






静态
由于静态变量是属于类的,只需要通过类名就可以调用:类名.静态变量
实例变量是属于对象的,需要通过对象才能调用:对象.实例变量
- 1.类变量:属于类,在内存中只有一份,用类名调用
- 2.实例变量:属于对象,每一个对象都有一份,用对象调用
有static修饰的方法,是属于类的,称为类方法;调用时直接用类名调用即可。
无static修饰的方法,是属于对象的,称为实例方法;调用时,需要使用对象调用。
内存原理
1.类方法:static修饰的方法,可以被类名调用,是因为它是随着类的加载而加载的;
所以类名直接就可以找到static修饰的方法
2.实例方法:非static修饰的方法,需要创建对象后才能调用,是因为实例方法中可能会访问实 例变量,而实例变量需要创建对象后才存在。
所以实例方法,必须创建对象后才能调用。
工具类
如果一个类中的方法全都是静态的,那么这个类中的方法就全都可以被类名直接调用,由于调用起来非常方便,就像一个工具一下,所以把这样的类就叫做工具类。
注意

代码块
代码块根据有无static修饰分为两种:静态代码块、实例代码块
静态代码块,随着类的加载而执行,而且只执行一次。
实例代码块每次创建对象之前都会执行一次
继承
Java语言只支持单继承,不支持多继承,但是可以多层继承
子类中访问构造器的特点
执行顺序,如下图按照① ② ③ 步骤执行

如果不想使用默认的super()方式调用父类构造器,还可以手动使用super(参数)调用父类有参数构造器。

抽象
- 抽象类是不能创建对象的,如果抽象类的对象就会报错
- 抽象类虽然不能创建对象,但是它可以作为父类让子类继承。而且子类继承父类必须重写父类的所有抽象方法
- 子类继承父类如果不复写父类的抽象方法,要想不出错,这个子类也必须是抽象类
1.用抽象类可以把父类中相同的代码,包括方法声明都抽取到父类,这样能更好的支持多态,一提高代码的灵活性。
2.反过来用,我们不知道系统未来具体的业务实现时,我们可以先定义抽象类,将来让子类去实现,以方便系统的扩展。
设计模式
设计模式是解决某一类问题的最优方案。
模板方法模式主要解决方法中存在重复代码的问题
模板方法模式解决了多个子类中有相同代码的问题
第1步:定义一个抽象类,把子类中相同的代码写成一个模板方法。
第2步:把模板方法中不能确定的代码写成抽象方法,并在模板方法中调用。
第3步:子类继承抽象类,只需要父类抽象方法就可以了。
接口
- 接口是用来被类实现(implements)的,我们称之为实现类。
- 一个类是可以实现多个接口的(接口可以理解成干爹),类实现接口必须重写所有接口的全部抽象方法,否则这个类也必须是抽象类
好处
- 弥补了类单继承的不足,一个类同时可以实现多个接口。
- 让程序可以面向接口编程,这样程序员可以灵活方便的切换各种业务实现。
接口JDK8的新特性
public interface A {
/**
* 1、默认方法:必须使用default修饰,默认会被public修饰
* 实例方法:对象的方法,必须使用实现类的对象来访问。
*/
default void test1(){
System.out.println("===默认方法==");
test2();
}
/**
* 2、私有方法:必须使用private修饰。(JDK 9开始才支持的)
* 实例方法:对象的方法。
*/
private void test2(){
System.out.println("===私有方法==");
}
/**
* 3、静态方法:必须使用static修饰,默认会被public修饰
*/
static void test3(){
System.out.println("==静态方法==");
}
void test4();
void test5();
default void test6(){
}
}其他细节
- 一个接口可以继承多个接口,接口同时也可以被类实现。
内部类
成员内部类
创建对象
//外部类.内部类 变量名 = new 外部类().new 内部类();
Outer.Inner in = new Outer().new Inner();
//调用内部类的方法
in.test();静态内部类
其实就是在成员内部类的前面加了一个static关键字
创建对象
//格式:外部类.内部类 变量名 = new 外部类.内部类();
Outer.Inner in = new Outer.Inner();
in.test();匿名内部类
匿名内部类本质上是一个没有名字的子类对象、或者接口的实现类对象。
匿名内部类在编写代码时没有名字,编译后系统会为自动为匿名内部类生产字节码,字节码的名称会以外部类$1.class的方法命名
匿名内部类的作用:简化了创建子类对象、实现类对象的书写格式。
只有在调用方法时,当方法的形参是一个接口或者抽象类,为了简化代码书写,而直接传递匿名内部类对象给方法。
枚举
每一个枚举项都是被public static final修饰,所以被可以类名调用,而且不能更改。
枚举一般表示几个固定的值,然后作为参数进行传输。
泛型
下图中在返回值类型和修饰符之间有<T>定义的才是泛型方法。

public class Test{
public static void main(String[] args){
//调用test方法,传递字符串数据,那么test方法的泛型就是String类型
String rs = test("test");
//调用test方法,传递Dog对象,那么test方法的泛型就是Dog类型
Dog d = test(new Dog());
}
//这是一个泛型方法<T>表示一个不确定的数据类型,由调用者确定
public static <T> test(T t){
return t;
}
}泛型限定
- <?> 表示任意类型
- <? extends 数据类型> 表示指定类型或者指定类型的子类
- <? super 数据类型> 表示指定类型或者指定类型的父类
泛型擦除
也就是说泛型只能编译阶段有效,一旦编译成字节码,字节码中是不包含泛型的。
自定义异常
- 先写一个异常类AgeIllegalException(这是自己取的名字,名字取得很奈斯),继承Exception
- 就抛出一个AgeIllegalException异常对象给调用者。

