






好的,我现在需要回答用户的问题:“这里面的256是自己人为规定的吗”。首先,我得仔细看看用户提供的图片内容和描述。
根据用户提供的信息,图片里的代码是在做softmax回归实验,参数部分提到了隐藏单元数量是256。用户之前可能对神经网络的结构不太熟悉,所以想知道这个数字是不是可以自己随便定,还是有其他依据。
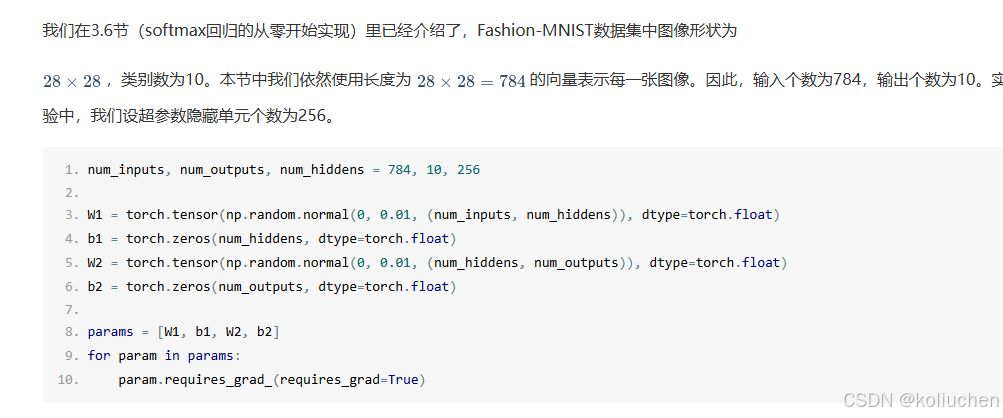
首先,我需要确认用户提到的256确实出现在代码中。用户给出的代码片段里有这一行:“num_hidden = 256”,这说明256是隐藏层的单元数量,属于超参数。超参数通常是模型训练前需要手动设置的,而不是通过数据学习得到的,所以这一点没错。
接下来,用户的问题核心在于这个256是否是人为规定的。答案是肯定的,因为隐藏层单元数是设计神经网络时的一个选择,没有固定的公式或必须遵循的值。不过,虽然可以自由选择,但通常会有一定的经验或最佳实践参考。
然后,我应该考虑用户可能的深层需求。他们可能刚接触深度学习,对于如何选择超参数感到困惑。这时候不仅要回答“是”或“否”,还需要解释为什么可以这样设置,以及有什么注意事项。
可能需要提到,选择隐藏单元数通常需要考虑模型的复杂度和防止过拟合。如果隐藏层太大,模型可能会过于复杂,导致过拟合;太小则可能无法捕捉足够的信息。此外,计算资源也是一个因素,更大的网络需要更多内存和计算时间。
另外,用户提供的代码中有其他参数,比如权重初始化的方法(normal分布,均值0,标准差0.01),这也是常见的做法,有助于模型稳定训练。可能还可以简要说明这些参数的作用,但用户当前的问题主要集中在256这个数值上,所以需要保持重点在这里。
还要注意用户提供的代码是否存在错误,比如变量名是否正确。例如,代码中的“num患病_换了type-torch.float”看起来像是打字错误或OCR识别错误,正确的应该是“num_inputs, num_outputs, num_hidden = 784, 10, 256”。这可能影响理解,但用户的问题主要关于256,所以可能不需要深入纠正代码错误,除非影响答案。
总结来说,回答需要明确以下几点:
1. 256是人为设定的超参数。
2. 超参数需要根据经验、实验和问题需求来调整。
3. 过大或过小都可能有问题,需权衡模型能力和计算资源。
4. 可能提到常见的选择范围,比如在类似任务中256是一个合理的选择,但并非固定。
最后,确保回答简洁易懂,避免使用过多技术术语,让用户能够理解为什么可以自行规定,并且知道如何合理选择。
是的,图片中的 **256** 确实是人为规定的超参数,具体含义如下:
---
### 1. **什么是「隐藏单元数量」?**
• 在神经网络中,隐藏层(Hidden Layer)的单元数量(如代码中的 `num_hidden=256`)决定了该层的抽象能力。
• 它是模型设计者根据任务需求**主动选择**的超参数(Hyperparameter),而非通过数据自动学习的结果。
---
### 2. **为何要手动设定?**
• **灵活性**:不同任务需要不同的模型复杂度。例如:
◦ 简单分类任务可能只需几十个单元(如 `num_hidden=64`)。
◦ 复杂任务(如图像识别)可能需要更多单元(如 `num_hidden=512` 或更高)。
• **控制模型容量**:单元越多,模型记忆能力越强,但可能导致过拟合(记住了训练数据却泛化差)。
• **计算资源限制**:单元越多,计算量和内存消耗越大。
---
### 3. **如何合理选择?**
• **经验法则**:通常从较小值开始(如 64、128),逐步增加并观察效果。
• **参考文献**:模仿已有论文或经典模型的结构(如 Fashion-MNIST 常用 `256` 或 `512`)。
• **实验验证**:通过交叉验证比较不同单元数的性能,选择最优解。
---
### 4. **代码中的其他细节**
• 图片中的代码片段展示了完整的参数定义:
```python
num_inputs, num_outputs, num_hidden = 784, 10, 256 # 输入/输出/隐藏层大小
W1 = torch.tensor(np.random.normal(0, 0.01, (num_inputs, num_hidden)), dtype=torch.float)
b1 = torch.zeros(num_hidden, dtype=torch.float)
W2 = torch.tensor(np.random.normal(0, 0.01, (num_hidden, num_outputs)), dtype=torch.float)
b2 = torch.zeros(num_outputs, dtype=torch.float)
```
• **权重初始化**:使用 `np.random.normal(0, 0.01)` 初始化权重,目的是防止梯度消失/爆炸。
• **梯度跟踪**:`requires_grad=True` 表示参数需要参与反向传播。
---
### 总结
• **256 是人为规定的**,但它并非随意选择,而是基于任务复杂度、计算资源和经验权衡后的结果。
• 如果你想调整模型性能,可以尝试修改 `num_hidden` 的值(如改为 128、512),并通过训练集和验证集的准确率对比效果。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









