







最近因为测试环境 MSSQL 服务器排序规则区分大小写,导致实用到临时表(tempdb)的数据、临时对象都区分了大小写。所以重建了系统数据库并更改了排序规则,这里再次总结一下。
开始之前,先确认排序规则(或大小写是否敏感)
-
--查看服务器排序规则(安装时指定的排序规则)
-
SELECT SERVERPROPERTY(
'COLLATION')
AS ServerCollation
-
,DATABASEPROPERTYEX(
'tempdb',
'COLLATION')
AS TempdbCollation
-
,DATABASEPROPERTYEX(DB_NAME(),
'COLLATION')
AS CurrentDBCollation
-
--查看数据库排序规则
-
SELECT
name, collation_name
FROM sys.databases
-
-
--当前数据库是否大小写敏感
-
SELECT
CASE
WHEN N
'A'=N
'a'
THEN N
'不敏感'
ELSE N
'敏感'
END
此环境实例中,服务器排序规则为 Chinese_PRC_BIN ,当前数据库排序规则为 Chinese_PRC_CI_AS。若当前数据库创建的所有对象和执行脚本时,如果用到了变量、临时对象等,大小写不一致则出现问题。二进制(_BIN)排序规则是区分大小写的,参考 Windows
Collation Sorting Styles。
安装实例时指定的排序规则,就是 master 数据库的排序规则,同时 model 和 msdb 的排序规则也保持一致,而 tempdb 和用户数据库的排序规则都是参照 model 数据库一样的。系统数据库是不能直接更改排序规则的,因此只能重建系统数据库,且让系统数据库的排序规则都一致。
重建实例排序规则和系统数据库排序规则:
1. 备份系统数据库!必要的,失败了或者以后要使用当前环境时,还可以回退!
2. 记住所有数据库及文件路径,保持到 excel 中。如果记得住所有数据库位置的话就不用了。
select DB_NAME(database_id) as name,physical_name from sys.master_files
3. 导出服务器配置(sp_configure)到 excel。因为重建系统数据库后配置会被初始化。
4. 导出账号信息到 txt。数据库重建,账户信息都会丢失,除了备份也要单独备份账号。(SQL Server 中登录账号与数据库用户迁移)
5. 导出链接服务器生产脚本到 txt ,如果有的话。
6. 导出代理作业到 txt 。
7. (如果还有其他配置,如审核、邮件配置、策略等,都保存出来,后续再重建)
8. 分离所有用户数据库。
-
select
'ALTER DATABASE ['+
name+
'] SET SINGLE_USER WITH ROLLBACK IMMEDIATE'+
char(
10)+
'go'+
char(
10)
-
+
'EXEC master.dbo.sp_detach_db @dbname = N'''+
name+
''''+
char(
10)+
'go'+
char(
10)
-
from sys.databases
where
name
not
in(
'master',
'model',
'msdb',
'tempdb')
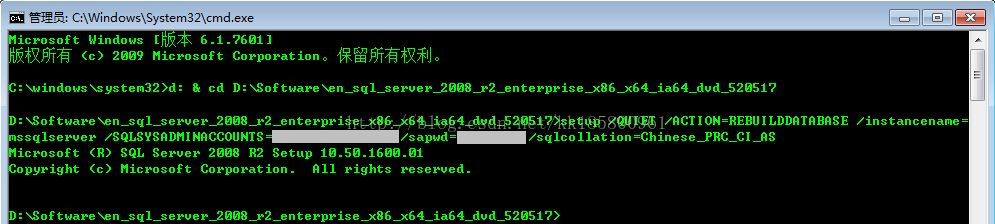
10. 重建数据库并制定新的排序规则。打开命令行,进入安装目录。
cd D:\Software\en_sql_server_2008_r2_enterprise_x86_x64_ia64_dvd_520517
setup /QUIET /ACTION=REBUILDDATABASE /instancename=mssqlserver /SQLSYSADMINACCOUNTS=服务器账号 /sapwd=密码 /sqlcollation=Chinese_PRC_CI_AS
11. 启动 SQL Server 引擎服务,其他暂不启动。
12. 创建登录账户(之前导出的脚本)
13. 附加所有用户数据库。
14. 创建代理作业、链接服务器、更配置等!
完成!~
如果重建系统数据库后,还原 master 数据库,那么服务器排序规则和 master 数据库排序规则都还原和以前一样,所以不能还原,除非恢复到以前的环境。
如果还原 msdb 或 model ,该数据库排序规则也会还原,所以系统数据库备份都不要还原,重建系统数据库之后只能重新配置。
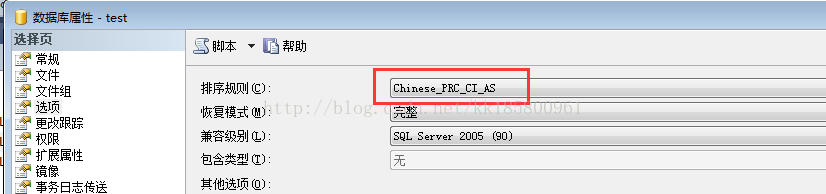
更改用户数据库排序规则:
ALTER DATABASE test COLLATE Chinese_PRC_CI_AS
更改数据库排序规则时,需要更改下列内容:
>> 将系统表中的任何 char、varchar、text、nchar、nvarchar 或 ntext 列更改为使用新的排序规则。
>> 将存储过程和用户定义函数的所有现有 char、varchar、text、nchar、nvarchar 或 ntext 参数和标量返回值更改为使用新的排序规则。
>> 将 char、varchar、text、nchar、nvarchar 或 ntext 系统数据类型和基于这些系统数据类型的所有用户定义的数据类型更改为使用新的默认排序规则。
对于数据库内字段定义的排序规则,参考下面的 设置或更改列排序规则。
设置或更改列排序规则:
-
--示例
-
CREATE
TABLE dbo.MyTable(
-
PrimaryKey
INT PRIMARY
KEY,
-
CharCol
VARCHAR(
10)
COLLATE French_CI_AS
NOT
NULL
-
);
-
GO
-
ALTER
TABLE dbo.MyTable
ALTER
COLUMN CharCol
VARCHAR(
10)
COLLATE Latin1_General_CI_AS
NOT
NULL;
-
GO
如果下列其中之一当前正在引用一个列,则无法更改该列的排序规则:
>> 计算列
>> 索引
>> 自动生成或由 CREATE STATISTICS 语句生成的分发统计信息
>> CHECK 约束
>> FOREIGN KEY 约束














 459
459











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