1.如果自定义异常类继承Excpetion,则是编译时异常。
特点:方法中抛出的是编译时异常,必须在方法上使用throws声明,强制调用者处理。
2.如果自定义异常类继承RuntimeException,则运行时异常。
特点:方法中抛出的是运行时异常,不需要在方法上用throws声明。
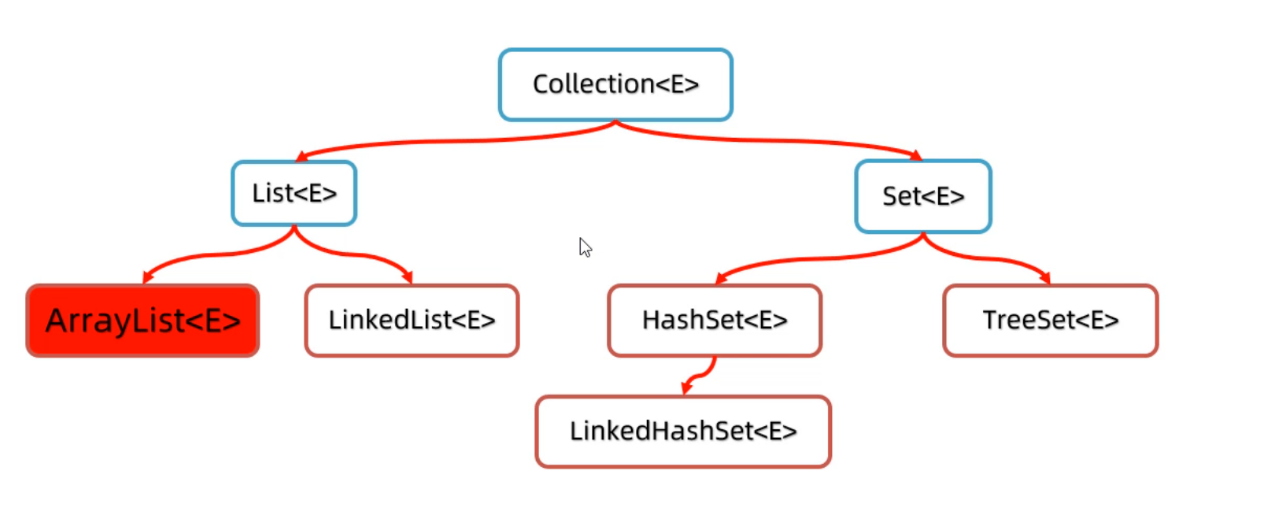
集合-collection
ArrayList底层的原理
ArrayList集合底层是基于数组结构实现的,也就是说当你往集合容器中存储元素时,底层本质上是往数组中存储元素。

