







正则表达式学习参考
1 概述
正则表达式 (Regular Expression) 是一种匹配模式,描述的是一串文本的特征。
正如自然语言中“高大”、“坚固”等词语抽象出来描述事物特征一样,正则表达式就是字符的高度抽象,用来描述字符串的特征。
正则表达式(以下简称正则, Regex )通常不独立存在,各种编程语言和工具作为宿主语言提供对正则的支持,并根据自身语言的特点,进行一定的剪裁或扩展。
正则入门很容易,有限的语法规则很容易掌握,但是目前正则的普及率并不高,主要是因为正则的流派众多,各种宿主语言提供的文档都过多的关注于自身的一些细节,而这些细节通常是初学者并不需要关注的。
当然,如果想要深入的了解正则表达式,这些细节又是必须被关注的,这是后话,让我们先从正则的基础开始,进入正则表达式的世界。
2 正则表达式基础
2.1 基本概念
2.1.1 字符串组成
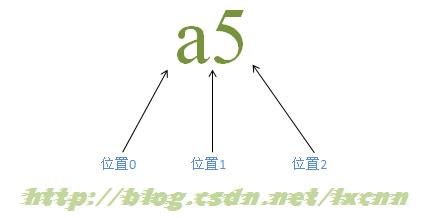
对于字符串“ a5 ”,是由两个字符“ a ”、“ 5 ”以及三个位置组成的,这一点对于正则表达式的匹配原理理解很重要。
2.1.2 占有字符和零宽度
正则表达式匹配过程中,如果子表达式匹配到的是字符内容,而非位置,并被保存到最终的匹配结果中,那么就认为这个子表达式是占有字符的;如果子表达式匹配的仅仅是位置,或者匹配的内容并不保存到最终的匹配结果中,那么就认为这个子表达式是零宽度的。
占有字符还是零宽度,是针对匹配的内容是否保存到最终的匹配结果中而言的。
占有字符是互斥的,零宽度是非互斥的。也就是一个字符,同一时间只能由一个子表达式匹配,而一个位置,却可以同时由多个零宽度的子表达式匹配。
2.1.3 正则表达式构成
正则表达式由两种字符构成。一种是在正则表达式中具体特殊意义的“元字符”,另一种是普通的“文本字符”。
元字符可以是一个字符,如“ ^ ”,也可以是一个字符序列,如“ /w ”。
2.2 元字符( Meta Character )
2.2.1 [ … ] 字符组 (Character Classes)
字符组可以匹配 [ ] 中包含的任意一个字符。虽然可以是任意一个,但只能是一个。
字符组支持由连字符“ - ”来表示一个范围。当“ - ”前后构成范围时,要求前面字符的码位小于后面字符的码位。
[^ … ] 排除型字符组。排除型字符组表示任意一个未列出的字符,同样只能是一个。排除型字符组同样支持由连字符“ - ”来表示一个范围。
| 表达式 | 说明 |
| [abc] | 表示“ a ”或“ b ”或“ c ” |
| [0-9] | 表示 0~9 中任意一个数字,等价于 [0123456789] |
| [/u4e00-/u9fa5] | 表示任意一个汉字 |
| [^a1<] | 表示除“ a ”、“ 1 ”、“ < ”外的其它任意一个字符 |
| [^a-z] | 表示除小写字母外的任意一个字符 |
举例:
“ [0-9][0-9] ”在匹配“ Windows 2003 ”时,匹配成功,匹配的结果为“ 20 ”。
“ [^inW] ”在匹配“ Windows 2003 ”时,匹配成功,匹配的结果为“ d ”。
2.2.2 常见字符范围缩写
对于一些常用的字符范围,如数字等,由于非常常用,即使使用 [0-9] 这样的字符组仍显得麻烦,所以定义了一些元字符,来表示常见的字符范围。
| 表达式 | 说明 |
| /d | 任意一个数字,相当于 [0-9] ,即 0~9 中的任意一个 |
| /w | 任意一个字母或数字或下划线,相当于 [a-zA-Z0-9_] |
| /s | 任意空白字符,相当于 [ /r/n/f/t/v] |
| /D | 任意一个非数字字符, /d 取反,相当于 [^0-9] |
| /W | /w 取反,相当于 [^a-zA-Z0-9_] |
| /S | 任意非空白字符, /s 取反,相当于 [^ /r/n/f/t/v] |
举例:
“ /w/s/d ”在匹配“ Windows 2003 ”时,匹配成功,匹配的结果为“ s 2 ”。
2.2.3 . 小数点
小数点可以匹配除“ /n ”以外的任意一个字符。如果要匹配包括“ /n ”在内的所有字符,一般用 [/s/S] ,或者是用“ . ”加 (?s) 匹配模式来实现。
