







Wavesplit:End-to-End Speech Separation by Speaker Clustering
表格总结
文章结构
Abstract
【模型任务】
①采用聚类的方法,对混合信号的各个源都进行基于全序列的特征表示;
②基于表示的特征信号,还原各个原信号;
③将特征表示与信号提取两个子任务模型进行联合训练
【模型优势】
①采用聚类的方法,可以有效避开permutation的问题;
②基于全序列的特征表示,可以让训练出来的算法更加具有鲁棒性;
③可以有效地迁移到其他信号分割的领域。
Intro
①分离信号源的分类
信号源不同类:对提前定义好类别的不同音乐器件的分类;对语音和非语音信号的分类;
信号源同类:对有重叠的语音信号进行分割;从电表中将家用电器用电量分离出来;对重叠的指纹信息进行分割等。
思想:需要设计一个模型,可以在ground-truth和预测信号之间保持一个统一的分布分配——这对于同类信号源分离至关重要。
②open speaker separation
该模型在训练阶段需要利用说话人的信息进行联合训练;
但是在测试阶段除了输入的mixture信号,不需要任何先验信息。
③语音的特征表示
- 训练目标的本质鼓励网络学习每个说话者instantaneous representation,每个特征被聚类分组到某一特定说话者的clustering中;
- 每个clustering的质心为恢复这个信号源提供了一个长期的说话者表示信息;
- 这样的信号表征机制利用了信号的长时相关性,可以有效抑制重建信号过程中的source swap问题。
④工作总结
i. 训练时使用先验,测试时不适用
ii. 针对整个输入的信号对各个信号源进行信息整合
iii. 采用聚类对语音信号的特征进行表示和划分,以集合的形式进行输出避开了顺序性问题
iv. 在当前常用语音分离benchmark中产生SOTA结果
v. 对方法的优缺点进行分析
vi. 通过将这个模型用到母婴心率信号分离的问题中,证明其具有一定泛化性
Related Work
1. Deep Clustering Approaches
【中心思想】
为每个时频单元学习到一种潜在的特征空间表示,基于这些特征表示之间的距离对不同的时频单元进行聚类。
【Deep Attractor Networks】
【Wavesplit】
- 依赖聚类操作去推断各个源的特征表示,但是这些潜在表示并不和频率单元相关联,也不会进行masking操作;
- 它的特征表示被用于——①在训练阶段用于预测说话人身份;②为后续的分离卷积网络提供条件变量。

2. Permutation-Invariant Training
【PIT】
- 通过将预测的各个信号源的组合与ground truth mask进行比对,err最小的那个组合被用于模型的训练;
- 但这样的步骤并没有在预测的信号顺序和标签顺序之间建立本质联系;
- PIT架构中bypass了相位信息
【Wavesplit】
- 也是基于时域的分离方法,它会在信号估计这一步骤之前先对置换问题进行解决:再将信号的latent representation传递给分离网络进行训练之前,先要求各个信号的latent representation要和标签最好地匹配。
3. Discriminative Speaker Representation
【extract with enrollment】
- speaker beam
- speaker attention networks
- speaker extraction networks
【open-set speaker separation】
- 独立地训练一个speaker identification network
- 使用PIT训练网络架构,可以同时考虑已有和未知的说话人
【Wavesplit】
- 在test阶段不需要先验的说话人信息,但是需要对【说话人身份验证】-【信号源分离】这两个步骤联合训练和学习
4. Constrained Settings
讨论了信号分离的一些指标和场景:
- reconstruction quality
- efficiency for online separation
- noisy environment
WaveSplit
1. problem Setting & Notations

2. Model Architecture
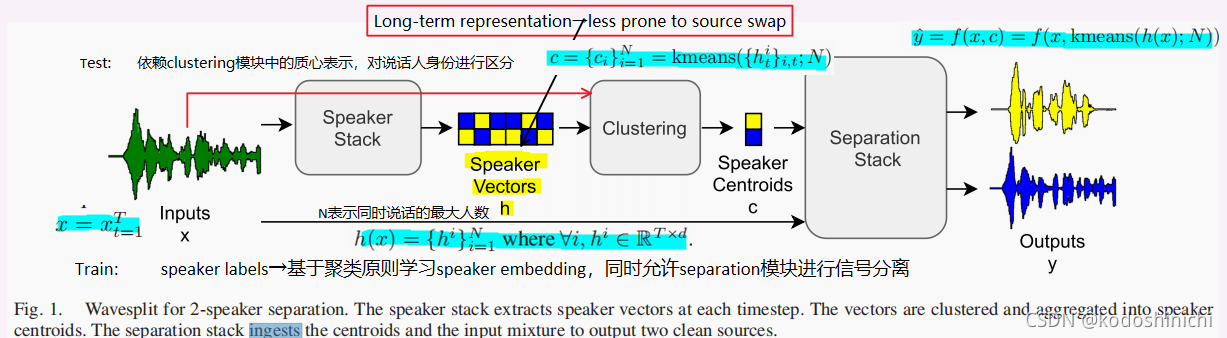
【数据流】
①传进来的混合信号按照T个时间step进行分割,对于每一个time step的语音信号,均针对N个源进行d维表示,因此对于每一个源都能得到RTXd维度的特征表示;
②每一个源在各个time step中的标签并不统一,例如针对源c1,在时间步t时表示成h1第一个特征向量,但是在时间步t’中有可能表示成h2第二个特征向量,这并不会引入额外的permutation问题;
③在聚类步骤中,根据向量之间的相似度衡量,会把属于某一特定源的所有特征表示汇聚在一起,并返回这一个clustering的质心表示。
【网络设计】
speaker stack:残差卷积
separation stack:依赖于FiLM的质心结果的残差计算块
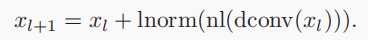
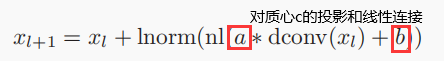
3. Model Training Objective
“In split of a problem belonging to source separation, it uses the speaker identities to build an internal model of each source and improve long-term separation.”
【Speaker vector objective】
【Reconstruction objective】
Wavesplit不同于PIT,不需要在permutation空间进行搜索,因为cluster的质心总是和某一标签的说话人相对应。
















 2274
2274











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









