




利用主从数据库来实现读写分离,从而分担主数据库的压力。在多个服务器上部署mysql,将其中一台认为主数据库,而其他为从数据库,实现主从同步。其中主数据库负责主动写的操作,而从数据库则只负责主动读的操作(slave从数据库仍然会被动的进行写操作,为了保持数据一致性),这样就可以很大程度上的避免数据丢失的问题,同时也可减少数据库的连接,减轻主数据库的负载。
一、数据库主从同步
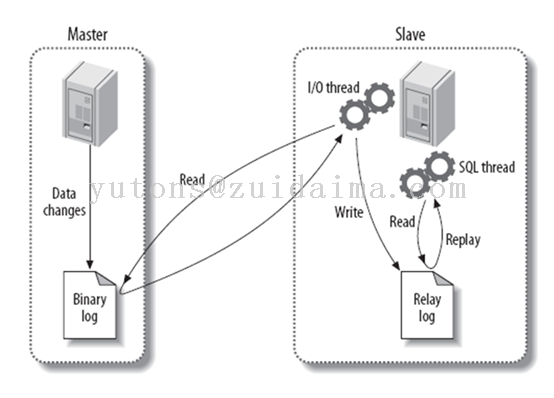
Binary log:主数据库的二进制日志
Relay log:从服务器的中继日志
第一步:master在每个事务更新数据完成之前,将该操作记录串行地写入到binlog文件中。
第二步:salve开启一个I/O Thread,该线程在master打开一个普通连接,主要工作是binlog dump process。如果读取的进度已经跟上了master,就进入睡眠状态并等待master产生新的事件。I/O线程最终的目的是将这些事件写入到中继日志中。
第三步:SQL Thread会读取中继日志,并顺序执行该日志中的SQL事件,从而与主数据库中的数据保持一致。
二、主从同步复制有以下几种方式:
(1)同步复制,master的变化,必须等待slave-1,slave-2,...,slave-n完成后才能返回。
(2)异步复制,master只需要完成自己的数据库操作即可,至于slaves是否收到二进制日志,是否完成操作,不用关心。MYSQL的默认设置。
(3)半同步复制,master只保证slaves中的一个操作成功,就返回,其他slave不管。这个功能,是由google为MYSQL引入的。
三、读写分离的实现方案
在应用和数据库之间增加代理层,代理层接收应用对数据库的请求,根据不同请求类型转发到不同的实例,在实现读写分离的同时可以实现负载均衡。
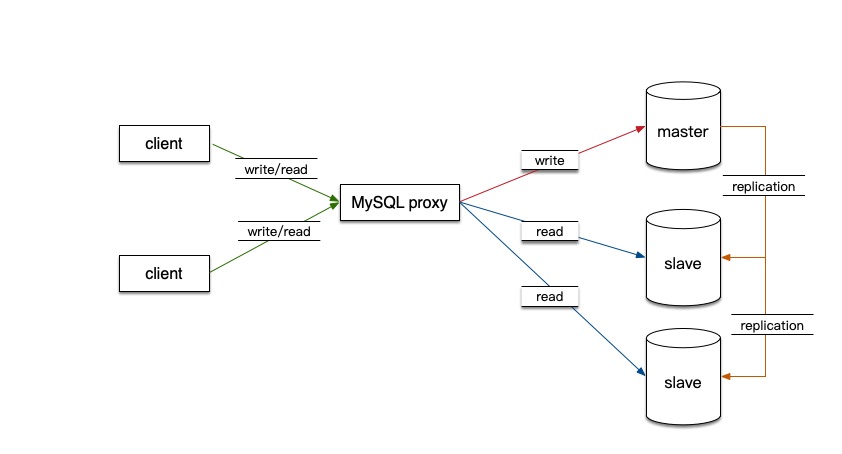
目前常用的mysql的读写分离中间件有MySQL-Proxy,奇虎360的Atlas,amoeba, MaxScale

















 2060
2060

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









