









欢迎讨论、交流,转载请注明出处,3Q!
前言
在前面的文章中笔者就Map接口和Map接口的实现原理:内部哈希映射技术做了一个简单的
分析,并且对hashCode方法做了一些阐述。可能有些混乱,不过理解这些是弄懂HashMap
的前提,也能帮助我们更好的解析hashMap的源码。
HashMap类设计
HashMap是基于哈希表的Map接口的非同步实现,它提供所有可选的映射操作,并允许使
用null键和null值。此集合不保证映射的顺序,特别不保证其顺序永久不变。
首先我们先看下HashMap类的头部:
public class HashMap<K,V>
extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable1、底层实现
接下来我们看看HashMap的底层是如何实现的。在这之前我们先对数据结构略作分析。
在java语言中,最基本的结构分为两种:其一为数组,其二为模拟指针(引用)说白了就是
链表。所有的数据类型都可以使用上述的两种来构造。
数组的特点是:寻址容易,插入和删除困难;
链表的特点是:寻址困难,插入和删除容易;
思考下:我们能不能结合两者的优点,折中构造一种寻址容易,插入删除也较为容易的
数据结构呢?答案是肯定的了。我们可以构造一种“链表散列”的数据结构,可以理解为链表
的数组,HashMap就是基于其实现的。
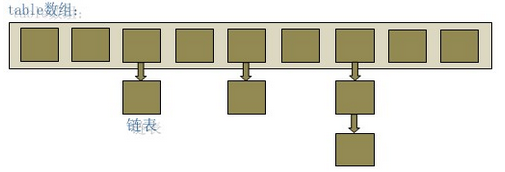
从图中可以看出HashMap的底层就是一个数组结构,数组中的每一项又是一个链表。那么
究竟是不是这样呢?我们看源码吧。
/**
* The table, resized as necessary. Length MUST Always be a power of two.
*/
transient Entry<K,V>[] table;
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
int hash;
/**
* Creates new entry.
*/
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
...........
}
而HashMap有一个属性是Entrr的数组table。Entry就是table数组中的元素,Map.Entry保存一个键值对
和这个键值对持有指向下一个键值对的引用,如此就构成了链表了。
2、构造方法
/**根据指定容量和负载因子构造HashMap*/
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
// Find a power of 2 >= initialCapacity
int capacity = 1;
while (capacity < initialCapacity)
capacity <<= 1;
this.loadFactor = loadFactor;
threshold = (int)Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
table = new Entry[capacity];
useAltHashing = sun.misc.VM.isBooted() &&
(capacity >= Holder.ALTERNATIVE_HASHING_THRESHOLD);
init();
}
/**根据指定的容量和默认的负载因子构造HashMap*/
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
//默认的空的构造器
public HashMap() {
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);
}
/**通过指定一个Map对象进行构造*/
public HashMap(Map<? extends K, ? extends V> m) {
this(Math.max((int) (m.size() / DEFAULT_LOAD_FACTOR) + 1,
DEFAULT_INITIAL_CAPACITY), DEFAULT_LOAD_FACTOR);
putAllForCreate(m);
} 这里我们先不做解释。
3、存储元素
对于HashMap的存储元素的方法由多个,这里我们就put方法做下分析吧:public V put(K key, V value) {
// HashMap允许存放null键和null值。
// 当key为null时,调用putForNullKey方法,将value放置在数组第一个位置。
if (key == null)
return putForNullKey(value);
// 根据key的keyCode重新计算hash值。
int hash = hash(key);//注意这里的实现是jdk1.7和以前的版本有区别的
// 搜索指定hash值在对应table中的索引。
int i = indexFor(hash, table.length);
// 如果 i 索引处的 Entry 不为 null,通过循环不断遍历 e 元素的下一个元素。
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
// 如果i索引处的Entry为null,表明此处还没有Entry。
modCount++;
// 将key、value添加到i索引处。
addEntry(hash, key, value, i);
return null;
}思考1:(未发生hash冲突情况下)
table是线性数组,是如何实现随机存储的呢?
这里是通过下面两行代码来实现的
int hash = hash(key);//注意这里的实现是jdk1.7和以前的版本有区别的
// 搜索指定hash值在对应table中的索引。
int i = indexFor(hash, table.length);/**产生哈希码*/
final int hash(Object k) {
int h = 0;
if (useAltHashing) {
if (k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h = hashSeed;
}
h ^= k.hashCode();
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
/*加入高位计算,防止低位不变,高位变化是引起hash冲突*/
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
/**产生索引,由于索引产生是不确定的,因此也就造成了HashMap顺序的不确定性。
需要注意的是不同的hash产生的索引完全有可能相同的
