







比较屌丝,看电影经常用百度云网盘,所以写个脚本方便查看。
保持脚本为
baidu.py,然后python baidu.py -h查看帮助。-p:指定第几页;-k:关键词把符合的电影最后生成Html文件然后浏览(文件位置自己再修改下或者改成动态的吧)。
设置alias:
alias baidu="python baidu.py",然后 在命令行中 执行baidu -p 1 -k 2016脚本地址:https://github.com/kute/purepythontest/blob/master/test/get_film_from_baidu.py
脚本:
#! /usr/bin/env python
# -*- coding: utf-8 -*-
# __author__ = 'kute'
# __mtime__ = '16/10/22 17:49'
"""
关键词 过滤 查看 百度网盘的高清电影
太懒了我
"""
import argparse
import requests
from bs4 import BeautifulSoup
import dominate
from dominate.tags import meta, div, table, tr, td, a
import webbrowser
class GetFilm(object):
def __init__(self, page=1, keyword="2016"):
self.page = page or 1
self.keyword = keyword
self.baiduurl = "http://www.baiduyun.me/forum.php?mod=forumdisplay&fid=99&page={}"
self.baidufile = "/Users/kute/Desktop/baidu.html"
def request(self):
print("========1. Curent page is {} and the keyword is {}.========".format(self.page, self.keyword))
res = requests.get(self.baiduurl.format(self.page))
parse = BeautifulSoup(res.text, "html.parser")
tbodylist = parse.select("tbody[id^='normalthread']")
filmlist = []
for tbody in tbodylist:
parse2 = BeautifulSoup(str(tbody.tr.th), "html.parser")
a = parse2.select_one("a[class='s xst']")
if self.keyword:
if a.string.find(self.keyword) != -1:
filmlist.append((a["href"], a.string))
else:
filmlist.append((a["href"], a.string))
print("========2. Finish scrapy the page and begin generate the html:{}.========".format(self.baidufile))
self.generate_html(filmlist)
def generate_html(self, filmlist):
doc = dominate.document(title='Dominate your HTML')
with doc.head:
meta({"http-equiv": "Content-Type", "content": "text/html; charset=UTF-8"})
with doc:
with div():
with table():
for url, text in filmlist:
with tr():
with td():
a(text, href=url, target="_blank")
with open(self.baidufile, "w") as f:
f.write(doc.render())
print("========3. All finished, have a look please.========")
webbrowser.open("file://{}".format(self.baidufile), new=0, autoraise=True)
def main():
parse = argparse.ArgumentParser(description="Generate films file")
parse.add_argument("-k", "--keyword", help="the film year you want to see, default 2016")
parse.add_argument("-p", "--page", help="next page loop, default 1")
args = parse.parse_args()
g = GetFilm(args.page, args.keyword)
g.request()
if __name__ == '__main__':
main()
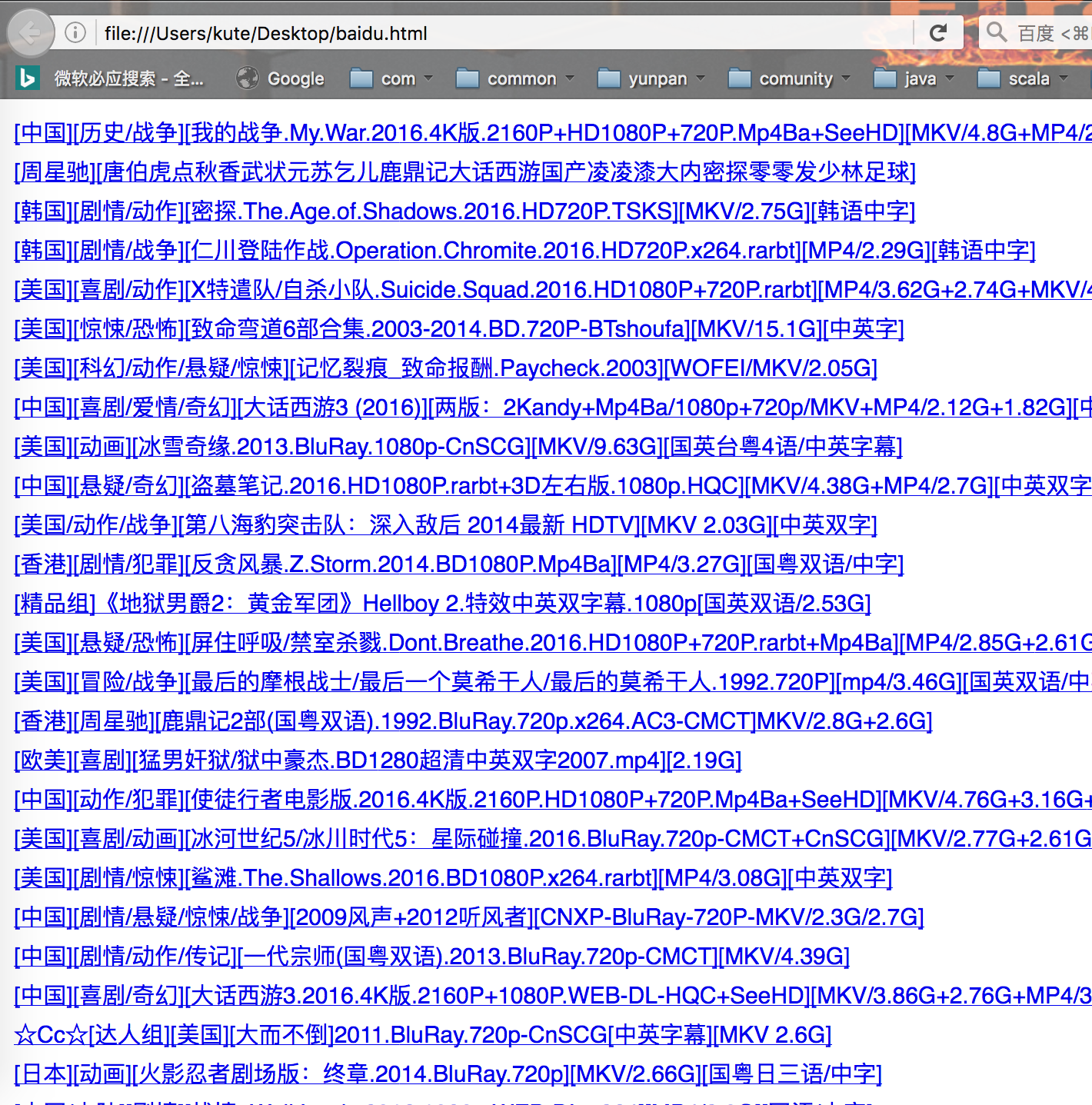
- 效果:















 1395
1395

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









