






1. Python数据分析的工具包
- numpy: (Numerical Python的简称),是高性能科学计算和数据分析的基础包
- pandas:基于Numpy创建的Python包,含有使数据分析工作变得更加简单的高级数据结构和操作工具
- matplotlib:是一个用于创建出版质量图表的绘图包(主要是2D方面)
import pandas as pd #导入pandas
import numpy as np #导入numpy
import matplotlib.pypolt as plt #导入matplotlib2. pandas保存数据到Excel
to_excel() 实例方法:用于将DataFrame保存到Excel
df.to_excel('文件名.xlsx', sheet_name = 'Sheet1') #其中df为DataFrame结构的数据,sheet_name = 'Sheet1'表示将数据保存在Excel表的第一张表中read_excel() 方法:从excel文件中读取数据
pd.read_excel('文件名.xlsx', 'Sheet1', index_col=None, na_values=['NA'])3. pandas保存数据到csv文件
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.randn(6,3)) #创建随机值并保存为DataFrame结构
print(df.head())
df.to_csv('numpppy.csv')实战环节
结合之前学习的获取数据、解析数据的知识,爬取《小王子》豆瓣短评的数据,并把数据保存为本地的excel表格
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Created on Sat Mar 17 17:18:35 2018
@author: Jackie
"""
import requests
from lxml import etree
import pandas as pd
urls = ['https://book.douban.com/subject/1084336/comments/hot?p={}'.format(str(i)) for i in range(1,6)]
comments = []
for url in urls:
r = requests.get(url).text
s = etree.HTML(r)
file = s.xpath('//div[@class="comment"]/p/text()')
comments += file
df = pd.DataFrame(comments)
print(df.head())
#df.to_excel('comment.xlsx')结果:
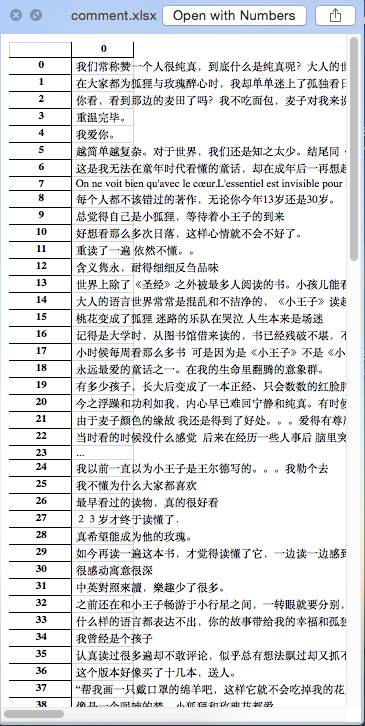














 6888
6888











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