| 表达式 | 说明 |
| . | 匹配除了换行符 /n 以外的任意一个字符 |
2.2.4 其它元字符
| 表达式 | 说明 |
| ^ | 匹配字符串开始的位置,不匹配任何字符 |
| $ | 匹配字符串结束的位置,不匹配任何字符 |
| /b | 匹配单词边界,不匹配任何字符 |
举例:
“ ^a ”在匹配“ cba ”时,匹配失败,因为表达式要求开始位置后面是字符“ a ”,而“ cba ”显然是不满足的。
“ /d$ ”在匹配“ 123 ”时,匹配成功,匹配结果为“ 3 ”,这个表达式要求匹配结尾处的数字,如果结尾处不是数字,如“ 123abc ”,则是匹配失败的。
2.2.5 转义字符
一些不可见字符,或是在正则中具有特殊意义的元字符,如想匹配字符本身,需要用 “/” 对其进行转义。
| 表达式 | 说明 |
| /r , /n | 回车和换行 |
| // | 匹配“ / ”本身 |
| /^ , /$ , /. | 分别匹配“ ^ ”、“ $ ”和“ . ” |
以下字符在匹配其本身时,通常需要进行转义。在实际应用中,根据具体情况,需要转义的字符可能不止如下所列字符
. $ ^ { [ ( | ) * + ? /
2.2.6 量词( Quantifier )
量词表示一个子表达式可以匹配的次数。量词可以用来修饰一个字符、字符组,或是用 () 括起来的子表达式。一些常用的量词被定义成独立的元字符。
| 表达式 | 说明 | 举例 |
| {m} | 表达式匹配 m 次 | “ /d{3} ”相当于“ /d/d/d ” “ (abc){2} ”相当于“ abcabc ” |
| {m,n} | 表达式匹配最少 m 次,最多 n 次 | “ /d{2,3} ”可以匹配“ 12 ”或“ 321 ”等 2 到 3 位的数字 |
| {m,} | 表达式至少匹配 m 次 | “ [a-z]{8,} ”表示至少 8 位以上的字母 |
| ? | 表达式匹配 0 次或 1 次,相当于 {0,1} | “ ab? ”可以匹配“ a ”或“ ab ” |
| * | 表达式匹配 0 次或任意多次,相当于 {0,} | “ <[^>]*> ”中“ [^>]* ”表示 0 个或任意多个不是“ > ”的字符 |
| + | 表达式匹配 1 次或意多次,至少 1 次,相当于 {1,} | “ /d/s+/d ”表示两个数字中间,至少有一个以上的空白字符 |
注意:在不是动态生成的正则表达式中,不要出现“ {1} ”这样的量词,如“ /w{1} ”在结果上等价于“ /w ”,但是会降低匹配效率和可读性,属于画蛇添足的做法。
2.2.7 分支结构( Alternation )
当一个字符串的某一子串具有多种可能时,采用分支结构来匹配,“ | ”表示多个子表达式之间“或”的关系, “|” 是以 () 限定范围的,如果在 “|” 的左右两侧没有 () 来限定范围,那么它的作用范围即为 “|” 左右两侧整体。
| 表达式 | 说明 |
| | | 多个子表达式之间取“或”的关系 |
举例:
“ ^aa|b$ ”在匹配“ cccb ”时,是可以匹配成功的,匹配的结果是“ b ”,因为这个表达式表示匹配“ ^aa ”或“ b$ ”,而“ b$ ”在匹配“ cccb ”时是可以匹配成功的。
“ ^(aa|b)$ ”在区配“ cccb ”时,是匹配失败的,因为这个表达式表示在“开始”和“结束”位置之间只能是“ aa ”或“ b ”,而“ cccb ”显然是不满足的。
3 正则表达式进阶
3.1 捕获组( Capture Group )
捕获组就是把正则表达式中子表达式匹配的内容,保存到内存中以数字编号或手动命名的组里,以供后面引用。
| 表达式 | 说明 |
| (Expression) | 普通捕获组,将子表达式 Expression 匹配的内容保存到以数字编号的组里 |
| (?<name> Expression) | 命名捕获组,将子表达式 Expression 匹配的内容保存到以 name 命名的组里 |
普通捕获组(在不产生歧义的情况下,简称捕获组)是以数字进行编号的,编号规则是以“ ( ”从左到右出现的顺序,从 1 开始进行编号。通常情况下,编号为 0 的组表示整个表达式匹配的内容。