数组扩容,并不是在原数组上扩容(原数组是不可以扩容的),底层是创建一个新数组,然后把原数组中的元素全部复制到新数组中去。
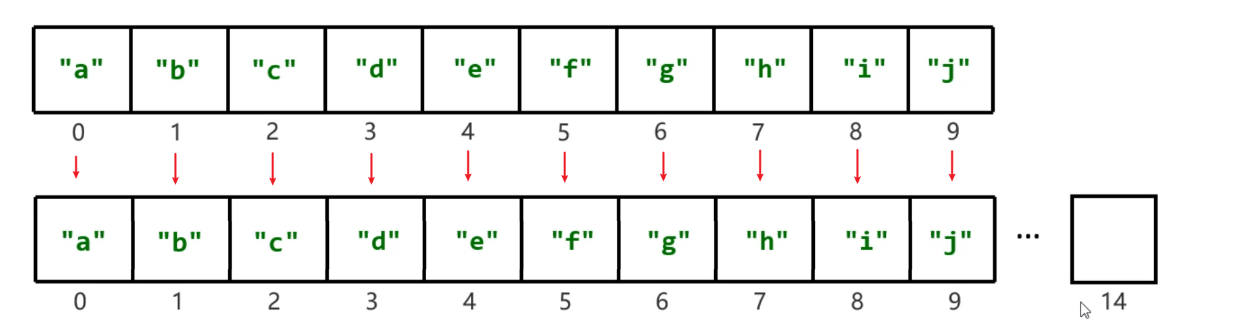
LinkedList底层原理
LinkedList底层是链表结构,链表结构是由一个一个的节点组成,一个节点由数据值、下一个元素的地址组成
LinkedList集合是基于双向链表实现了
应用(栈和队)
//1.创建一个栈对象
LinkedList<String> stack = new ArrayList<>();
//压栈(push) 等价于 addFirst()
stack.push("第1颗子弹");
stack.push("第2颗子弹");
stack.push("第3颗子弹");
stack.push("第4颗子弹");
System.out.println(stack); //[第4颗子弹, 第3颗子弹, 第2颗子弹,第1颗子弹]
//弹栈(pop) 等价于 removeFirst()
System.out.println(statck.pop()); //第4颗子弹
System.out.println(statck.pop()); //第3颗子弹
System.out.println(statck.pop()); //第2颗子弹
System.out.println(statck.pop()); //第1颗子弹
//弹栈完了,集合中就没有元素了
System.out.println(list); //[]
//1.创建一个队列:先进先出、后进后出
LinkedList<String> queue = new LinkedList<>();
//入对列
queue.addLast("第1号人");
queue.addLast("第2号人");
queue.addLast("第3号人");
queue.addLast("第4号人");
System.out.println(queue);
//出队列
System.out.println(queue.removeFirst()); //第4号人
System.out.println(queue.removeFirst()); //第3号人
System.out.println(queue.removeFirst()); //第2号人
System.out.println(queue.removeFirst()); //第1号人HashSet集合底层原理
HashSet集合底层是基于哈希表实现的,哈希表根据JDK版本的不同,也是有点区别的
- JDK8以前:哈希表 = 数组+链表
- JDK8以后:哈希表 = 数组+链表+红黑树
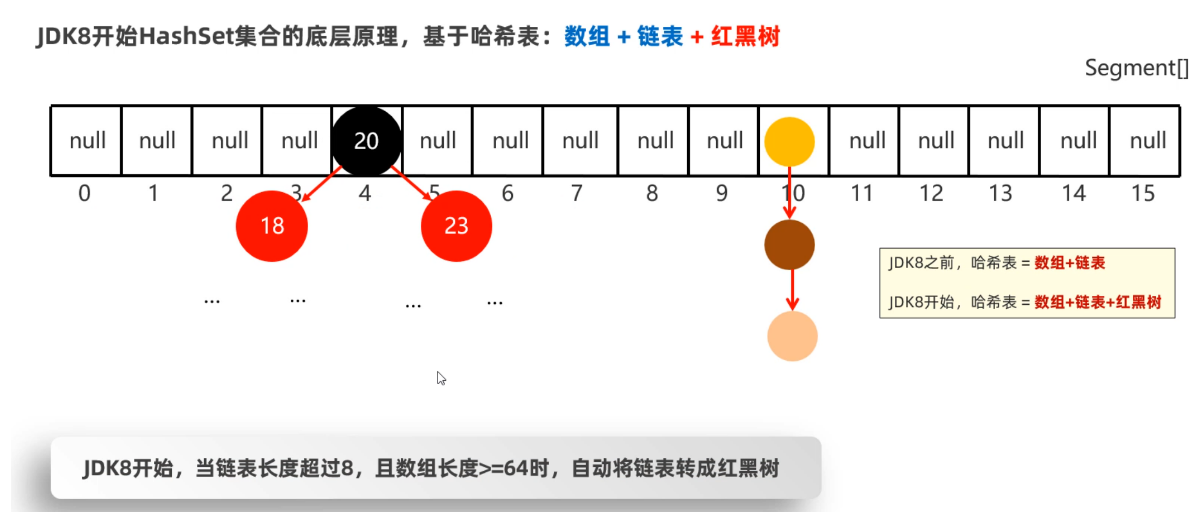
我们发现往HashSet集合中存储元素时,底层调用了元素的两个方法:一个是hashCode方法获取元素的hashCode值(哈希值);另一个是调用了元素的equals方法,用来比较新添加的元素和集合中已有的元素是否相同。
- 只有新添加元素的hashCode值和集合中以后元素的hashCode值相同、新添加的元素调用equals方法和集合中已有元素比较结果为true, 才认为元素重复。
- 如果hashCode值相同,equals比较不同,则以链表的形式连接在数组的同一个索引为位置(如上图所示)
HashSet去重原理
要想保证在HashSet集合中没有重复元素,我们需要重写元素类的hashCode和equals方法。
//按快捷键生成hashCode和equals方法
//alt+insert 选择 hashCode and equals
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
if (age != student.age) return false;
if (Double.compare(student.height, height) != 0) return false;
return name != null ? name.equals(student.name) : student.name == null;
}
@Override
public int hashCode() {
int result;
long temp;
result = name != null ? name.hashCode() : 0;
result = 31 * result + age;
temp = Double.doubleToLongBits(height);
result = 31 * result + (int) (temp ^ (temp >>> 32));
return result;
}
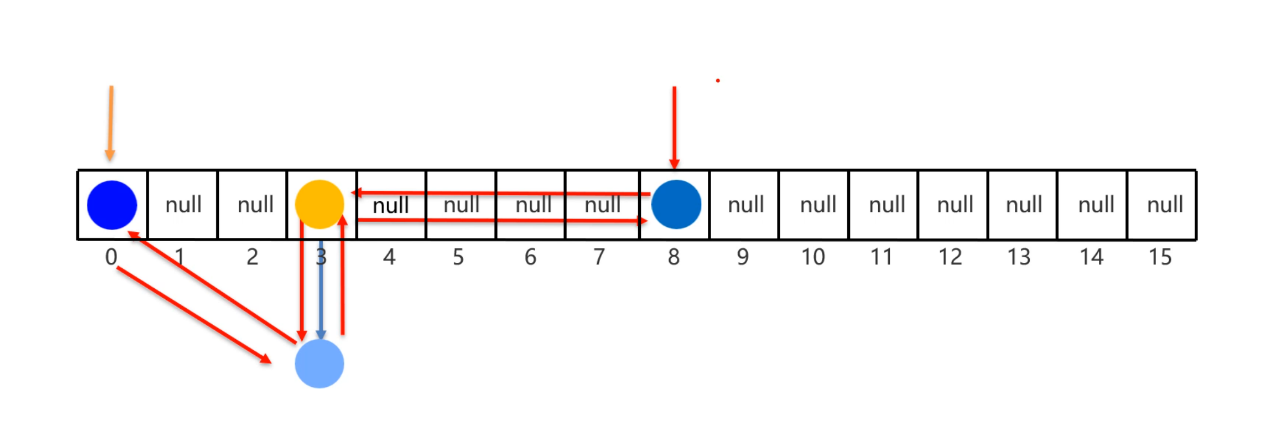
}LinkedHashSet底层原理
LinkedHashSet它底层采用的是也是哈希表结构,只不过额外新增了一个双向链表来维护元素的存取顺序。
可变参数
- 可变参数是一种特殊的形式参数,定义在方法、构造器的形参列表处,它可以让方法接收多个同类型的实际参数。
- 可变参数在方法内部,本质上是一个数组
public class ParamTest{
public static void main(String[] args){
//不传递参数,下面的nums长度则为0, 打印元素是[]
test();
//传递3个参数,下面的nums长度为3,打印元素是[10, 20, 30]
test(10,20,30);
//传递一个数组,下面数组长度为4,打印元素是[10,20,30,40]
int[] arr = new int[]{10,20,30,40}
test(arr);
}
public static void test(int...nums){
//可变参数在方法内部,本质上是一个数组
System.out.println(nums.length);
System.out.println(Arrays.toString(nums));
System.out.println("----------------");
}
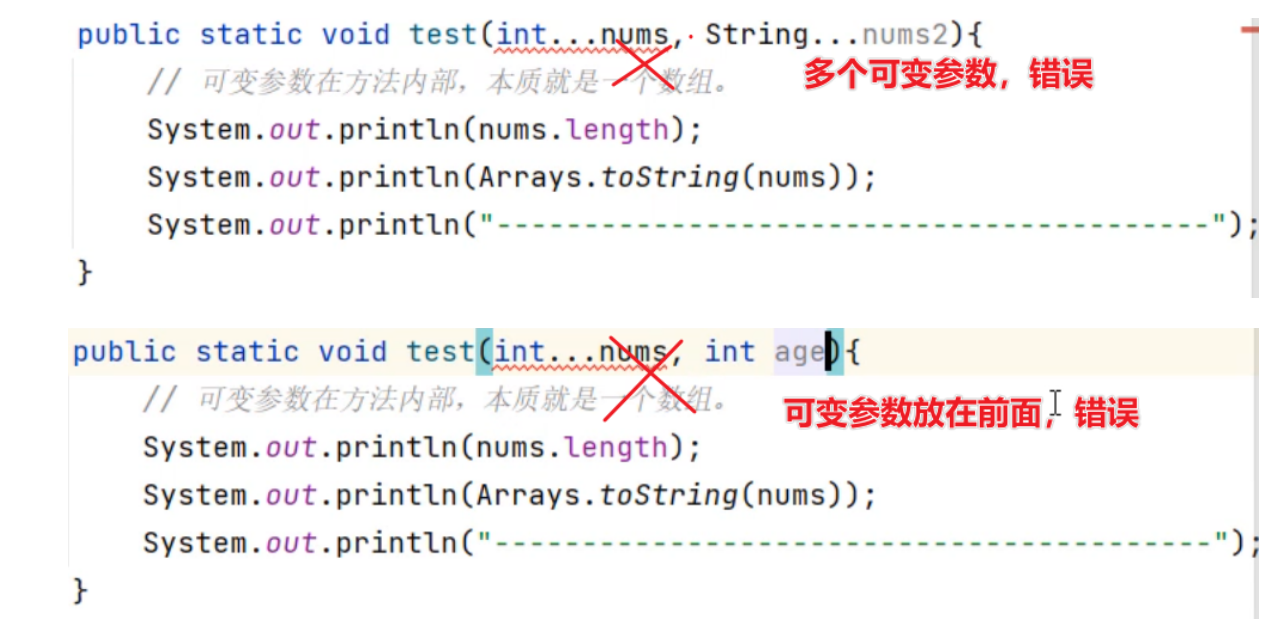
}- 一个形参列表中,只能有一个可变参数;否则会报错
- 一个形参列表中如果多个参数,可变参数需要写在最后;否则会报错
Map集合

