简单,保存的时候用什么格式编码保存的,读取的时候就用什么时候读。比如 Notepad++ 就很清晰,保存和读取都在【编码】这个菜单栏里。
对于记事本,我们似乎没看到编码这一项,其实如果你选择另存为,一般会有四个编码选项让你选择,分别是 ANSI、Unicode、Unicode big endian、UTF-8。如果你不选择的话,默认保存是用 ANSI,那 windows 平台一般是指的 GBK。
这里你可能会困惑,刚刚不是说了 Unicode 不是字符集编码,而只是字符集么,这里怎么又出现在编码了。没错,这就是字符编码比较乱的地方之一,命名不规范,有很多潜规则。比如这个记事本的 Unicode:Windows 平台下默认的 Unicode 编码为 Little Endian 的 UTF-16,实际上它还是指的是一个具体的编码格式,只不过被潜规则在 Windows 平台下了,让很多人误以为 Unicode 就是特指某种具体的编码方式。
浏览器
刚刚解释了下记事本的乱码解决,其实所有工具都是一样的,只要有文本阅读的地方,一般都会有设置编码的地方。那么我们来看一下最常见也最容易出错的浏览器。我们打开一个网页发现是乱码,这尤其经常发生在我们开发测试阶段,那么我们先抛离服务端,单纯创建一个乱码的页面。
用 Notepad++ 写一个以 UTF-8 编码的文件 test.html:
<!DOCTYPE HTML>
<html>
<head></head>
<body>
你好
</body>
</html>
用 IE 浏览器打开,直接乱码:
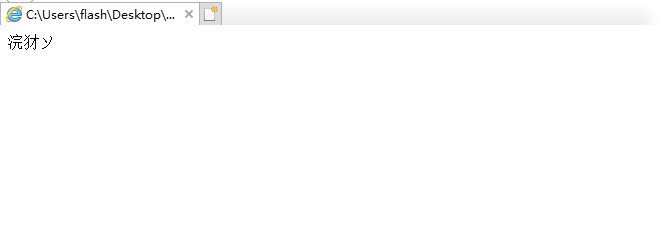
而如果我们重新用 GBK 编码写一个一模一样的文件,再用 IE 打开,正常。这是为什么呢?原因很简单,IE 浏览器默认用 GBK 去解码一个 HTML。这又是一个潜规则。
而我们怎么才能让它显示正确呢?你可以强行改浏览器的编码方式,但你搞一个服务,总不能让用户去做这个事情吧?一个个试哪个编码方式正确?即使浏览器功能强大到可以智能分析编码,也最好有一个标识来告诉浏览器这个 HTML 是如何编码的,这个标识就是:
<meta charset = "utf-8"/>
把它加载 header 中:
<!DOCTYPE HTML>
<html>
<head>
<meta charset = "utf-8"/>
</head>
<body>
你好
</body>
</html>
再用 IE 浏览器打开,正常!
那么我们就知道了,页面产生乱码,不是我们的问题,要么是服务端没有设置这个 meta charset,要么就是服务端设置了,但实际上编码响应流的时候却用了其他编码方式。当然我们也能自己强行解决,那就是设置浏览器的编码方式,不同浏览器设置编码方式的位置不一样,而且我个人感觉也很难找,不同浏览器的默认编码方式也不同,而且还有可能有 Unicode 指的是 UTF-8 这样的潜规则。所以为了彻底杜绝这个问题,还是在 HTML 文件里面告知为好。
服务器
既然浏览的页面乱码怪服务端,那我就不得不说说服务端这边的事。
我们写一个 Spring Boot 程序:
@SpringBootApplication
@Controller
public class JavamateSpringbootApplication {
public static void main(String[] args) {
SpringApplication.run(JavamateSpringbootApplication.class, args);
}
@RequestMapping("hello")
@ResponseBody
public String hello() {
return "你好";
}
}
浏览器访问 /hello,完美显示“你好”,并没有乱码。
正因为 Spring Boot 为我们做了太多事,才这么容易发生不乱码的情况。其实与其说为什么会乱码,不如解释解释为什么这段代码没有乱码。
首先没有乱码,一定是编解码用的是同一套。那编码是什么呢,这里就又涉及到潜规则了,Spring Boot 默认情况下,@ResponseBody 会用 UTF-8 对字符串进行编码,而且会为响应体设置一个相应头:
Content-Type: text/javascript; charset=UTF-8
解码方面,IE 浏览器默认是 GBK,但你响应体里有这个头了,那 IE 会改成用 UTF-8 解码。
不知道你有没有经历过 Tomcat 时代的 ISO-8859-1 乱码的时代,那时候没有这些强大的开发框架,好多地方可能要 response 直接 write 数据出去,而 Tomcat 此时的默认编码是 ISO-8859-1。所以那时候好多地方都需要手动改成 UTF-8。由于 UTF-8 渐渐变成了国际标准,Spring Boot 框架也将内嵌的 Tomcat 默认编码格式改成了 UTF-8。
那我们怎么搞出一个乱码呢?很简单,我们用默认编码格式为 ISO-8859-1 的 Response 直接 write 出去,而不依赖于框架。
@RequestMapping("hello2")
public void hello2(HttpServletResponse response) throws IOException {
PrintWriter writer = response.getWriter();
writer.println("你好");
writer.flush();
}
浏览器打开,直接乱码。
其实更直观的写法应该是这样,抛开所有默认的外套:
@RequestMapping("hello2")
public void hello2(HttpServletResponse response) throws IOException {
