






说在前面,DR以后肯定是干掉RAG的,我说的。

多轮对话LLM+search是不是等于Deep research?
其实现在的做法基本都这么做,我自己的项目也这么做
我之前说过chatGPT的deepresearch 做的好是因为它的DR 引擎是o3强化版本的针对过search场景RFT过,所以体验比grok和google的DR要好,后两者更像deep search或者说我们用的更像deep search
这里有个奇怪的问题,逻辑上都是通过多轮对话来处理问题,那它好在哪呢?为什么就因为引擎是o3的RL强化版就牛比了呢
这篇论文也许会给你答案
https://arxiv.org/pdf/2503.09516
先说结论,论文用的方法在和同等配置的任务上比较能高出用rag来解决问题至少20几个百分点,随着模型parameters增大能提升百分之40的准确率

然后看它干了啥
强化学习 (RL) 通过 SEARCH-R1 框架增强大型语言模型 (LLM) 进行搜索驱动推理的能力,主要体现在以下几个方面:
-
建模搜索交互作为强化学习环境的一部分:
传统的 RL 框架主要依赖策略 LLM 生成整个输出序列。
SEARCH-R1 将搜索弓|擎 (R) 建模为环境的一部分。这意味着 LLM 不仅生成文本,还可以通过与搜索弓|擎的交互来影响环境并获得反馈。
这样的剑魔就能使得采样的轨迹序列能够交错进行 LLM 的 token 生成和搜索弓|擎的检索。这种交错式的检索与推理 (πθ(· | x;R)) 使得在需要外部信息检索的推理密集型任务中,模型能够做出更有效的决策.
-
然后就是优化多轮交错的推理和搜索:
这个基本是deep系列的日常刚需了,为啥叫deep呢,就是多轮。SEARCH-R1 也是支持多轮检索和推理。LLM 可以根据需要,动态地调整检索策略。
LLM 通过特定的 token (例如
<search>和</search>) 触发搜索调用。检索到的内容会用<information>和</information>token 封装,并附加到当前的生成序列中,作为下一步生成的额外上下文. 推理步骤则封装在<think>和</think>token 中. 最终答案用<answer>和</answer>token 格式化.RL 优化 LLM 的推理轨迹,包括与搜索弓|擎的多轮交互. 这种学习过程是迭代的,直到达到最大行动次数或生成最终答案为止.
-
使用简洁的基于结果的奖励函数:
SEARCH-R1 采用一个简单的基于最终结果的奖励系统作为主要的训练信号,指导优化过程.
奖励函数评估模型响应的正确性. 例如,在事实性推理任务中,正确性可以使用精确字符串匹配 (Exact Match, EM) 等规则进行评估,就是看你是不是回答了最重要的信息,在你吐出来的答案里面。
论文里的印证能看出来,这种最小化的奖励设计在搜索和推理场景中是有效的. RL 即使仅通过结果奖励进行训练,也能帮助模型学习复杂的推理能力,包括自我验证和自我纠正. 在一个案例研究中,SEARCH-R1 甚至在获得足够信息后执行额外的检索步骤进行自我验证.
-
通过检索到的 token 损失屏蔽稳定训练:
在 PPO 和 GRPO 等 RL 算法中,token 级别的损失计算是在整个生成序列上进行的. 在 SEARCH-R1 中,序列包含 LLM 生成的 token 和从外部段落检索到的 token.
对 LLM 生成的 token 进行优化可以增强模型与搜索弓|擎交互和执行推理的能力. 然而,对检索到的 token 进行优化可能会导致意外的学习动态,因为这也不是你模型推理出来的啊。
为了解决这个问题,SEARCH-R1 引入了检索到的 token 损失屏蔽,确保策略梯度目标仅在 LLM 生成的 token 上计算,将检索到的内容排除在优化过程之外.
这么干,就能有助于稳定训练. 应用检索到的 token 屏蔽可以带来更大的 LLM 改进,减轻意外的优化效应,并确保更稳定的训练.
从训练的算法公式解读:
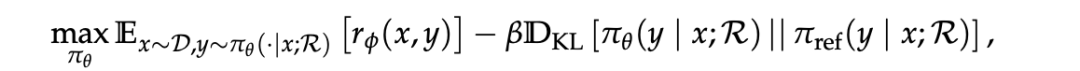
-
max{πθ}: 目标是找到最优的策略LLM参数 θ,使得整个期望值最大化。
-
πθ: 这是策略LLM (Policy LLM),是我们要训练的模型。它根据输入 x 和搜索引擎 R 的辅助来生成输出 y。
-
E{x~D, y~πθ(·|x;R)}: 表示期望值。x 是从数据集 D 中抽取的输入样本,y 是由当前策略 π_θ 在给定 x 和搜索引擎 R 的条件下生成的输出。
-
rφ(x, y): 这是奖励函数 (Reward Function),由一个固定的奖励模型 rφ 评估。它衡量策略LLM生成的输出 y (在给定输入 x 的情况下) 的好坏。分数越高越好。
-
πref: 这是参考LLM (Reference LLM),通常是一个预训练好的、固定的LLM。
-
DKL[πθ(y|x;R) || πref(y|x;R)]: 这是KL散度项。它衡量策略LLM πθ 的输出分布与参考LLM πref 的输出分布之间的差异。这个项的作用是正则化,防止策略LLM πθ 偏离参考LLM πref 太远,从而保持生成内容的一定质量和相关性,避免模型为了追求高奖励而生成奇怪或不连贯的文本。
-
β: 这是一个超参数,用来平衡奖励项和KL散度惩罚项之间的重要性。
公式的目标是:训练一个策略LLM (πθ),使其生成的输出在获得高奖励 (rφ(x, y)) 的同时,又不会与一个固定的参考LLM (πref) 的行为相差太远。
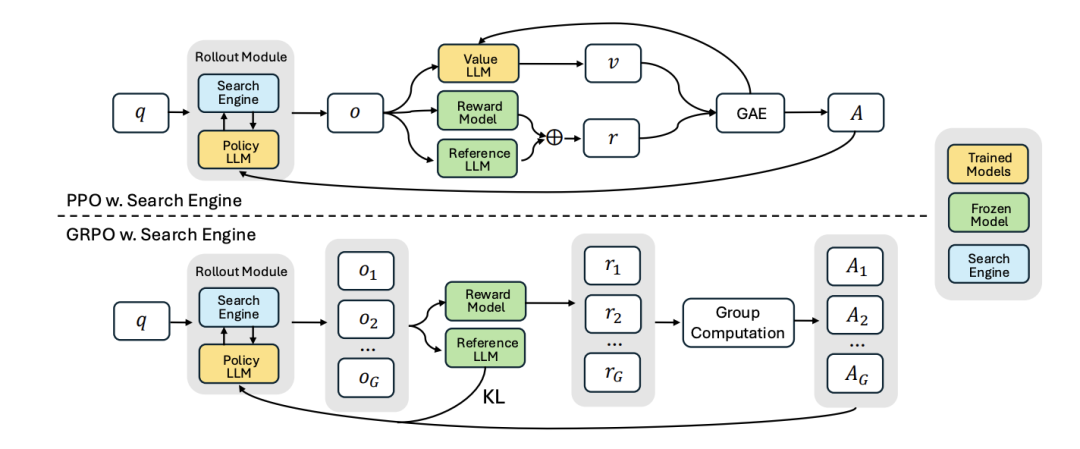
