






Before a file can be read, it must be opened. When a file is opened, the operating system uses the path name supplied by the user to locate the directory entry on the disk.
在读取一个文件之前,必须先打开这个文件。当要打开一个文件时,操作系统必须根据用户提供的路径名在磁盘中找到目录项(directory entry,包含该文件的目录)
The directory entry provides the information needed to find the disk blocks. Depending on the system, this information may be the disk address of the entire file (with contiguous allocation), the number of the first block (both linked-list schemes), or the number of the i-node. In all cases, the main function of the directory system is to map the ASCII name of the file onto the information needed to locate the data.
目录下提供定位磁盘块所需的信息。依据不同的操作系统,这个信息可能是整个文件的起始地址(连续分配方式中采用),第一个磁盘块的序号(采用链表存储方式),i-node的序号。在这些设计中,目录的主要功能就是把文件的ASCII名字映射为定位文件数据的信息。
PS:根据赵炯编写的《linux内核源码解析》书中所讲,在Linux系统中,目录项结构仅仅包括文件名和i-node number,i-node number和 i-node结构体中的i_num成员对应,从而定位到i-node,i-node保存文件的属性以及包含数据的磁盘块号信息等。
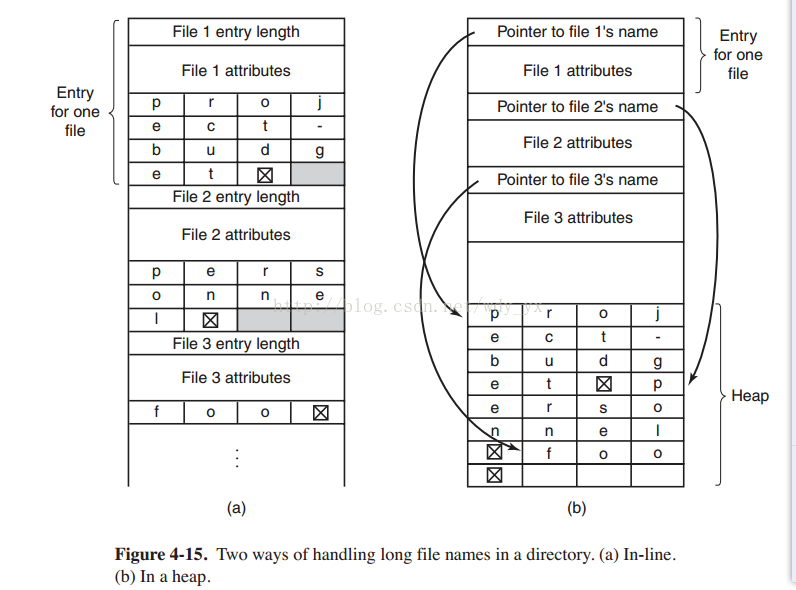
One alternative is to give up the idea that all directory entries are the same size. With this method, each directory entry contains a fixed portion, typically starting with the length of the entry, and then followed by data with a fixed format, usually including the owner, creation time, protection information, and other attributes.
放弃所有目录项相同大小的方法。另外一种方法就是,每个目录项中包含一个固定区域,最典型的就是包含这个目录项的长度信息,然后跟随固定格式的数据,这些数据主要包括文件的拥有者,创建时间,保护信息以及其他属性等。
This fixed-length header is followed by the actual file name, however long it may be, as shown in Fig. 4-15(a) in big-endian format (e.g., SPARC). In this example we have three files, project-budget,personnel, andfoo. Each file name is terminated by a special character (usually 0), which is represented in the figure by a box with a cross in it. To allow each directory entry to begin on a word boundary, each file name is filled out to an integral number of words, shown by shaded boxes in the figure.
正如在图4-15(a)中以big-endian 格式所示,文件长度,属性,接下来跟随的是文件的真实名字,无论这个文件名有多长都可以。在这个例子中我们可以从图中看出有三个文件,project-budget, personnel, and foo.每一个文件名有一个特殊的终结符(通常为0),在图中有一个中间有×的方框表示。为了让每个目录项都是从字长度边界开始(地址对齐),每一个文件名都进行了填充,从而使文件名占用长度达到word长度倍数。在图中用阴影边框表示。
A disadvantage of this method is that when a file is removed, a variable-sized gap is introduced into the directory into which the next file to be entered may not fit. This problem is essentially the same one we saw with contiguous disk files, only now compacting the directory is feasible because it is entirely in memory. Another problem is that a single directory entry may span multiple pages, so a page fault may occur while reading a file name.
Another way to handle variable-length names is to make the directory entries themselves all fixed length and keep the file names together in a heap at the end of the directory, as shown in Fig. 4-15(b). This method has the advantage that when
an entry is removed, the next file entered will always fit there. Of course, the heap must be managed and page faults can still occur while processing file names. One minor win here is that there is no longer any real need for file names to begin at word boundaries, so no filler characters are needed after file names in Fig. 4-15(b) as they are in Fig. 4-15(a).
处理可变文件长度的方法就是让目录项本身长度固定,然后让文件名字一起存储在目录后面的堆中,如图4-15(b)所示。这种方法的优势在于当一个文件去除后,下一个进入的文件肯定能找到合适的位置?当然,必须对堆进行管理,页错误仍然也会发生。这个方法好一点的地方在于不再需要文件名从word地址边界开始,所以也就不需要在文件名后面加入填充空字符。4-15(b)和4-15(a)表示同一个目录。 In all of the designs so far, directories are searched linearly from beginning to end when a file name has to be looked up. For extremely long directories, linear searching can be slow. One way to speed up the search is to use a hash table in
each directory. Call the size of the table n. To enter a file name, the name is hashed onto a value between 0 andn−1, for example, by dividing it bynand taking the remainder. Alternatively, the words comprising the file name can be added up and
this quantity divided by n, or something similar
目前来看,上面所以的目录方法,为了找到文件名,需要线性搜索整个目录。对于特别长的目录,线性搜索可能非常慢。一个加速搜索的方法就是在目录中利用hash表。设表长度为n。输入一个文件名后,文件名hash为一个在0到n-1范围的数值,举例,可以采用对n求余数的方法得到。也可以把组成文件名的每个字符值相加,然后除以n,或者别的相似的方法。
Either way, the table entry corresponding to the hash code is inspected. If it is unused, a pointer is placed there to the file entry. File entries follow the hash table.If that slot is already in use, a linked list is constructed, headed at the table entry and threading through all entries with the same hash value.
同样的,和hasn值对应的hash表项也要进行检查。如果这个hash项没有被使用,就在hash项中放置一个指向该文件项的指针。文件项跟着hasn表。如果hash项已经存在,就构建一个链表,链表头放置在hash项中,链表连接了所有含有同样hash值的文件项。
《现代操作系统4th》英文版下载地址















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