response.setCharacterEncoding("gbk");
response.addHeader("Content-Type", "text/html");
ServletOutputStream out = response.getOutputStream();
out.write("你好".getBytes("utf-8"));
out.flush();
}
浏览器打开,看到了我们熟悉的乱码。
浣犲ソ
我们看到代码中,直接表达了:将“你好”用 UTF-8 格式编码,并通过响应头告诉浏览器,用 GBK 的方式解码。这自然就乱码了。
现在的服务端框架,已经达成了用 UTF-8 作为编解码标准的共识,而且 String 的 getBytes 方法默认的也是 UTF-8,也可以通过 file.encoding 参数配置。所以现在基本不用担心乱码问题了。在 Tomcat 乱码满天飞的时代,解决乱码问题也无非是:
看字符串本身的编码
看设置回响应头的编码
看 HTML 文件的 meta 属性的编码
十、附录
ASCII 和 ISO-8859-1 的编码表
ASCII
| Bin | Oct | Dec | Hex | 缩写/字符 | 解释 |
|---|---|---|---|---|---|
| (二进制) | (八进制) | (十进制) | (十六进制) | ||
| 0000 0000 | 0 | 0 | 0x00 | NUL(null) | 空字符 |
| 0000 0001 | 1 | 1 | 0x01 | SOH(start of headline) | 标题开始 |
| 0000 0010 | 2 | 2 | 0x02 | STX (start of text) | 正文开始 |
| 0000 0011 | 3 | 3 | 0x03 | ETX (end of text) | 正文结束 |
| 0000 0100 | 4 | 4 | 0x04 | EOT (end of transmission) | 传输结束 |
| 0000 0101 | 5 | 5 | 0x05 | ENQ (enquiry) | 请求 |
| 0000 0110 | 6 | 6 | 0x06 | ACK (acknowledge) | 收到通知 |
| 0000 0111 | 7 | 7 | 0x07 | BEL (bell) | 响铃 |
| 0000 1000 | 10 | 8 | 0x08 | BS (backspace) | 退格 |
| 0000 1001 | 11 | 9 | 0x09 | HT (horizontal tab) | 水平制表符 |
| 0000 1010 | 12 | 10 | 0x0A | LF (NL line feed, new line) | 换行键 |
| 0000 1011 | 13 | 11 | 0x0B | VT (vertical tab) | 垂直制表符 |
| 0000 1100 | 14 | 12 | 0x0C | FF (NP form feed, new page) | 换页键 |
| 0000 1101 | 15 | 13 | 0x0D | CR (carriage return) | 回车键 |
| 0000 1110 | 16 | 14 | 0x0E | SO (shift out) | 不用切换 |
| 0000 1111 | 17 | 15 | 0x0F | SI (shift in) | 启用切换 |
| 0001 0000 | 20 | 16 | 0x10 | DLE (data link escape) | 数据链路转义 |
| 0001 0001 | 21 | 17 | 0x11 | DC1 (device control 1) | 设备控制 1 |
| 0001 0010 | 22 | 18 | 0x12 | DC2 (device control 2) | 设备控制 2 |
| 0001 0011 | 23 | 19 | 0x13 | DC3 (device control 3) | 设备控制 3 |
| 0001 0100 | 24 | 20 | 0x14 | DC4 (device control 4) | 设备控制 4 |
| 0001 0101 | 25 | 21 | 0x15 | NAK (negative acknowledge) | 拒绝接收 |
| 0001 0110 | 26 | 22 | 0x16 | SYN (synchronous idle) | 同步空闲 |
| 0001 0111 | 27 | 23 | 0x17 | ETB (end of trans. block) | 结束传输块 |
| 0001 1000 | 30 | 24 | 0x18 | CAN (cancel) | 取消 |
| 0001 1001 | 31 | 25 | 0x19 | EM (end of medium) | 媒介结束 |
| 0001 1010 | 32 | 26 | 0x1A | SUB (substitute) | 代替 |
| 0001 1011 | 33 | 27 | 0x1B | ESC (escape) | 换码(溢出) |
| 0001 1100 | 34 | 28 | 0x1C | FS (file separator) | 文件分隔符 |
| 0001 1101 | 35 | 29 | 0x1D | GS (group separator) | 分组符 |
| 0001 1110 | 36 | 30 | 0x1E | RS (record separator) | 记录分隔符 |
| 0001 1111 | 37 | 31 | 0x1F | US (unit separator) | 单元分隔符 |