这个图展示了两种训练流程:PPO with Search Engine 和 GRPO with Search Engine。它们都实现了公式 的优化目标。
共同部分 (Rollout Module):
-
q (Query): 代表公式中的输入 x。
-
Rollout Module:
Search Engine (蓝色): 对应公式中的 R。它为Policy LLM提供外部知识或检索结果。
Policy LLM (黄色,Trained Model): 对应公式中的 πθ。它接收输入 q,并与Search Engine交互,生成输出。这是被训练和优化的模型。
PPO w. Search Engine (上半部分):
-
Policy LLM 生成单个输出 o (对应公式中的 y)。
-
输出 o 被送往三个地方:
Value LLM (黄色,Trained Model): 估计当前状态的价值 v。这是PPO算法的一部分,用于计算优势函数 (Advantage),给GAE用。
Reward Model (绿色,Frozen Model): 对应公式中的 rφ。它计算输出 o 的奖励 r。
Reference LLM (绿色,Frozen Model): 对应公式中的 π{ref}。它的输出与Policy LLM的输出一起用于计算KL散度。
-
奖励 r 和来自Reference LLM的KL散度信息(图中 r 和Reference LLM的输出汇总到 ⊕,表示结合奖励和KL惩罚)以及价值 v 被送入 GAE (Generalized Advantage Estimation) 模块。
-
GAE 计算优势 A。
-
优势 A 被用来更新 Policy LLM 和 Value LLM 的参数(即优化 θ)。这个更新过程就是为了最大化公式 中的目标。
GRPO w. Search Engine (下半部分):
GRPO是PPO的一种变体,主要区别在于它处理一组 (G个) 输出。
-
Policy LLM 生成一组输出 o1, o2, ..., oG。
-
这些输出分别被送往:
Reward Model: 计算每个输出的奖励 r1, r2, ..., rG。
Reference LLM: 与Policy LLM的输出一起用于计算KL散度。
-
这些奖励和KL散度信息被送到 Group Computation 模块。
-
Group Computation 计算每个输出对应的优势或一组聚合的优势 A1, A2, ..., AG
-
这些优势被用来更新 Policy LLM。
Trained Models (黄色): 在训练过程中参数会被更新的模型,如Policy LLM, Value LLM。
Frozen Model (绿色): 参数固定不变的模型,如Reward Model, Reference LLM。
Search Engine (蓝色): 提供外部信息的模块。
公式与图和起来说就是:
-
公式 定义了强化学习的优化目标。
-
图展示了实现这个优化目标的具体流程,特别是PPO/GRPO算法如何使用搜索引擎、奖励模型、参考模型和价值模型来收集经验、计算奖励和惩罚、并最终更新策略LLM。
-
πθ (Policy LLM) 在图中是核心训练对象。
-
R (Search Engine) 在图中是Policy LLM的辅助工具。
-
rφ (Reward Model) 在图中用于计算奖励 r。
-
πref (Reference LLM) 在图中用于计算KL散度惩罚。
-
整个PPO/GRPO的循环(生成 -> 评估 -> 更新)都是为了找到能最大化公式 中期望值的 πθ。
抛开这个论文,我们讲一下RAG和search with RL的真正区别,可以理解为以下几点:
交互方式和时机:
RAG:通常是在LLM生成回答之前,基于原始输入查询进行一次(或少数几次)集中的信息检索。检索到的内容会作为上下文信息,与原始查询一起一次性提供给LLM,然后LLM基于这些增强的输入生成最终答案。
Search-R1 中的 Search Engine:LLM在生成过程中的多个步骤(multi-turn)与搜索引擎进行交错式(interleaved)的交互。LLM可以根据当前的推理状态,自主决定何时需要搜索、搜索什么内容。搜索结果会实时返回并整合到当前的推理链中,影响后续的思考和可能的下一次搜索。
学习目标和优化:
RAG:LLM本身通常不直接学习“如何检索”或“何时检索”。检索器(Retriever)往往是一个独立的模块,其优化可能与LLM的生成优化是分开的。LLM主要学习如何利用给定的检索信息来生成更好的答案。
Search-R1 中的 Search Engine:通过强化学习 (RL),LLM(即文中的 Policy LLM πθ)被训练来学习如何有效地与搜索引擎交互。这包括学习生成合适的搜索查询 (<search>query</search>)、以及如何利用检索到的信息 (<information>...</information>) 进行后续推理。RL的目标是优化整个决策序列,使LLM能够通过与搜索引擎的交互来解决复杂问题并获得更高的奖励。
查询的生成:
RAG:检索查询通常直接是用户的输入,或者基于用户输入进行简单的转换。
Search-R1 中的 Search Engine:LLM在推理过程中可以自主生成多个、逐步细化的搜索查询。这些查询是基于LLM当前的“思考”状态(<think>...</think>)动态产生的,更加灵活和有针对性。例如,在 Table 9 的案例中,LLM 先搜索 "Curious fragrance information",然后根据结果再搜索 "Britney Spears birthplace"。