遍历方式

/**
* 目标:掌握Map集合的第二种遍历方式:键值对。
*/
public class MapTest2 {
public static void main(String[] args) {
Map<String, Double> map = new HashMap<>();
map.put("蜘蛛精", 169.8);
map.put("紫霞", 165.8);
map.put("至尊宝", 169.5);
map.put("牛魔王", 183.6);
System.out.println(map);
// map = {蜘蛛精=169.8, 牛魔王=183.6, 至尊宝=169.5, 紫霞=165.8}
// entries = [(蜘蛛精=169.8), (牛魔王=183.6), (至尊宝=169.5), (紫霞=165.8)]
// entry = (蜘蛛精=169.8)
// entry = (牛魔王=183.6)
// ...
// 1、调用Map集合提供entrySet方法,把Map集合转换成键值对类型的Set集合
Set<Map.Entry<String, Double>> entries = map.entrySet();
for (Map.Entry<String, Double> entry : entries) {
String key = entry.getKey();
double value = entry.getValue();
System.out.println(key + "---->" + value);
}
}
}jdk1.8后最简单的遍历方式
/**
* 目标:掌握Map集合的第二种遍历方式:键值对。
*/
public class MapTest3 {
public static void main(String[] args) {
Map<String, Double> map = new HashMap<>();
map.put("蜘蛛精", 169.8);
map.put("紫霞", 165.8);
map.put("至尊宝", 169.5);
map.put("牛魔王", 183.6);
System.out.println(map);
// map = {蜘蛛精=169.8, 牛魔王=183.6, 至尊宝=169.5, 紫霞=165.8}
//遍历map集合,传递匿名内部类
map.forEach(new BiConsumer<String, Double>() {
@Override
public void accept(String k, Double v) {
System.out.println(k + "---->" + v);
}
});
//遍历map集合,传递Lambda表达式
map.forEach(( k, v) -> {
System.out.println(k + "---->" + v);
});
}
}字符集
GBK
- 如果是存储字母,采用1个字节来存储,一共8位,其中第1位是0
- 如果是存储汉字,采用2个字节来存储,一共16位,其中第1位是1
当读取文件中的字符时,通过识别读取到的第1位是0还是1来判断是字母还是汉字
Unicode
对Unicode字符集中的字符进行了重新编码,一共设计了三种编码方案。分别是UTF-32、UTF-16、UTF-8; 其中比较常用的编码方案是UTF-8
1.UTF-8是一种可变长的编码方案,工分为4个长度区
2.英文字母、数字占1个字节兼容(ASCII编码)
3.汉字字符占3个字节
4.极少数字符占4个字节
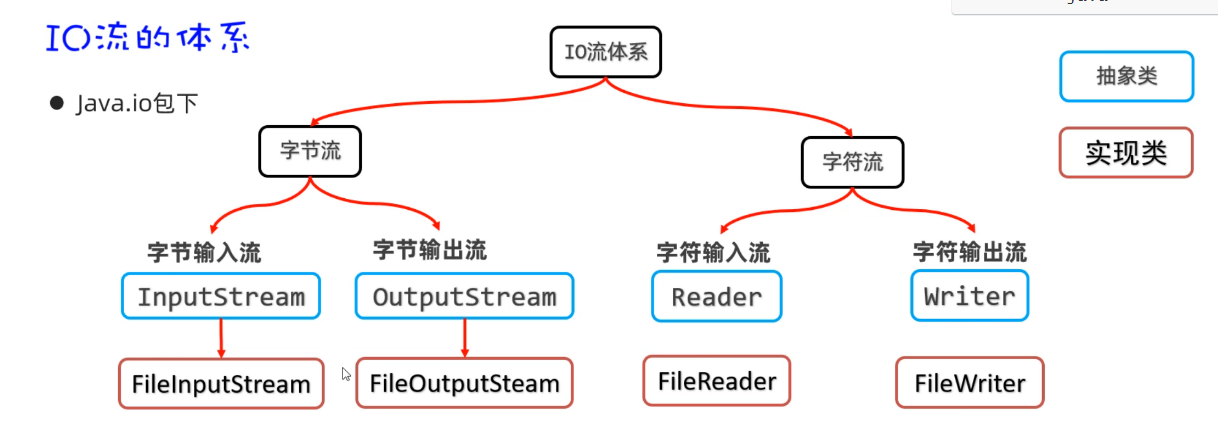
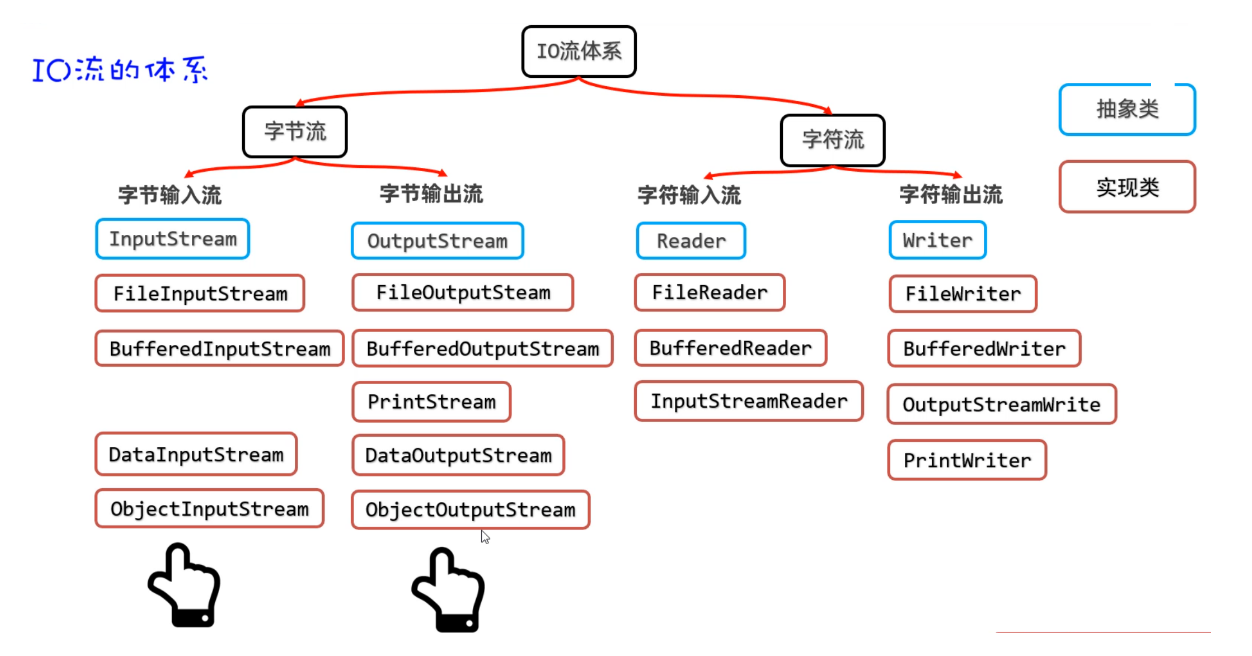
IO流
序列化流
序列化
必须让其实现Serializable接口。