| 0010 0000 | 40 | 32 | 0x20 | (space) | 空格 |
| 0010 0001 | 41 | 33 | 0x21 | ! | 叹号 |
| 0010 0010 | 42 | 34 | 0x22 | " | 双引号 |
| 0010 0011 | 43 | 35 | 0x23 | # | 井号 |
| 0010 0100 | 44 | 36 | 0x24 | $ | 美元符 |
| 0010 0101 | 45 | 37 | 0x25 | % | 百分号 |
| 0010 0110 | 46 | 38 | 0x26 | & | 和号 |
| 0010 0111 | 47 | 39 | 0x27 | ' | 闭单引号 |
| 0010 1000 | 50 | 40 | 0x28 | ( | 开括号 |
| 0010 1001 | 51 | 41 | 0x29 | ) | 闭括号 |
| 0010 1010 | 52 | 42 | 0x2A | * | 星号 |
| 0010 1011 | 53 | 43 | 0x2B | + | 加号 |
| 0010 1100 | 54 | 44 | 0x2C | , | 逗号 |
| 0010 1101 | 55 | 45 | 0x2D | - | 减号/破折号 |
| 0010 1110 | 56 | 46 | 0x2E | . | 句号 |
| 0010 1111 | 57 | 47 | 0x2F | / | 斜杠 |
| 0011 0000 | 60 | 48 | 0x30 | 0 | 字符 0 |
| 0011 0001 | 61 | 49 | 0x31 | 1 | 字符 1 |
| 0011 0010 | 62 | 50 | 0x32 | 2 | 字符 2 |
| 0011 0011 | 63 | 51 | 0x33 | 3 | 字符 3 |
| 0011 0100 | 64 | 52 | 0x34 | 4 | 字符 4 |
| 0011 0101 | 65 | 53 | 0x35 | 5 | 字符 5 |
| 0011 0110 | 66 | 54 | 0x36 | 6 | 字符 6 |
| 0011 0111 | 67 | 55 | 0x37 | 7 | 字符 7 |
| 0011 1000 | 70 | 56 | 0x38 | 8 | 字符 8 |
| 0011 1001 | 71 | 57 | 0x39 | 9 | 字符 9 |
| 0011 1010 | 72 | 58 | 0x3A | : | 冒号 |
| 0011 1011 | 73 | 59 | 0x3B | ; | 分号 |
| 0011 1100 | 74 | 60 | 0x3C | < | 小于 |
| 0011 1101 | 75 | 61 | 0x3D | = | 等号 |
| 0011 1110 | 76 | 62 | 0x3E | > | 大于 |
| 0011 1111 | 77 | 63 | 0x3F | ? | 问号 |
| 0100 0000 | 100 | 64 | 0x40 | @ | 电子邮件符号 |
| 0100 0001 | 101 | 65 | 0x41 | A | 大写字母 A |
| 0100 0010 | 102 | 66 | 0x42 | B | 大写字母 B |
| 0100 0011 | 103 | 67 | 0x43 | C | 大写字母 C |
| 0100 0100 | 104 | 68 | 0x44 | D | 大写字母 D |
| 0100 0101 | 105 | 69 | 0x45 | E | 大写字母 E |
| 0100 0110 | 106 | 70 | 0x46 | F | 大写字母 F |
| 0100 0111 | 107 | 71 | 0x47 | G | 大写字母 G |
| 0100 1000 | 110 | 72 | 0x48 | H | 大写字母 H |
| 0100 1001 | 111 | 73 | 0x49 | I | 大写字母 I |
| 1001010 | 112 | 74 | 0x4A | J | 大写字母 J |
| 0100 1011 | 113 | 75 | 0x4B | K | 大写字母 K |
| 0100 1100 | 114 | 76 | 0x4C | L | 大写字母 L |
| 0100 1101 | 115 | 77 | 0x4D | M | 大写字母 M |
| 0100 1110 | 116 | 78 | 0x4E | N | 大写字母 N |
| 0100 1111 | 117 | 79 | 0x4F | O | 大写字母 O |
| 0101 0000 | 120 | 80 | 0x50 | P | 大写字母 P |
| 0101 0001 | 121 | 81 | 0x51 | Q | 大写字母 Q |
| 0101 0010 | 122 | 82 | 0x52 | R | 大写字母 R |
| 0101 0011 | 123 | 83 | 0x53 | S | 大写字母 S |
| 0101 0100 | 124 | 84 | 0x54 | T | 大写字母 T |
| 0101 0101 | 125 | 85 | 0x55 | U | 大写字母 U |
| 0101 0110 | 126 | 86 | 0x56 | V | 大写字母 V |
| 0101 0111 | 127 | 87 | 0x57 | W | 大写字母 W |
| 0101 1000 | 130 | 88 | 0x58 | X | 大写字母 X |