该方法的实现十分的巧妙,它通过h & (length-1)来的到对象保存的
索引,有可知道底层数组为2的n次方,这在速度上就有了明显的优化
*/
static int indexFor(int h, int length) {
return h & (length-1);
}
索引i。如果table[i]为null,则此处没有键值对,可以直接插入。如果table[i]!=null则此处有元素
则上面的for循环就是存储的新的元素:
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}例如一个具体的对象作为一个key,我们通过内容判断是否相等(equals重写),这时我们应该要
主动的去重写hashCode方法,让其和equals方法一样的逻辑结果。如若不然的话,我们认为相等
的key会覆盖,却因为没有重写hashCode实际上没有覆盖!
因为实际我们用String作为key的比较多,也就没有太过注意上述情况。
下面的就是一个错误例子
package com.kiritor;
public class Student {
String name;
public Student(String aa) {
// TODO Auto-generated constructor stub
name = aa;
}
@Override
public boolean equals(Object obj) {
// TODO Auto-generated method stub
return this.name.equals(((Student) obj).name);
}
public static void main(String[] args) throws InterruptedException {
HashMap<Student, Object> hashMap = new HashMap<>();
hashMap.put(new Student("AA"), "HEHE");
hashMap.put(new Student("AA"), "HEHE");
System.out.println(new Student("AA").name.equals(new Student("AA").name));
System.out.println(hashMap.size());
}
}
思考2:hash冲突
一个有意思的情况出现:
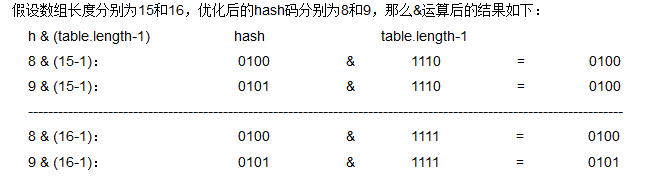
这一问题呢?其实这里就是“链表数组”的IMBA之处了。详细的处理情况还是在for循环中。
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}但是获得的索引却是0,产生了hash冲突。进入for循环体,由于key1、key2的哈希不同,所以if判断为false
之后key1=key1.next(说法不准,这里直接就以key当做键值对元素吧),再然后执行for之后的插入语句
// 如果i索引处的Entry为null,表明此处还没有Entry。
modCount++;
// 将key、value添加到i索引处。
addEntry(hash, key, value, i);
return null;通过链表数组的形式被解决了。简单的用图形展示
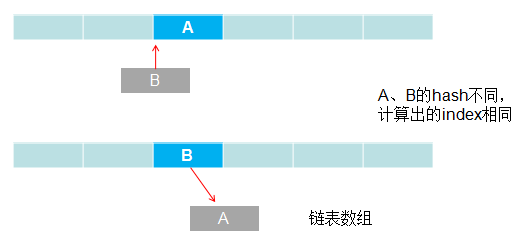
这里HashMap解决hash冲突的方法就是通过链地址法来的。
这里笔者也给出其他的冲突解决方式,有兴趣的朋友可以研究下:
1)开放定址法(线性探测再散列,二次探测再散列,伪随机探测再散列)
2)再哈希法
3)链地址法
4)建立一 公共溢出区
4、读取元素
说完了元素的存储,我们来看看,HashMap是如何来读取元素的吧,这里我们简要的分析
下get(key)方法
public V get(Object key) {
if (key == null)
return getForNullKey();
Entry<K,V> entry = getEntry(key);
return null == entry ? null : entry.getValue();
}接下来进入getEntry(key)方法体里面去。
final Entry<K,V> getEntry(Object key) {
int hash = (key == null) ? 0 : hash(key);
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}values返回的就是空。如若索引位置不为空,该位置下可能是一条链,找到这条链里面可key的
hash相同的key,返回其对应的values。呵呵,取元素的方法是否简单多了呢?
5、删除元素
对于删除元素的原理和上述都是差不多的,这里笔者也就不解析了嘛。
6、HashMap优化
容量调整
对于容量的调整,这个是HashMap较为重点的部分,仔细想想看,对于hashMap我们应该
做的是尽量的避免hash冲突 ,此时对于数组的扩容就应该考虑了。不过一个蛋疼的问题也就
出现了,由于新数组的容量变了,原数组的数据就必须重新计算其再数组中的位置,并放入
这就是resize。同时这也是最消耗性能的地方。
那么在什么情况下对HashMap进行扩容呢?一般当HashMap的元素个事超过数组大小*
*loadFactory的时候,就会进行扩容,而loadFactor就是上文所说的负加载因子。默认值为0.75
例如数组空间为16,当元素超过16*0.75=12的时候就把数组大小扩为2*16=32,然后resize
这是一个非常消耗性能的是,因此如果我们预料到HashMap中元素的个数,这就能够有效的
提高hashMap的性能。
负载因子
为确定何时调整大小,而不是对每个存储桶中的链接列表的深度进行计数,基于hash的
Map使用一个额外的参数并粗略计算存储桶的密度。Map在调整大小之前,使用名为LoadFactory
的参数指示Map将承担的“负载”量,即它的负载程度。loadFactory、map大小、容量之间关系:
如果(负载因子)x(容量)>(Map 大小),则调整 Map 大小
7、快速失败机制和迭代遍历
对于HashMap的迭代,请参考: http://blog.csdn.net/kiritor/article/details/8872565
相关阅读:
Map源码学习 http://blog.csdn.net/kiritor/article/details/8884371
hashCode方法相关 http://blog.csdn.net/kiritor/article/details/8885022















 1511
1511

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