public class Test1ObjectOutputStream {
public static void main(String[] args) {
try (
// 2、创建一个对象字节输出流包装原始的字节 输出流。
ObjectOutputStream oos =
new ObjectOutputStream(new FileOutputStream("io-app2/src/itheima11out.txt"));
){
// 1、创建一个Java对象。
User u = new User("admin", "张三", 32, "666888xyz");
// 3、序列化对象到文件中去
oos.writeObject(u);
System.out.println("序列化对象成功!!");
} catch (Exception e) {
e.printStackTrace();
}
}
}反序列化
public class Test2ObjectInputStream {
public static void main(String[] args) {
try (
// 1、创建一个对象字节输入流管道,包装 低级的字节输入流与源文件接通
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("io-app2/src/itheima11out.txt"));
){
User u = (User) ois.readObject();
System.out.println(u);
} catch (Exception e) {
e.printStackTrace();
}
}
}特殊文件
- 后缀为.properties的文件,称之为属性文件,它可以很方便的存储一些类似于键值对的数据。经常当做软件的配置文件使用。
- 而xml文件能够表示更加复杂的数据关系,比如要表示多个用户的用户名、密码、家乡、性别等。在后面,也经常当做软件的配置文件使用。
Properties属性文件
- 属性文件后缀以
.properties结尾 - 属性文件里面的每一行都是一个键值对,键和值中间用=隔开。比如:
admin=123456 #表示这样是注释信息,是用来解释这一行配置是什么意思。- 每一行末尾不要习惯性加分号,以及空格等字符;不然会把分号,空格会当做值的一部分。
- 键不能重复,值可以重复
读取属性文件中的数据--Properties。
1.Properties是什么?
Properties是Map接口下面的一个实现类,所以Properties也是一种双列集合,用来存储键值对。 但是一般不会把它当做集合来使用。
2.Properties核心作用?
Properties类的对象,用来表示属性文件,可以用来读取属性文件中的键值对。
实用Properties读取属性文件的步骤如下
1、创建一个Properties的对象出来(键值对集合,空容器)
2、调用load(字符输入流/字节输入流)方法,开始加载属性文件中的键值对数据到properties对象中去
3、调用getProperty(键)方法,根据键取值
XML文件
- XML中的`<标签名>` 称为一个标签或者一个元素,一般是成对出现的。
- XML中的标签名可以自己定义(可扩展),但是必须要正确的嵌套
- XML中只能有一个根标签。
- XML标准中可以有属性
- XML必须第一行有一个文档声明,格式是固定的`<?xml version="1.0" encoding="UTF-8"?>`
- XML文件必须是以.xml为后缀结尾
XML解析
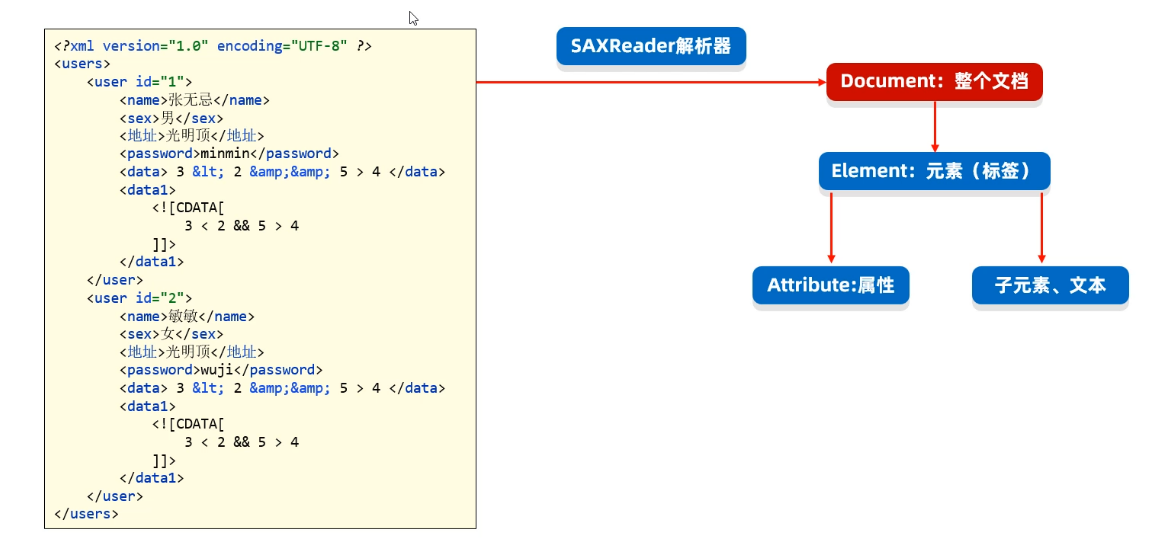
XML解析框架,最知名的是DOM4J(第三方开发的)
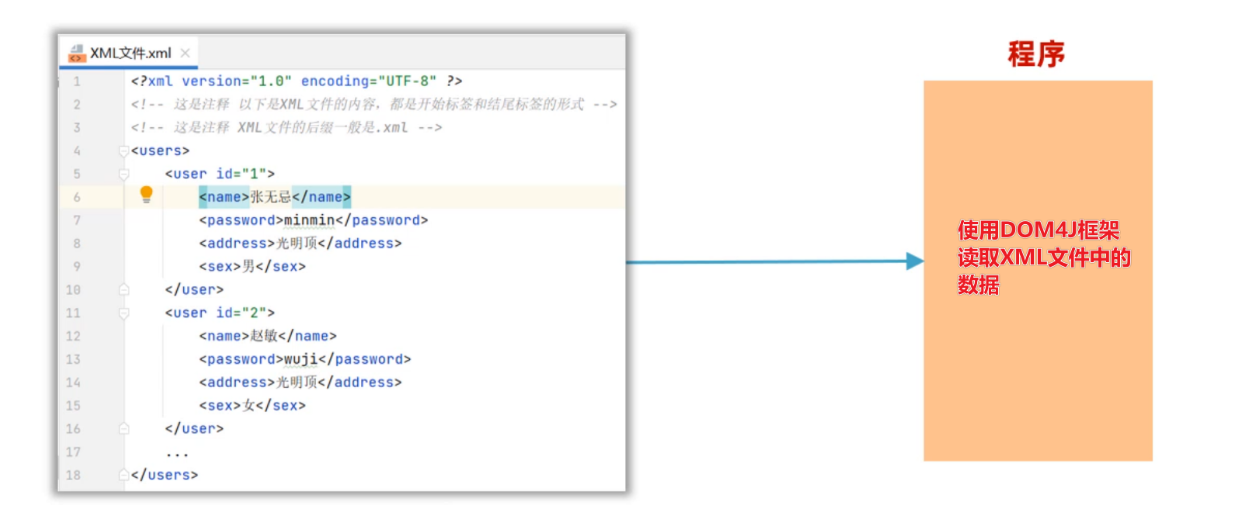