| 0101 1001 | 131 | 89 | 0x59 | Y | 大写字母 Y |
| 0101 1010 | 132 | 90 | 0x5A | Z | 大写字母 Z |
| 0101 1011 | 133 | 91 | 0x5B | [ | 开方括号 |
| 0101 1100 | 134 | 92 | 0x5C | \ | 反斜杠 |
| 0101 1101 | 135 | 93 | 0x5D | ] | 闭方括号 |
| 0101 1110 | 136 | 94 | 0x5E | ^ | 脱字符 |
| 0101 1111 | 137 | 95 | 0x5F | _ | 下划线 |
| 0110 0000 | 140 | 96 | 0x60 | ` | 开单引号 |
| 0110 0001 | 141 | 97 | 0x61 | a | 小写字母 a |
| 0110 0010 | 142 | 98 | 0x62 | b | 小写字母 b |
| 0110 0011 | 143 | 99 | 0x63 | c | 小写字母 c |
| 0110 0100 | 144 | 100 | 0x64 | d | 小写字母 d |
| 0110 0101 | 145 | 101 | 0x65 | e | 小写字母 e |
| 0110 0110 | 146 | 102 | 0x66 | f | 小写字母 f |
| 0110 0111 | 147 | 103 | 0x67 | g | 小写字母 g |
| 0110 1000 | 150 | 104 | 0x68 | h | 小写字母 h |
| 0110 1001 | 151 | 105 | 0x69 | i | 小写字母 i |
| 0110 1010 | 152 | 106 | 0x6A | j | 小写字母 j |
| 0110 1011 | 153 | 107 | 0x6B | k | 小写字母 k |
| 0110 1100 | 154 | 108 | 0x6C | l | 小写字母 l |
| 0110 1101 | 155 | 109 | 0x6D | m | 小写字母 m |
| 0110 1110 | 156 | 110 | 0x6E | n | 小写字母 n |
| 0110 1111 | 157 | 111 | 0x6F | o | 小写字母 o |
| 0111 0000 | 160 | 112 | 0x70 | p | 小写字母 p |
| 0111 0001 | 161 | 113 | 0x71 | q | 小写字母 q |
| 0111 0010 | 162 | 114 | 0x72 | r | 小写字母 r |
| 0111 0011 | 163 | 115 | 0x73 | s | 小写字母 s |
| 0111 0100 | 164 | 116 | 0x74 | t | 小写字母 t |
| 0111 0101 | 165 | 117 | 0x75 | u | 小写字母 u |
| 0111 0110 | 166 | 118 | 0x76 | v | 小写字母 v |
| 0111 0111 | 167 | 119 | 0x77 | w | 小写字母 w |
| 0111 1000 | 170 | 120 | 0x78 | x | 小写字母 x |
| 0111 1001 | 171 | 121 | 0x79 | y | 小写字母 y |
| 0111 1010 | 172 | 122 | 0x7A | z | 小写字母 z |
| 0111 1011 | 173 | 123 | 0x7B | { | 开花括号 |
| 0111 1100 | 174 | 124 | 0x7C | \ | |
| 0111 1101 | 175 | 125 | 0x7D | } | 闭花括号 |
| 0111 1110 | 176 | 126 | 0x7E | ~ | 波浪号 |
| 0111 1111 | 177 | 127 | 0x7F | DEL (delete) | 删除 |
ISO-8859-1
| DEC | OCT | HEX | BIN | Symbol | Description |
|---|---|---|---|---|---|
| 128 | 200 | 80 | 10000000 | € | Euro sign |
| 129 | 201 | 81 | 10000001 | ||
| 130 | 202 | 82 | 10000010 | Single low-9 quotation mark | |
| 131 | 203 | 83 | 10000011 | ƒ | Latin small letter f with hook |
| 132 | 204 | 84 | 10000100 | „ | Double low-9 quotation mark |
| 133 | 205 | 85 | 10000101 | … | Horizontal ellipsis |
| 134 | 206 | 86 | 10000110 | † | Dagger |
| 135 | 207 | 87 | 10000111 | ‡ | Double dagger |
| 136 | 210 | 88 | 10001000 | ˆ | Modifier letter circumflex accent |
| 137 | 211 | 89 | 10001001 | ‰ | Per mille sign |
| 138 | 212 | 8A | 10001010 | Š | Latin capital letter S with caron |
| 139 | 213 | 8B | 10001011 | ‹ | Single left-pointing angle quotation |