灵活性和动态性:
RAG:相对固定,检索在生成前完成。如果初次检索的信息不理想,LLM可能难以在生成过程中补救。
Search-R1 中的 Search Engine:非常灵活和动态。LLM可以在推理的任何需要外部知识的环节发起搜索,如果一次搜索结果不满意,它可以通过后续的思考和新的搜索来调整策略。
在模型架构中的角色:
RAG:可以看作是LLM输入端的一个“增强器”或“预处理器”。
Search-R1 中的 Search Engine:更像是一个LLM在推理过程中可以主动调用的“工具”(tool use)。LLM通过学习(RL)来掌握这个工具的使用方法。论文中明确提到“We model the search engine as part of the environment”。
总得来说,可以这么理解:
RAG 更侧重于“增强输入”:在生成前用检索到的信息丰富LLM的上下文。
Search-R1 中的 Search Engine 更侧重于“学习交互式工具使用”:通过RL训练LLM在推理过程中动态地、多轮地、自主地使用搜索引擎来辅助思考和决策。
因此,Search-R1中的方法相较于传统的RAG,赋予了LLM更大的自主性和灵活性,使其能够更智能地利用外部知识源解决问题,尤其是在需要多步推理和信息迭代获取的复杂场景下。
那回到文章开头的,我为什么说没经过RL训练的LLM来做DeepResearch也就是DR有点挫呢?
我们从以下几个维度来分析
如果不经过专门的强化学习(RL)训练(像Search-R1那样)的LLM(即使是能力很强的基础模型,如GPT-4o,当然也不是我黑它啊,别人也不咋滴