命名捕获组可以通过捕获组名,而不是序号对捕获内容进行引用,提供了更便捷的引用方式,不用关注捕获组的序号,也不用担心表达式部分变更会导致引用错误的捕获组。
3.2 非捕获组
一些表达式中,不得不使用 ( ) ,但又不需要保存 ( ) 中子表达式匹配的内容,这时可以用非捕获组来抵消使用 ( ) 带来的副作用。
| 表达式 | 说明 |
| (?:Expression) | 进行子表达式 Expression 的匹配,并将匹配内容保存到最终的整个表达式的区配结果中,但 Expression 匹配的内容不单独保存到一个组内 |
3.3 反向引用
捕获组匹配的内容,可以在正则表达式的外部程序中进行引用,也可以在表达式中进行引用,表达式中引用的方式就是反向引用。
反向引用通常用来查找重复的子串,或是限定某一子串成对出现。
| 表达式 | 说明 |
| /1 , /2 | 对序号为 1 和 2 的捕获组的反向引用 |
| /k<name> | 对命名为 name 的捕获组的反向引用 |
举例:
“ (a|b)/1 ”在匹配“ abaa ”时,匹配成功,匹配到的结果是“ aa ”。“ (a|b) ”在尝试匹配时,虽然既可以匹配“ a ”,也可以匹配“ b ”,但是在进行反向引用时,对应 () 中匹配的内容已经是固定的了。
3.4 环视( Look Around )
环视只进行子表达式的匹配,匹配内容不计入最终的匹配结果,是零宽度的。
环视按照方向划分有顺序和逆序两种,按照是否匹配有肯定和否定两种,组合起来就有四种环视。环视相当于对所在位置加了一个附加条件。
| 表达式 | 说明 |
| (?<=Expression) | 逆序肯定环视,表示所在位置左侧能够匹配 Expression |
| (?<!Expression) | 逆序否定环视,表示所在位置左侧不能匹配 Expression |
| (?=Expression) | 顺序肯定环视,表示所在位置右侧能够匹配 Expression |
| (?!Expression) | 顺序否定环视,表示所在位置右侧不能匹配 Expression |
举例:
“ (?<=Windows )/d+ ”在匹配“ Windows 2003 ”时,匹配成功,匹配结果为“ 2003 ”。我们知道“ /d+ ”表示匹配一个以上的数字,而“ (?<=Windows ) ”相当于一个附加条件,表示所在位置左侧必须为“ Windows ”,它所匹配的内容并不计入匹配结果。同样的正则在匹配“ Office 2003 ”时,匹配失败,因为这里任意一串数字子串的左侧都不是“ Windows ”。
“ (?!1)/d+ ”在匹配“ 123 ”时,匹配成功,匹配的结果为“ 23 ”。“ /d+ ”匹配一个以上数字,但是附加条件“ (?!1) ”要求所在位置右侧不能是“ 1 ”,所以匹配成功的位置是“ 2 ”前面的位置。
3.5 忽略优先和匹配优先
或者叫做正则表达式匹配的贪婪与非贪婪模式。
标准量词修饰的子表达式,在可匹配可不匹配的情况下,总会先尝试进行匹配,称这种方式为匹配优先,或者贪婪模式。此前介绍的一些量词,“ {m} ”、“ {m,n} ”、“ {m,} ”、“ ? ”、“ * ”和“ + ”都是匹配优先的。
一些 NFA 正则引擎支持忽略优先量词,也就是在标准量词后加一个“ ? ”,此时,在可匹配可不匹配的情况下,总会先忽略匹配,只有在由忽略优先量词修饰的子表达式,必须进行匹配才能使整个表达式匹配成功时,才会进行匹配,称这种方式为忽略优先,或者非贪婪模式。忽略优先量词包括“ {m}? ”、“ {m,n}? ”、“ {m,}? ”、“ ?? ”、“ *? ”和“ +? ”。
举例:
源字符串: <div>aaa</div><div>bbb</div>
正则表达式 1 : <div>.*</div> 匹配结果: <div>aaa</div><div>bbb</div>
正则表达式 2 : <div>.*?</div> 匹配结果: <div>aaa</div>















 3308
3308

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