| 140 | 214 | 8C | 10001100 | Π| Latin capital ligature OE |
| 141 | 215 | 8D | 10001101 | ||
| 142 | 216 | 8E | 10001110 | Ž | Latin captial letter Z with caron |
| 143 | 217 | 8F | 10001111 | ||
| 144 | 220 | 90 | 10010000 | ||
| 145 | 221 | 91 | 10010001 | Left single quotation mark | |
| 146 | 222 | 92 | 10010010 | Right single quotation mark | |
| 147 | 223 | 93 | 10010011 | “ | Left double quotation mark |
| 148 | 224 | 94 | 10010100 | ” | Right double quotation mark |
| 149 | 225 | 95 | 10010101 | • | Bullet |
| 150 | 226 | 96 | 10010110 | – | En dash |
| 151 | 227 | 97 | 10010111 | — | Em dash |
| 152 | 230 | 98 | 10011000 | ˜ | Small tilde |
| 153 | 231 | 99 | 10011001 | ™ | Trade mark sign |
| 154 | 232 | 9A | 10011010 | š | Latin small letter S with caron |
| 155 | 233 | 9B | 10011011 | › | Single right-pointing angle quotation mark |
| 156 | 234 | 9C | 10011100 | œ | Latin small ligature oe |
| 157 | 235 | 9D | 10011101 | ||
| 158 | 236 | 9E | 10011110 | ž | Latin small letter z with caron |
| 159 | 237 | 9F | 10011111 | Ÿ | Latin capital letter Y with diaeresis |
| 160 | 240 | A0 | 10100000 | Non-breaking space | |
| 161 | 241 | A1 | 10100001 | ¡ | Inverted exclamation mark |
| 162 | 242 | A2 | 10100010 | ¢ | Cent sign |
| 163 | 243 | A3 | 10100011 | £ | Pound sign |
| 164 | 244 | A4 | 10100100 | ¤ | Currency sign |
| 165 | 245 | A5 | 10100101 | ¥ | Yen sign |
| 166 | 246 | A6 | 10100110 | ¦ | Pipe, Broken vertical bar |
| 167 | 247 | A7 | 10100111 | § | Section sign |
| 168 | 250 | A8 | 10101000 | ¨ | Spacing diaeresis - umlaut |
| 169 | 251 | A9 | 10101001 | © | Copyright sign |
| 170 | 252 | AA | 10101010 | ª | Feminine ordinal indicator |
| 171 | 253 | AB | 10101011 | « | Left double angle quotes |
| 172 | 254 | AC | 10101100 | ¬ | Not sign |
| 173 | 255 | AD | 10101101 | Soft hyphen | |
| 174 | 256 | AE | 10101110 | ® | Registered trade mark sign |
| 175 | 257 | AF | 10101111 | ¯ | Spacing macron - overline |
| 176 | 260 | B0 | 10110000 | ° | Degree sign |
| 177 | 261 | B1 | 10110001 | ± | Plus-or-minus sign |
| 178 | 262 | B2 | 10110010 | ² | Superscript two - squared |
| 179 | 263 | B3 | 10110011 | ³ | Superscript three - cubed |
| 180 | 264 | B4 | 10110100 | ´ | Acute accent - spacing acute |
| 181 | 265 | B5 | 10110101 | µ | Micro sign |
| 182 | 266 | B6 | 10110110 | ¶ | Pilcrow sign - paragraph sign |
| 183 | 267 | B7 | 10110111 | · | Middle dot - Georgian comma |