DOM4J解析XML文件的思想是:文档对象模型(意思是把整个XML文档、每一个标签、每一个属性都等都当做对象来看待)。Dowument对象表示真个XML文档、Element对象表示标签(元素)、Attribute对象表示属性、标签中的内容就是文本
public class Dom4JTest1 {
public static void main(String[] args) throws Exception {
// 1、创建一个Dom4J框架提供的解析器对象
SAXReader saxReader = new SAXReader();
// 2、使用saxReader对象把需要解析的XML文件读成一个Document对象。
Document document =
saxReader.read("properties-xml-log-app\\src\\helloworld.xml");
// 3、从文档对象中解析XML文件的全部数据了
Element root = document.getRootElement();
System.out.println(root.getName());
}
}日志


开始记录

public class LogBackTest {
// 创建一个Logger日志对象
public static final Logger LOGGER = LoggerFactory.getLogger("LogBackTest");
public static void main(String[] args) {
//while (true) {
try {
LOGGER.info("chu法方法开始执行~~~");
chu(10, 0);
LOGGER.info("chu法方法执行成功~~~");
} catch (Exception e) {
LOGGER.error("chu法方法执行失败了,出现了bug~~~");
}
//}
}
public static void chu(int a, int b){
LOGGER.debug("参数a:" + a);
LOGGER.debug("参数b:" + b);
int c = a / b;
LOGGER.info("结果是:" + c);
}
}
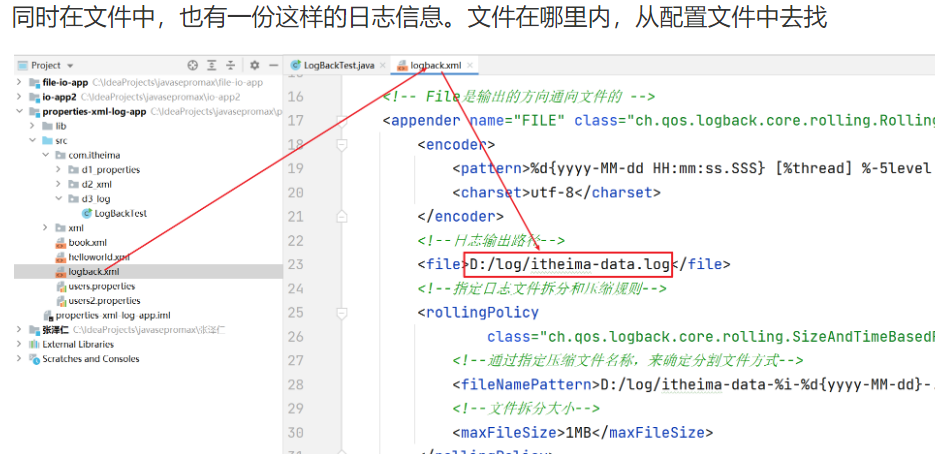
日志配置文件
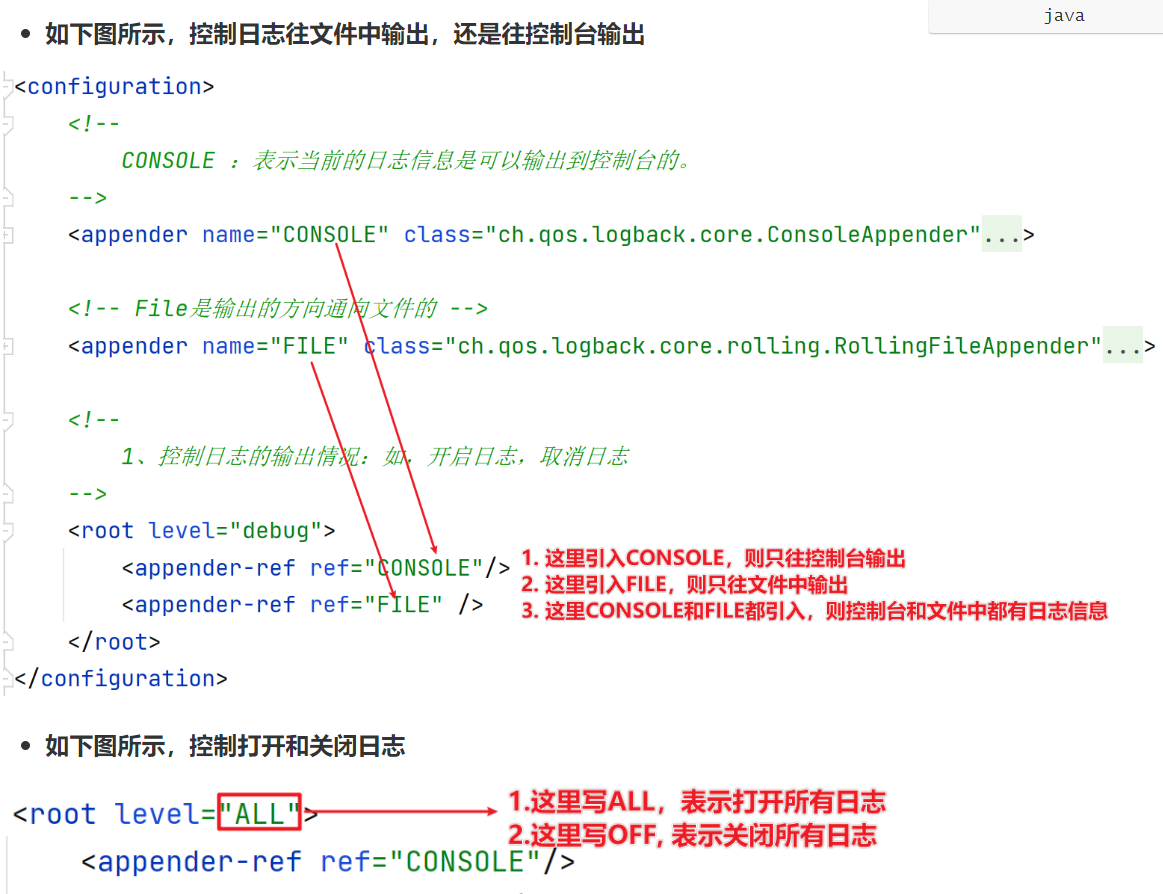
- 可以配置日志输出的位置是文件、还是控制台
- 可以配置日志输出的格式
- 还可以配置日志关闭和开启、以及哪些日志输出哪些日志不输出。
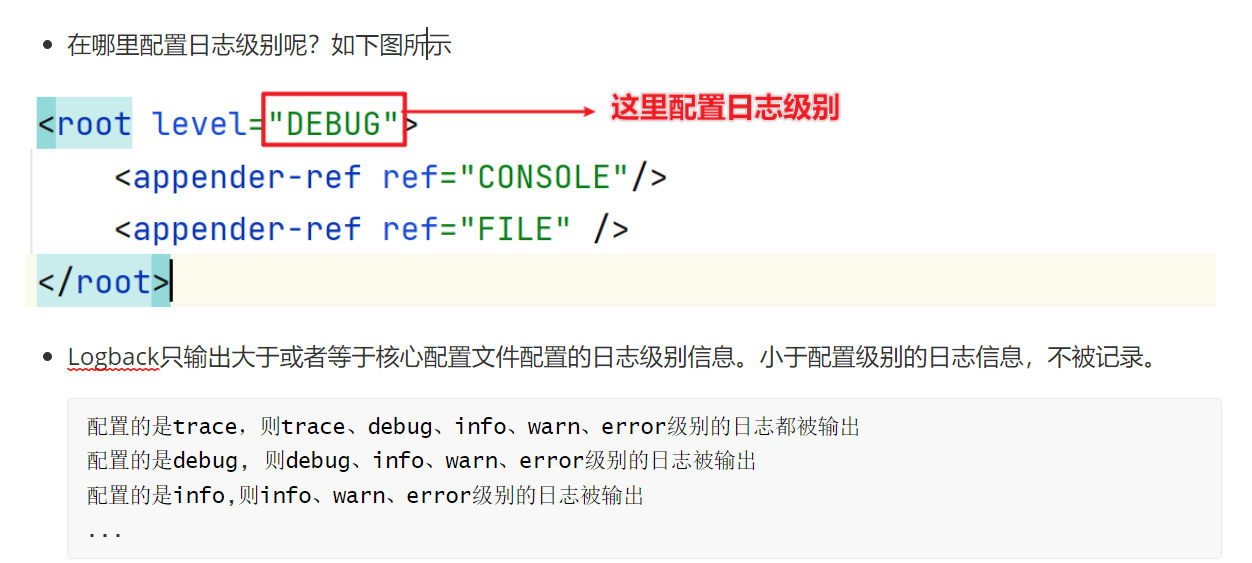
配置日志级别