)来执行“深度研究” (deep research) 任务,与经过Search-RL训练的模型相比,会有以下几方面的显著劣势:
1- 缺乏优化的搜索策略 (Suboptimal Search Strategy):
生成低效或模糊的搜索查询: 不知道如何精确地表述问题以获得最佳搜索结果。
搜索次数不当: 可能搜索过多(冗余信息)或过少(信息不足)。
搜索时机不佳: 不知道在推理的哪个阶段进行搜索最有利。
难以从失败的搜索中恢复: 如果初次搜索结果不佳,它可能不知道如何调整查询或策略,甚至不给你走多轮继续搜索,我这么说肯能有点抽象,你自己试试就知道我啥意思了。没做过的这样类似项目的,不太好理解。
未经训练的LLM: 即使通过精心设计的prompting引导其使用搜索工具,它也缺乏一个通过经验学习到的最优搜索策略。
然而,如果是Search-RL训练的模型,通过RL,模型学习到了在特定任务上何时搜索、搜索什么内容、以及如何根据搜索结果调整后续行为的策略,以最大化最终任务的奖励(例如,答案的正确性)。它学会了论文中提到的“自主生成(多轮)搜索查询”和“根据问题复杂性动态调整检索策略”。这些玩意都是RL训练后学到的隐式策略。不上RL的活儿的话,很难让模型get到这能力,因为LLM天生它不是干这个的。
2- 低效的多轮交互和迭代能力 (Inefficient Multi-Turn Interaction and Iteration):
难以将新信息有效整合到现有认知中: 只是简单罗列搜索结果,而不是将其融入连贯的推理链。
在多轮搜索后“迷失方向”: 忘记最初的目标或无法将分散的信息点联系起来。
缺乏连贯的“思考-搜索-整合”循环: 它的行为更多依赖于提示的静态指令,而不是动态的内部状态。
未经训练的LLM: 深度研究通常需要多轮次的信息获取和迭代思考。未经训练的LLM可能难以有效地管理这种复杂的交互流程。
但是换成Search-RL训练的模型, 专门为“多轮搜索交互”和“交错式推理与检索”进行了优化。它学会了如何利用<think>, <search>, <information>等特殊标记来结构化其思考和搜索过程,从而更连贯地进行迭代研究,咱说上过计算机课的学生(不认真,上课睡觉,下课包宿,不听讲的除外)怎么也比自学的强点。

3- 对检索信息的利用不充分 (Poor Utilization of Retrieved Information):
过分依赖或忽略某些检索片段: 未能权衡不同信息的价值和可信度。难以从大量或有噪声的检索结果中提取核心要点。
未经训练的LLM: 即使获取了相关信息,也可能无法最佳地利用这些信息。它可能:
上过科班出身的Search-RL训练的模型,在训练过程中,模型会学习如何筛选和利用检索到的信息(enclosed within <information> and </information> tokens)来辅助其推理步骤(wrapped within <think> and </think> tokens),因为有效的利用会带来更高的奖励,这些都是RL给带来的。
4- 缺乏针对任务的“专注度”和“目标导向性” (Lack of Task-Specific Focus and Goal-Orientation):
未经训练的LLM: 其行为是通用的,目标是生成连贯、相关的文本。在深度研究这类复杂任务中,它可能偏离主题,或给出表面化、不够深入的答案。
反观Search-RL训练的模型, RL的奖励函数(例如论文中的 outcome-based reward)直接引导模型朝着完成特定研究任务的目标前进。这种目标导向性使其在研究过程中更加专注和高效。
5- 稳定性和一致性较差 (Lower Stability and Consistency):
未经训练的LLM: 依赖提示工程,输出的质量和结构可能因提示的微小变化而有较大波动。在复杂的深度研究中,难以保证每次都能遵循最佳路径。
Search-RL训练的模型: 通过学习固化了一套有效的行为模式,在特定类型的研究任务上表现更稳定和一致。KL散度项(D_KL)也帮助其行为不过于偏离参考模型,维持一定的稳定性。
6- 难以处理隐式知识和复杂依赖 (Difficulty with Implicit Knowledge and Complex Dependencies):
未经训练的LLM: 深度研究往往涉及挖掘信息间的复杂关系和隐含的知识。未经训练的模型可能难以主动发现这些,更多依赖明确的指示。
Search-RL训练的模型就能够有潜力通过探索不同的搜索和推理路径,逐渐学会识别和利用这些更深层次的信息依赖,因为这有助于解决更复杂的问题并获得奖励。
反正说一千道一万,未经训练的LLM在执行深度研究任务时,更像是一个被动接受指令并尝试执行的工具。而经过Search-RL训练的模型,则更像是一个学习了“如何进行研究”这一技能的智能体,它能更主动、更策略性地与搜索引擎交互,以达到研究目标。这才是端到端的Agentic的意义,页可以说是LLM as a Agent,Search-R1或者类似的框架,一旦上了,就能通过RL让LLM“学会自主地生成(多轮)搜索查询并在实时检索的情况下进行逐步推理”,和傻调工具的agent是两回事。
要不然你们看现在的google和grok3的DR是不是和以前不一样了?




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









