







题目描述
请实现两个函数,分别用来序列化和反序列化二叉树。
根据树的前序遍历序列和中序遍历序列可以唯一的构造出一棵二叉树。受此启发,我们可以先把一棵二叉树序列化成一个前序遍历序列和中序遍历序列,然后在反序列化时通过这两个序列重构出原二叉树。
这种思路有两个缺点:一是该方法要求二叉树中不能有重复的节点,二是只有当两个序列中的所有数据都读出后才能开始反序列化。如果两个遍历序列的数据是从一个流里读出来的,那么可能需要等待较长的时间。
实际上,如果二叉树的序列化是从根节点开始的,那么相应的反序列化在根节点的数值读出来的时候就可以开始了。因此,我们可以根据前序遍历的顺序来序列化二叉树,因为前序遍历序列是从根节点开始的。在遍历二叉树碰到null指针时,这些null指针序列化为一个特殊的字符(如‘$’)。另外,节点的数值之间要用一个特殊字符(如‘,’)隔开。
根据这样的序列化规则,下图中的二叉树被序列化成字符串“1,2,4,$,$,$,3,5,$,$,6,$,$”。
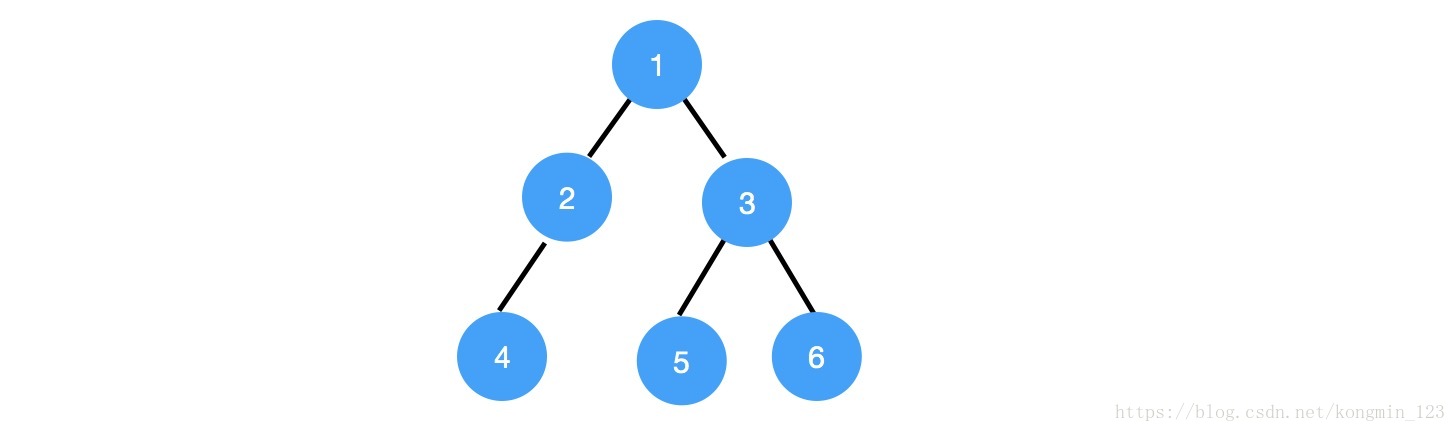
上面的序列化过程可以用递归来实现。
分析完了二叉树的序列化,我们接着以字符串“1,2,4,$,$,$,3,5,$,$,6,$,$”为例分析如何反序列化二叉树。第一个读出的数字是1。由于前序遍历序列是从根节点开始的,这是根节点的值,接下来读出的数字是2,根据前序遍历的规则,这是根节点的左子节点的值。同样,接下来的数字4是值为2的节点的左子节点。接着从序列化字符串里独处两个字符‘$’,这表明值为4的节点的左、右子节点均为null指针,因此它是一个叶节点。接下来回到值为2的节点,重建它的右子节点。由于下一个字符是‘$’,这表明值为2的节点的右子节点为null指针。这个节点的左右子树都已经构建完毕,接下来回到根节点,反序列化根节点的右子树。
下一个序列化字符串中的数字是3,因此右子树的根节点的值是3,它的左子节点的值是一个值为5的叶节点,因此接下来的三个字符是“5,$,$”。同样,它的右子节点是值为6的叶节点,因为最后三个字符是“6,$,$”。
二叉树的序列化和反序列化过程搞清楚了,我们就可以开始动手写代码了。反序列化二叉树同样也是用的递归。
使用递归序列化二叉树为字符串和把字符串反序列化为二叉树的Java代码如下:
public class Solution {
int index = -1; //计数变量
//序列化二叉树
public String Serialize(TreeNode root) {
StringBuilder sb = new StringBuilder();
if(root == null){
sb.append("$,");
return sb.toString();
}
sb.append(root.val + ",");
sb.append(Serialize(root.left));
sb.append(Serialize(root.right));
return sb.toString();
}
//反序列化二叉树
public TreeNode Deserialize(String str) {
index++;
String[] strarr = str.split(",");
TreeNode node = null;
if(!strarr[index].equals("$")){
node = new TreeNode(Integer.valueOf(strarr[index]));
node.left = Deserialize(str);
node.right = Deserialize(str);
}
return node;
}
}
每次从序列化的字符中读出一个数字或者一个字符‘$’。当从字符串中读出的是一个数字时,函数返回true,否则返回false。
如果总结前面序列化和反序列化的过程,就会发现我们都是把二叉树分解成3部分:根节点,左子树和右子树。我们在处理(序列化或反序列化)它的根节点之后再分别处理它的左右子树。这是典型的把问题递归分解然后逐个解决的过程。
序列化和反序列化二叉树的时间复杂度都为O(n)。














 3842
3842











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