| 184 | 270 | B8 | 10111000 | ¸ | Spacing cedilla |
| 185 | 271 | B9 | 10111001 | ¹ | Superscript one |
| 186 | 272 | BA | 10111010 | º | Masculine ordinal indicator |
| 187 | 273 | BB | 10111011 | » | Right double angle quotes |
| 188 | 274 | BC | 10111100 | ¼ | Fraction one quarter |
| 189 | 275 | BD | 10111101 | ½ | Fraction one half |
| 190 | 276 | BE | 10111110 | ¾ | Fraction three quarters |
| 191 | 277 | BF | 10111111 | ¿ | Inverted question mark |
| 192 | 300 | C0 | 11000000 | À | Latin capital letter A with grave |
| 193 | 301 | C1 | 11000001 | Á | Latin capital letter A with acute |
| 194 | 302 | C2 | 11000010 | Â | Latin capital letter A with circumflex |
| 195 | 303 | C3 | 11000011 | Ã | Latin capital letter A with tilde |
| 196 | 304 | C4 | 11000100 | Ä | Latin capital letter A with diaeresis |
| 197 | 305 | C5 | 11000101 | Å | Latin capital letter A with ring above |
| 198 | 306 | C6 | 11000110 | Æ | Latin capital letter AE |
| 199 | 307 | C7 | 11000111 | Ç | Latin capital letter C with cedilla |
| 200 | 310 | C8 | 11001000 | È | Latin capital letter E with grave |
| 201 | 311 | C9 | 11001001 | É | Latin capital letter E with acute |
| 202 | 312 | CA | 11001010 | Ê | Latin capital letter E with circumflex |
| 203 | 313 | CB | 11001011 | Ë | Latin capital letter E with diaeresis |
| 204 | 314 | CC | 11001100 | Ì | Latin capital letter I with grave |
| 205 | 315 | CD | 11001101 | Í | Latin capital letter I with acute |
| 206 | 316 | CE | 11001110 | Î | Latin capital letter I with circumflex |
| 207 | 317 | CF | 11001111 | Ï | Latin capital letter I with diaeresis |
| 208 | 320 | D0 | 11010000 | Ð | Latin capital letter ETH |
| 209 | 321 | D1 | 11010001 | Ñ | Latin capital letter N with tilde |
| 210 | 322 | D2 | 11010010 | Ò | Latin capital letter O with grave |
| 211 | 323 | D3 | 11010011 | Ó | Latin capital letter O with acute |
| 212 | 324 | D4 | 11010100 | Ô | Latin capital letter O with circumflex |
| 213 | 325 | D5 | 11010101 | Õ | Latin capital letter O with tilde |
| 214 | 326 | D6 | 11010110 | Ö | Latin capital letter O with diaeresis |
| 215 | 327 | D7 | 11010111 | × | Multiplication sign |
| 216 | 330 | D8 | 11011000 | Ø | Latin capital letter O with slash |
| 217 | 331 | D9 | 11011001 | Ù | Latin capital letter U with grave |
| 218 | 332 | DA | 11011010 | Ú | Latin capital letter U with acute |
| 219 | 333 | DB | 11011011 | Û | Latin capital letter U with circumflex |
| 220 | 334 | DC | 11011100 | Ü | Latin capital letter U with diaeresis |
