







前言:
我们学习一个算法总是要有个指标或者多个指标来衡量一下算的好不好,不同的机器学习问题就有了不同的努力目标,今天我们就来聊一聊回归意义下的损失函数、正则化的前世今生,从哪里来,到哪里去。
一.L1、L2下的Lasso Regression和Ridge Regression
对于机器学习,谈到正则化,首先映入脑子的可能是L1正则化、L2正则化,接着又跑出来Lasso Regression、Ridge Regression,那么恭喜你,你已经走在了机器学习、人工智能的康庄大道上了,至少短期来看这条路还是不错滴。
下面我们就正式开聊,小板凳走起。
介于大家可能对L1、L2比较熟悉,我们就先从L1、L2这种特殊的正则化聊到他们的原始样貌,知道她从哪里来要到哪里去,走一条从特殊到一般的路,一条更加广阔看的更远的路。
But不同的方向,不同的学科领域对一些相同的知识点有着不同的爱称,为了交流方便,在这里简单啰嗦一下,L1、L2这种在机器学习方面叫做正则化,统计学领域的人喊她惩罚项,数学界会喊她范数。整体来说本质不变,源于数学。
L1使用的是绝对值距离,也叫做街区(City-Block)距离(曼哈顿距离),L2使用的是平方距离,也叫做欧式(Euclidean)距离。当盐啦,还有切比雪夫距离等等。
注意:敲黑板,不管是绝对值还是平方还是切比雪夫距离都是明氏距离(明考夫斯基距离)的特殊形式额已,大家感兴趣的自己查一下,不继续往下展开了,下一次可以具体写一写更多的别样式的距离。好像跑偏了,赶紧转回来。
耳熟能详的Lasso Regresssion是线性回归的一种,下面看看Lasso的简介:
Lasso是由1996年Robert Tibshirani首次提出,全称Least absolute shrinkage and selection operator。该方法是一种压缩估计。它通过构造一个罚函数得到一个较为精炼的模型,使得它压缩一些系数,同时设定一些系数为零。因此保留了子集收缩的优点,是一种处理具有复共线性数据的有偏估计。
Lasso Regresssion使用的就是L1正则化, 下面就是Lasso Regression 的Loss Function的样子,是不是很美丽:
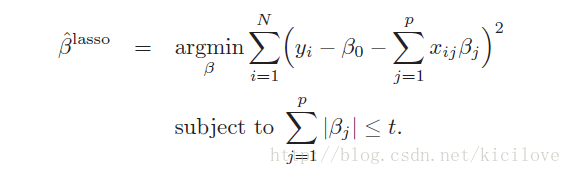
简单说一下,第一个SUM(∑)里面可以看出来是一个线性回归求损失平方,第二个SUM(∑)是线性回归中系数的服从条件,用来约束解的区域,凸优化中的约束求解一般都长这个样子。
此外,Lasso Regression的整体损失求极小的样子改成拉格朗日形式就是下面这个式子的模样:
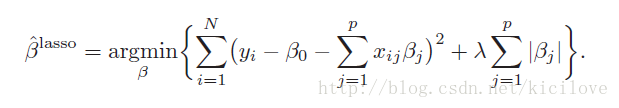
是不是找到了数学分析或者高等数学的感觉啦! 从式子里可以看到回归系数使用的是L1正则化,λ是惩罚参数或者叫做调节参数。L1范数的好处是当惩罚参数充分大时可以把某些待估的回归系数精确地收缩到0。
趁热打铁,我们再来看看Ridge Regression,也是线性回归的一个,看看简介:
RidgeRegression是一种专用于共线性的回归方法,对病态数据的拟合要强于最小二乘法(有想了解共线性问题,最小二乘的同学可以自己查资料了,如果对矩阵运算和矩阵性质熟悉的话会容易理解)。
岭回归使用的是L2正则化,下面的式子就是Ridge Regression的Loss Function 的美丽容颜:
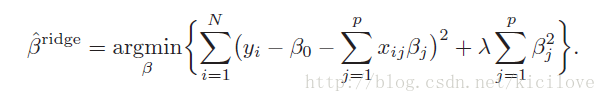
细心的同学眼睛已然盯上了式子的最后面,是不是传说中的L2正则项,系数的平方和。
上式的等价问题如下:
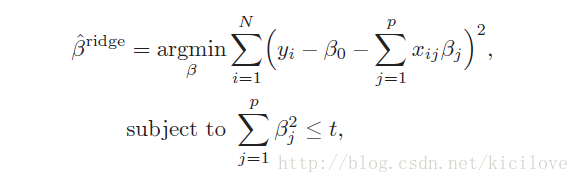
不管是Lasso Regression还是Ridge Regression 都有一个共同的参数,那就是惩罚参数λ,那么λ怎么来确定呢?
通常使用交叉验证法(CV)或者广义交叉验证(GCV),当然也可以使用AIC、BIC等指标。
我们学习Lasso Regression 或者Ridge Regression的时候,一定见过下面这张图:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 496
496











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









