







转载请注明出处:https://blog.csdn.net/l1028386804/article/details/80865796
1. 什么是 Scala Actor
1.1.概念
Scala 中的 Actor 能够实现并行编程的强大功能,它是基于事件模型的并发机制, Scala 是运用消息(message)的发送、接收来实现多线程的。使用 Scala 能够更容易地实现多线程应用的开发。
1.2.传统 java 并发编程与 Scala Actor 编程的区别
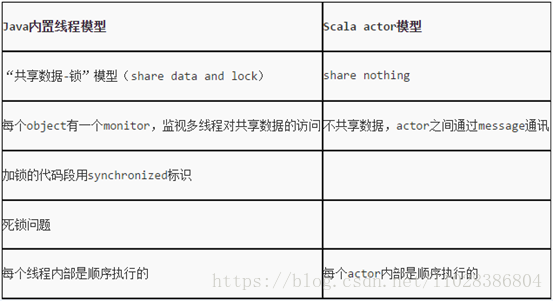
对于Java,我们都知道它的多线程实现需要对共享资源(变量、对象等)使用synchronized 关键字进行代码块同步、对象锁互斥等等。而且,常常一大块的try…catch语句块中加上wait方法、notify方法、notifyAll方法是让人很头疼的。原因就在于Java中多数使用的是可变状态的对象资源,对这些资源进行共享来实现多线程编程的话,控制好资源竞争与防止对象状态被意外修改是非常重要的,而对象状态的不变性也是较难以保证的。而在Scala中,我们可以通过复制不可变状态的资源(即对象,Scala中一切都是对象,连函数、方法也是)的一个副本,再基于Actor的消息发送、接收机制进行并行编程
1.3. Actor 方法执行顺序
- 1.首先调用 start()方法启动 Actor
- 2.调用 start()方法后其 act()方法会被执行
- 3.向 Actor 发送消息
1.4.发送消息的方式
! | 发送异步消息,没有返回值。 |
!? | 发送同步消息,等待返回值。 |
!! | 发送异步消息,返回值是 Future[Any]。 |
2. Actor 实战
2.1 Actor实现多线程开发
package com.lyz.scala
import scala.actors.Actor
/**
* Scala线程实例1
* @author liuyazhuang
*
*/
object MyActor1 extends Actor{
override
def act(){
for(i <- 1 to 10){
println("actor-1" + i)
Thread.sleep(2000)
}
}
}
object MyActor2 extends Actor{
override
def act(){
for(i <- 1 to 10){
println("actor-2" + i)
Thread.sleep(2000)
}
}
}
object ActorTest extends App{
MyActor1.start()
MyActor2.start()
}注意 :这两个 Actor 是并行执行的, act()方法中的 for 循环执行完成后 actor 程序就退出了
2.2 不断接收消息
package com.lyz.scala
import scala.actors.Actor
/**
* 不断的接收消息
* @author liuyazhuang
*
*/
class MyActorMessage extends Actor{
override def act(): Unit = {
while (true) {
receive{
case "start" => {
println("starting...")
Thread.sleep(5000)
println("started")
}
case "stop" => {
println("stopping...")
Thread.sleep(5000)
println("stopped")
}
}
}
}
}
object MyActor{
def main(args: Array[String]) {
var actor = new MyActorMessage
actor.start();
actor ! "start"
actor ! "stop"
println("消息发送完成")
}
}注意 :发送 start 消息和 stop 的消息是异步的,但是 Actor 接收到消息执行的过程是同步的按顺序执行
2.3 react方式
package com.lyz.scala
import scala.actors.Actor
/**
* react 方式会复用线程,比 receive 更高效
* @author liuyazhuang
*
*/
class MyActorReact extends Actor{
override def act() : Unit = {
loop{
react{
case "start" => {
println("starting...")
Thread.sleep(2000)
println("started");
}
case "stop" => {
println("stopping...")
Thread.sleep(2000)
println("stopped")
}
}
}
}
}
object MyReact{
def main(args: Array[String]) {
var react = new MyActorReact
react.start()
react ! "start"
react ! "stop"
println("消息发送完成")
}
}说明: react 如果要反复执行消息处理, react 外层要用 loop,不能用 while
2.4 结合case class发送消息
package com.lyz.scala
import scala.actors.Actor
/**
* 结合case calss发送消息
* @author liuyazhuang
*
*/
class AppleActor extends Actor{
override def act():Unit= {
while (true) {
receive{
case "start" => println("startting...")
case SyncMsg(id, msg) => {
println(id + " sync " + msg)
Thread.sleep(2000)
sender ! ReplyMsg(3, "finished")
}
case AsyncMsg(id, msg) => {
println(id + " async " + msg)
Thread.sleep(2000)
}
}
}
}
}
object AppleActor{
def main(args: Array[String]) {
var a = new AppleActor
a.start()
//异步消息
a ! AsyncMsg(1, "hello actor")
println("发送异步消息完成")
//同步消息
var reply = a !! SyncMsg(2, "hello actor")
println(reply.isSet)
var c = reply.apply()
println(reply.isSet)
println(c)
}
}
case class SyncMsg(id : Int, msg : String)
case class AsyncMsg(id : Int, msg : String)
case class ReplyMsg(id : Int, msg : String)3、案例
用 actor 并发编程写一个单机版的 WorldCount,将多个文件作为输入,计算完成后将多个任务汇总,得到最终的结果
package com.lyz.scala
import scala.actors.{Actor, Future}
import scala.collection.mutable
import scala.io.Source
import java.io.File
import javax.swing.text.MutableAttributeSet
/**
* 用 actor 并发编程写一个单机版的 WorldCount,将多个文件作为输入,计算完成后将多个任
务汇总,得到最终的结果
* @author liuyazhuang
*
*/
class Task extends Actor{
override def act() : Unit = {
loop{
react{
case SubmitTask(fileName) => {
val contents = Source.fromFile(new File(fileName)).mkString
val arr = contents.split("\r\n")
val result = arr.flatMap(_.split(" ")).map((_, 1)).groupBy(_._1).mapValues(_.length)
sender ! ResultTask(result)
}
case StopTask => {
exit()
}
}
}
}
}
object WordCount{
def main(args: Array[String]) {
val files = Array("d:/words.txt ", "d:/words.log")
val replySet = new mutable.HashSet[Future[Any]]
val resultList = new mutable.ListBuffer[ResultTask]
for(f <- files){
val t = new Task
val reply = t.start() !! SubmitTask(f)
replySet += reply
}
while (replySet.size > 0) {
val toCompute = replySet.filter(_.isSet)
for(r <- toCompute){
val result = r.apply()
resultList += result.asInstanceOf[ResultTask]
replySet.remove(r)
}
Thread.sleep(100)
}
val finalResult = resultList.map(_.result).flatten.groupBy(_._1).mapValues(x => x.foldLeft(0)(_ + _._2))
println(finalResult)
}
}
case class SubmitTask(fileName : String)
case object StopTask
case class ResultTask(result : Map[String, Int])














 670
670











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