多线程
线程其实是程序中的一条执行路径。
线程创建1
1.定义一个子类继承Thread类,并重写run方法
2.创建Thread的子类对象
3.调用start方法启动线程(启动线程后,会自动执行run方法中的代码)
public class MyThread extends Thread{
// 2、必须重写Thread类的run方法
@Override
public void run() {
// 描述线程的执行任务。
for (int i = 1; i <= 5; i++) {
System.out.println("子线程MyThread输出:" + i);
}
}
}
public class ThreadTest1 {
// main方法是由一条默认的主线程负责执行。
public static void main(String[] args) {
// 3、创建MyThread线程类的对象代表一个线程
Thread t = new MyThread();
// 4、启动线程(自动执行run方法的)
t.start();
for (int i = 1; i <= 5; i++) {
System.out.println("主线程main输出:" + i);
}
}
}线程创建2
1.先写一个Runnable接口的实现类,重写run方法(这里面就是线程要执行的代码)
2.再创建一个Runnable实现类的对象
3.创建一个Thread对象,把Runnable实现类的对象传递给Thread
4.调用Thread对象的start()方法启动线程(启动后会自动执行Runnable里面的run方法)
/**
* 1、定义一个任务类,实现Runnable接口
*/
public class MyRunnable implements Runnable{
// 2、重写runnable的run方法
@Override
public void run() {
// 线程要执行的任务。
for (int i = 1; i <= 5; i++) {
System.out.println("子线程输出 ===》" + i);
}
}
}
public class ThreadTest2 {
public static void main(String[] args) {
// 3、创建任务对象。
Runnable target = new MyRunnable();
// 4、把任务对象交给一个线程对象处理。
// public Thread(Runnable target)
new Thread(target).start();
for (int i = 1; i <= 5; i++) {
System.out.println("主线程main输出 ===》" + i);
}
}
}
//简化
public class ThreadTest2_2 {
public static void main(String[] args) {
// 1、直接创建Runnable接口的匿名内部类形式(任务对象)
Runnable target = new Runnable() {
@Override
public void run() {
for (int i = 1; i <= 5; i++) {
System.out.println("子线程1输出:" + i);
}
}
};
new Thread(target).start();
// 简化形式1:
new Thread(new Runnable() {
@Override
public void run() {
for (int i = 1; i <= 5; i++) {
System.out.println("子线程2输出:" + i);
}
}
}).start();
// 简化形式2:
new Thread(() -> {
for (int i = 1; i <= 5; i++) {
System.out.println("子线程3输出:" + i);
}
}).start();
for (int i = 1; i <= 5; i++) {
System.out.println("主线程main输出:" + i);
}
}
}线程创建3
返回值
在Callable接口中有一个call方法,重写call方法就是线程要执行的代码,它是有返回值的
1.先定义一个Callable接口的实现类,重写call方法
2.创建Callable实现类的对象
3.创建FutureTask类的对象,将Callable对象传递给FutureTask
4.创建Thread对象,将Future对象传递给Thread
5.调用Thread的start()方法启动线程(启动后会自动执行call方法)
等call()方法执行完之后,会自动将返回值结果封装到FutrueTask对象中
6.调用FutrueTask对的get()方法获取返回结果
public class ThreadTest3 {
public static void main(String[] args) throws Exception {
// 3、创建一个Callable的对象
Callable<String> call = new MyCallable(100);
// 4、把Callable的对象封装成一个FutureTask对象(任务对象)
// 未来任务对象的作用?
// 1、是一个任务对象,实现了Runnable对象.
// 2、可以在线程执行完毕之后,用未来任务对象调用get方法获取线程执行完毕后的结果。
FutureTask<String> f1 = new FutureTask<>(call);
// 5、把任务对象交给一个Thread对象
new Thread(f1).start();
Callable<String> call2 = new MyCallable(200);
FutureTask<String> f2 = new FutureTask<>(call2);
new Thread(f2).start();
// 6、获取线程执行完毕后返回的结果。
// 注意:如果执行到这儿,假如上面的线程还没有执行完毕
// 这里的代码会暂停,等待上面线程执行完毕后才会获取结果。
String rs = f1.get();
System.out.println(rs);
String rs2 = f2.get();
System.out.println(rs2);
}
}线程同步方案
同步最常见的方案就是加锁,意思是每次只允许一个线程加锁,加锁后才能进入访问,访问完毕后自动释放锁,然后其他线程才能再加锁进来。
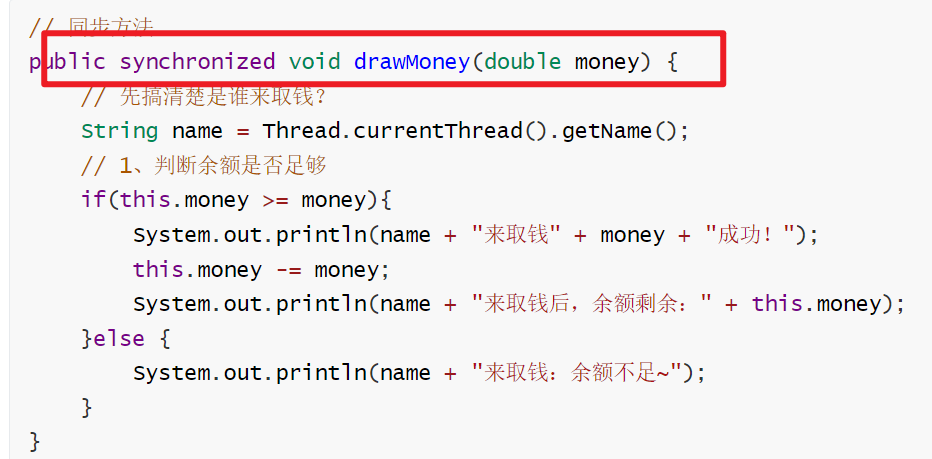
同步方法
其实同步方法,就是把整个方法给锁住,一个线程调用这个方法,另一个线程调用的时候就执行不了,只有等上一个线程调用结束,下一个线程调用才能继续执行。
在方法前加上:synchronized
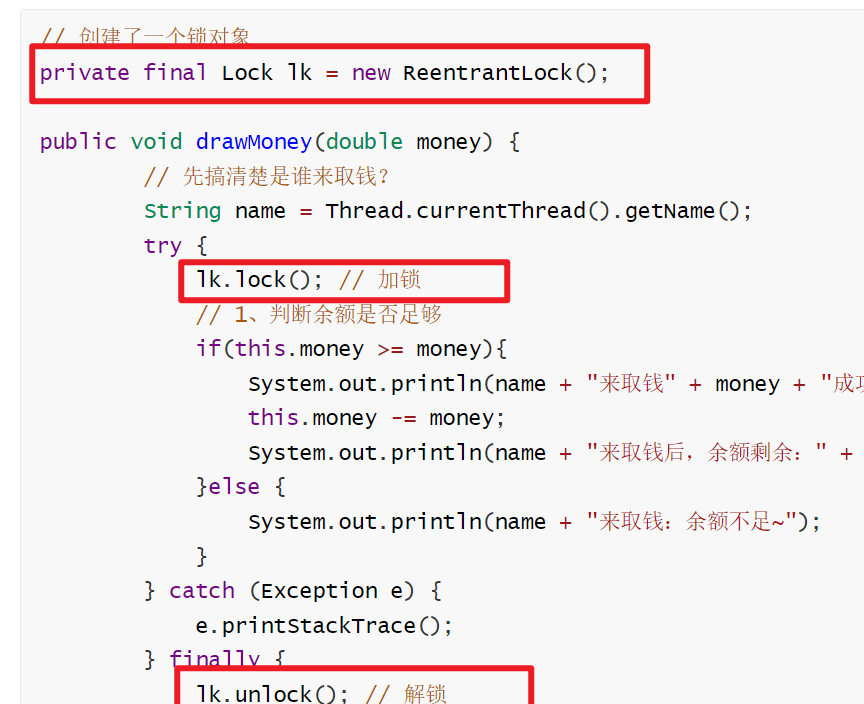
Lock锁
1.首先在成员变量位子,需要创建一个Lock接口的实现类对象(这个对象就是锁对象)
private final Lock lk = new ReentrantLock();
2.在需要上锁的地方加入下面的代码
lk.lock(); // 加锁
//...中间是被锁住的代码...
lk.unlock(); // 解锁
线程池
线程池就是一个可以复用线程的技术。