| 221 | 335 | DD | 11011101 | Ý | Latin capital letter Y with acute |
| 222 | 336 | DE | 11011110 | Þ | Latin capital letter THORN |
| 223 | 337 | DF | 11011111 | ß | Latin small letter sharp s - ess-zed |
| 224 | 340 | E0 | 11100000 | à | Latin small letter a with grave |
| 225 | 341 | E1 | 11100001 | á | Latin small letter a with acute |
| 226 | 342 | E2 | 11100010 | â | Latin small letter a with circumflex |
| 227 | 343 | E3 | 11100011 | ã | Latin small letter a with tilde |
| 228 | 344 | E4 | 11100100 | ä | Latin small letter a with diaeresis |
| 229 | 345 | E5 | 11100101 | å | Latin small letter a with ring above |
| 230 | 346 | E6 | 11100110 | æ | Latin small letter ae |
| 231 | 347 | E7 | 11100111 | ç | Latin small letter c with cedilla |
| 232 | 350 | E8 | 11101000 | è | Latin small letter e with grave |
| 233 | 351 | E9 | 11101001 | é | Latin small letter e with acute |
| 234 | 352 | EA | 11101010 | ê | Latin small letter e with circumflex |
| 235 | 353 | EB | 11101011 | ë | Latin small letter e with diaeresis |
| 236 | 354 | EC | 11101100 | ì | Latin small letter i with grave |
| 237 | 355 | ED | 11101101 | í | Latin small letter i with acute |
| 238 | 356 | EE | 11101110 | î | Latin small letter i with circumflex |
| 239 | 357 | EF | 11101111 | ï | Latin small letter i with diaeresis |
| 240 | 360 | F0 | 11110000 | ð | Latin small letter eth |
| 241 | 361 | F1 | 11110001 | ñ | Latin small letter n with tilde |
| 242 | 362 | F2 | 11110010 | ò | Latin small letter o with grave |
| 243 | 363 | F3 | 11110011 | ó | Latin small letter o with acute |
| 244 | 364 | F4 | 11110100 | ô | Latin small letter o with circumflex |
| 245 | 365 | F5 | 11110101 | õ | Latin small letter o with tilde |
| 246 | 366 | F6 | 11110110 | ö | Latin small letter o with diaeresis |
| 247 | 367 | F7 | 11110111 | ÷ | Division sign |
| 248 | 370 | F8 | 11111000 | ø | Latin small letter o with slash |
| 249 | 371 | F9 | 11111001 | ù | Latin small letter u with grave |
| 250 | 372 | FA | 11111010 | ú | Latin small letter u with acute |
| 251 | 373 | FB | 11111011 | û | Latin small letter u with circumflex |
| 252 | 374 | FC | 11111100 | ü | Latin small letter u with diaeresis |
| 253 | 375 | FD | 11111101 | ý | Latin small letter y with acute |
| 254 | 376 | FE | 11111110 | þ | Latin small letter thorn |
| 255 | 377 | FF | 11111111 | ÿ | Latin small letter y with diaeresis |

















 7778
7778

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