ExecutorService pool = new ThreadPoolExecutor(
3, //核心线程数有3个
5, //最大线程数有5个。 临时线程数=最大线程数-核心线程数=5-3=2
8, //临时线程存活的时间8秒。 意思是临时线程8秒没有任务执行,就会被销毁掉。
TimeUnit.SECONDS,//时间单位(秒)
new ArrayBlockingQueue<>(4), //任务阻塞队列,没有来得及执行的任务在,任务队列中等待
Executors.defaultThreadFactory(), //用于创建线程的工厂对象
new ThreadPoolExecutor.CallerRunsPolicy() //拒绝策略
);
//执行Runnable任务
Runnable target = new MyRunnable();
pool.execute(target); // 线程池会自动创建一个新线程,自动处理这个任务,自动执行的!
pool.execute(target); // 线程池会自动创建一个新线程,自动处理这个任务,自动执行的!
pool.execute(target); // 线程池会自动创建一个新线程,自动处理这个任务,自动执行的!
//下面4个任务在任务队列里排队
pool.execute(target);
pool.execute(target);
pool.execute(target);
pool.execute(target);
//下面2个任务,会被临时线程的创建时机了
pool.execute(target);
pool.execute(target);
// 到了新任务的拒绝时机了!
pool.execute(target);
// 执行Callable任务
// 2、使用线程处理Callable任务。
Future<String> f1 = pool.submit(new MyCallable(100));
Future<String> f2 = pool.submit(new MyCallable(200));
Future<String> f3 = pool.submit(new MyCallable(300));
Future<String> f4 = pool.submit(new MyCallable(400));
// 3、执行完Callable任务后,需要获取返回结果。
System.out.println(f1.get());
System.out.println(f2.get());
System.out.println(f3.get());
System.out.println(f4.get());线程池工具类
Executors
// 1、通过Executors创建一个线程池对象。
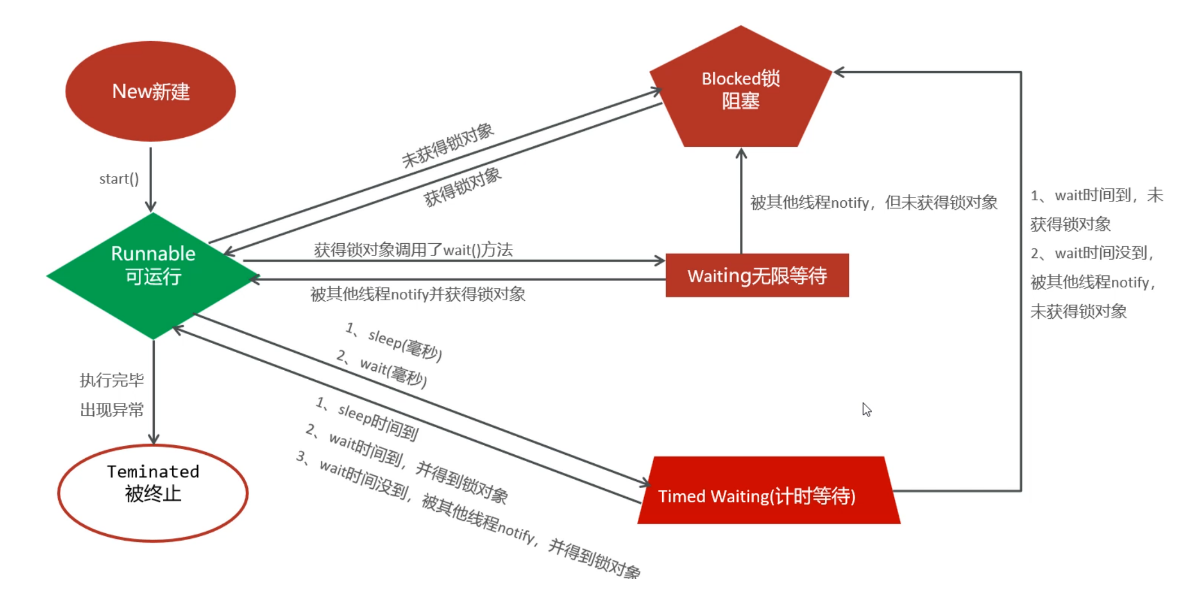
ExecutorService pool = Executors.newFixedThreadPool(17);生命周期















 1385
1385

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









